
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 불순도제거
- count
- 데이터분석가
- 단순회귀 분석
- 히스토그램 그리기
- if문 작성법
- Dense_Rank
- 데이터분석
- Sum
- loop 문
- 빅데이터분석
- 순위출력
- 회귀분석
- 빅데이터
- max
- sql
- 정보획득량
- 회귀분석 알고리즘
- %in%
- 그래프 생성 문법
- merge
- sqld
- 팀스파르타
- Intersect
- difftime
- 막대그래프
- 총과 카드만들기
- 상관관계
- 여러 데이터 검색
- 그래프시각화
Archives
- Today
- Total
ch0nny_log
[빅데이터분석] R _ 71. k-foldout 본문

** training data → validation data(모의고사 문제) / test data(수능 문제)
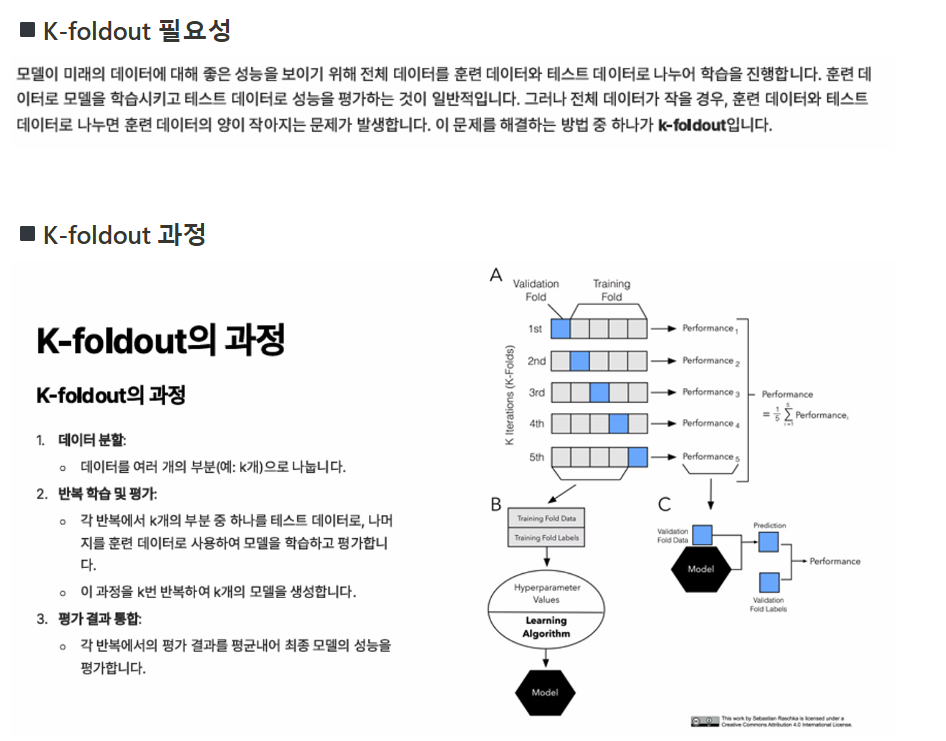
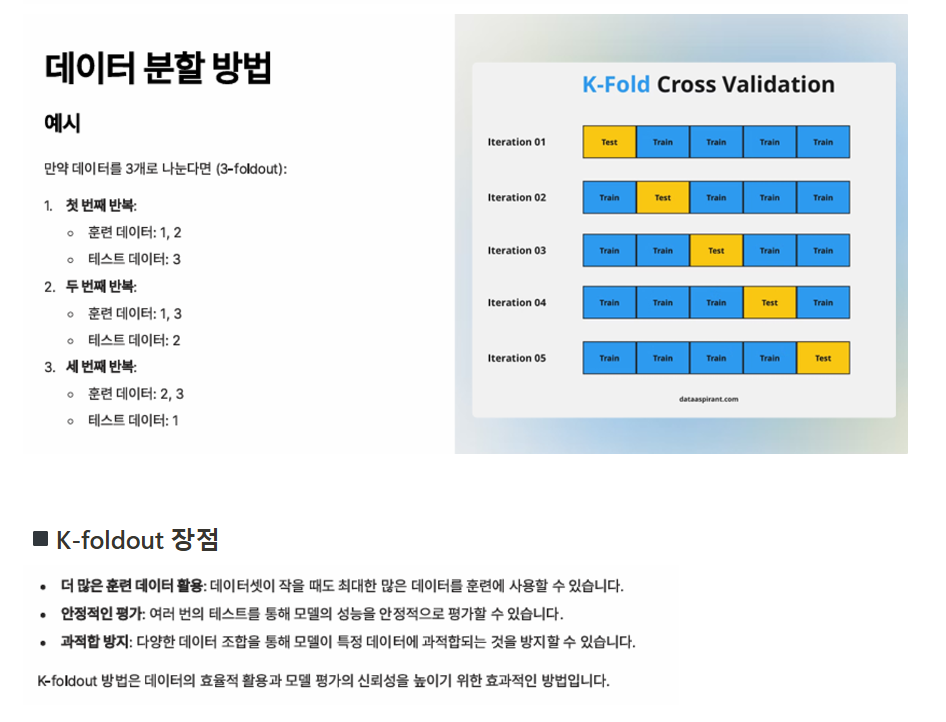
◾K-foldout 실습
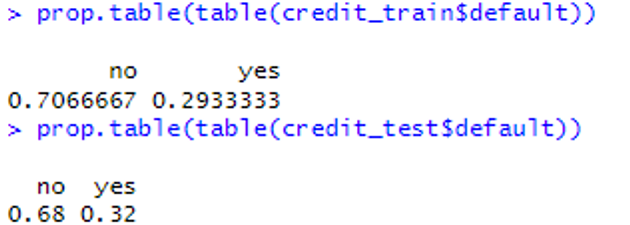
📌 실습. runif 함수를 이용한 데이터 분할 1. 데이터 로드 credit <- read.csv("c:\\data\\credit.csv") nrow(credit) 2. runif 함수를 이용하여 데이터 분할 set.seed(10) random_ids <- order(runif(1000)) # 난수를 1000개 생성 credit_train <- credit[random_ids[1:750], ] # 훈련 데이터 75% credit_test <- credit[random_ids[751:1000], ] # 테스트 데이터 25% nrow(credit_train) # 750 nrow(credit_test) # 250 3. 데이터 비율 확인 table(credit$default) prop.table(table(credit_train$default)) prop.table(table(credit_test$default))
실습. createDataPartition 함수를 이용한 데이터 분할
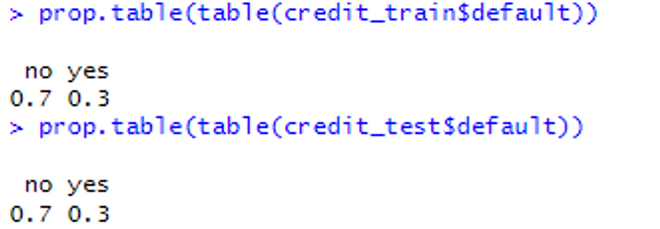
1. 데이터 로드 credit <- read.csv("c:\\data\\credit.csv") nrow(credit) 2. createDataPartition 함수를 이용하여 데이터 분할 library(caret) in_train <- createDataPartition(credit$default, p=0.75, list=FALSE) credit_train <- credit[in_train, ] credit_test <- credit[-in_train, ] nrow(credit_train) # 750 nrow(credit_test) # 250 3. 데이터 비율 확인 prop.table(table(credit_train$default)) prop.table(table(credit_test$default))
⇒ runif 로 훈련과 테스트 데이터를 분할하는 것보다 createDataPartition 을 이용해서 데이터를 분할하는것이 더 정답을 비율에 맞춰서 잘 분할해주는 것을 알 수 있음.

실습. k-폴드 교차검증예제: 10-폴드 교차검증
1. 데이터 로드 credit <- read.csv("c:\\data\\credit.csv", stringsAsFactors=TRUE) 2. 10-폴드 교차검증을 위한 폴드 생성 folds <- createFolds(credit$default, k=10) str(folds) 3. 1번 폴드를 검정 데이터로 사용하고 나머지를 훈련 데이터로 사용 credit01_test <- credit[folds$Fold01, ] credit01_train <- credit[-folds$Fold01, ] nrow(credit01_test) # 100 nrow(credit01_train) # 900 4. 10개의 폴드를 교차검증하여 카파 지수 출력 library(caret) library(C50) # 의사결정트리 모델 만들기 위해서 불러오기 #install.packages('irr') library(irr) # createFolds 를 사용해서 반복적으로 모델 생성하기 위해서 불러오기 credit <- read.csv("c:\\data\\credit.csv", stringsAsFactors=TRUE) folds <- createFolds(credit$default, k=10) cv_results <- lapply(folds, function(x) { credit_train <- credit[-x, ] credit_test <- credit[x, ] credit_model <- C5.0(default ~ ., data=credit_train) credit_pred <- predict(credit_model, credit_test) credit_actual <- credit_test$default kappa <- kappa2(data.frame(credit_actual, credit_pred))$value return (kappa) }) str(cv_results) mean(unlist(cv_results)) # 카파 지수의 평균값 5. trials=100 설정으로 카파 지수 평균값 출력 cv_results <- lapply(folds, function(x) { credit_train <- credit[-x, ] credit_test <- credit[x, ] credit_model <- C5.0(default ~ ., data=credit_train, trials=100) credit_pred <- predict(credit_model, credit_test) credit_actual <- credit_test$default kappa <- kappa2(data.frame(credit_actual, credit_pred))$value return (kappa) }) mean(unlist(cv_results)) # 0.3346655 -> 카파 지수의 평균값 6. 정확도 평균값 출력 (trials=1) cv_results <- lapply(folds, function(x) { credit_train <- credit[-x, ] credit_test <- credit[x, ] credit_model <- C5.0(default ~ ., data=credit_train) credit_pred <- predict(credit_model, credit_test) credit_actual <- credit_test$default accuracy <- sum(credit_actual == credit_pred) / length(credit_actual) return (accuracy) }) mean(unlist(cv_results)) # 정확도의 평균값 7. 정확도 평균값 출력 (trials=100) cv_results <- lapply(folds, function(x) { credit_train <- credit[-x, ] credit_test <- credit[x, ] credit_model <- C5.0(default ~ ., data=credit_train, trials=100) credit_pred <- predict(credit_model, credit_test) credit_actual <- credit_test$default accuracy <- sum(credit_actual == credit_pred) / length(credit_actual) return (accuracy) }) mean(unlist(cv_results)) # 정확도의 평균값

문제. 방금 수행한 trials=100 으로 수행하여 정확도를 확인하는 코드를 iris 의 품종을 분류하는 코드로 변경해서 10-fold 교차검증을 하고 평균 정확도를 출력하시오.
library(caret) library(C50) library(irr) iris <- read.csv('c:\\data\\iris2.csv', stringsAsFactors = TRUE) set.seed(1) folds <- createFolds(iris$Species, k = 10) credit01_test <- iris[folds$Fold01, ] credit01_train <- iris[-folds$Fold01, ] nrow(credit01_test) # 100 nrow(credit01_train) # 900 cv_results <- lapply(folds, function(x) { iris_train <- iris[-x, ] iris_test <- iris[x, ] iris_model <- C5.0(Species ~ ., data=iris_train, trials = 100) iris_pred <- predict(iris_model, iris_test) iris_actual <- iris_test$Species accuracy <- sum(iris_actual == iris_pred) / length(iris_actual) return(accuracy) }) mean(unlist(cv_results)) # 0.94 -> 카파 지수의 평균값

◾교차검증 용어 정리
- 홀드아웃
- 학습 데이터: 모델 훈련 시에 사용하는 데이터
- 검증 데이터: 학습 데이터로 만든 모델의 성능을 평가할 때 사용하는 데이터(훈련 데이터의 일부를 검증 데이터로 사용)
- 평가용 데이터: 테스트 데이터
- k-fold Cross validatation: 데이터를 k 개 나눠서 그 중 1개를 테스트 데이터로 사용하고 나머지를 훈련 데이터로 사용해서 모델의 성능을 확인
'빅데이터 분석(with 아이티윌) > R' 카테고리의 다른 글
| [빅데이터분석] R _ 73. 랜덤 포레스트 (0) | 2024.07.30 |
|---|---|
| [빅데이터분석] R _ 72. 앙상블 (0) | 2024.07.30 |
| [빅데이터분석] R _ 70. ROC 커브와 cut-off (0) | 2024.07.30 |
| [빅데이터분석] R _ 69. 모델 평가 (1) | 2024.07.26 |
| [빅데이터분석] R _ 68. K-means 알고리즘 (0) | 2024.07.26 |
'빅데이터 분석(with 아이티윌)/R' Related Articles
more



