■ 복습 1. 우유를 구매한 경우 빵을 구매하는 연관규칙에 대한 지지도, 신뢰도, 향상도를 구하시오
# (우유-> 빵)# 1. 데이터셋을 생성합니다.
data<-data.frame(우유 =c(1,1,0,1,1),
빵 =c(1,0,1,1,0),
콜라=c(0,1,1,1,0),
치즈 =c(0,0,1,0,1))
# 2. 데이터를 transaction 행렬로 변환합니다.if(!require(arules)) {
install.packages("arules")
library(arules)
}
trans <- as(as.matrix(data), "transactions")
trans
# 3. 항목의 이름을 지정합니다.
itemLabels(trans) <- c('우유','빵', '콜라', '치즈')
trans
# 4. 연관규칙 모델을 생성합니다.
rules <-apriori(trans, parameter = list(supp=0.001,conf=0.001))
rules #22개## 설명: 제일 좋은 지지도와 신뢰도, 향상도를 구하는 문제## 거의 모든 규칙을 찾기 위해 지지도와 신뢰도를 가장 작은 값으로 설정하는것## 지지도와 신뢰도가 0.001보다 큰 규칙을 찾아라# 5. 결과를 출력합니다.
inspect(rules)
# 6. 문제에 나오는 연관 규칙만 필터링해서 출력합니다.
milk_bread_rules <-subset(rules,lhs%pin% '우유'&rhs%pin% '빵')
inspect(milk_bread_rules)
s <- quality(milk_bread_rules)$support[1]
c <- quality(milk_bread_rules)$confidence[1]
l <- quality(milk_bread_rules)$lift[1]
print(paste('지지도', s))
print(paste('신뢰도', c))
print(paste('향상도', l))
■ 복습2. 우유를 구매한 경우 치즈를 구매하는 연관규칙에 대한 지지도, 신뢰도, 향상도를 구하시오
# (우유-> 치즈)# 1. 데이터셋을 생성합니다.
data2 <-data.frame(우유 =c(0,1,1,1,0),
빵 =c(0,1,0,1,1),
콜라=c(1,1,1,0,1),
치즈 =c(1,0,0,1,1))
# 2. 데이터를 transaction 행렬로 변환합니다.if(!require(arules)) {
install.packages("arules")
library(arules)
}
trans2 <- as(as.matrix(data2), "transactions")
trans2
# 3. 항목의 이름을 지정합니다.
itemLabels(trans2) <- c('우유','빵', '콜라', '치즈')
trans2
# 4. 연관규칙 모델을 생성합니다.
rules2 <-apriori(trans2, parameter = list(supp=0.001,conf=0.001))
rules2 #25개## 설명: 제일 좋은 지지도와 신뢰도, 향상도를 구하는 문제## 거의 모든 규칙을 찾기 위해 지지도와 신뢰도를 가장 작은 값으로 설정하는것## 지지도와 신뢰도가 0.001보다 큰 규칙을 찾아라# 5. 결과를 출력합니다.
inspect(rules2)
# 6. 문제에 나오는 연관 규칙만 필터링해서 출력합니다.
milk_cheese_rules <-subset(rules2,lhs%pin% '우유'&rhs%pin% '치즈')
inspect(milk_cheese_rules)
s <- quality(milk_cheese_rules)$support[1]
c <- quality(milk_cheese_rules)$confidence[1]
l <- quality(milk_cheese_rules)$lift[1]
print(paste('지지도', s))
print(paste('신뢰도', c))
print(paste('향상도', l))
#1. 기본 데이터셋c <- c(3,4,1,5,7,9,5,4,6,8,4,5,9,8,7,8,6,7,2,1)
row <- c('A','B','C','D','E','F','G','H','I','J')
col <- c('X','Y')
data <- matrix( c, nrow=10, ncol=2, byrow=TRUE, dimnames=list(row,col) )
data# 2. 위에서 만든 데이터셋으로 plot 그래프 출력력plot(data)
#3. k-means 모델을 생성해서 2개로 군집화km<- kmeans(data,2)
kmplot(km)
#4. 군집화된 결과와 기존 데이터를 합침cbind(data,km$cluster)
#5. 중심점 두 지점 시각화plot(round(km$center),col= c('red','blue'), pch =22 ,bg='darkblue',
xlim = range(0:10),ylim= range(0:10))
#6. 원래 데이터와 중심점(2개) 시각화plot(round(km$center),col= c('red','blue'), pch =22 ,bg='darkblue',
xlim = range(0:10),ylim= range(0:10))
par(new=T)
plot(data,col= c('red','blue'),
xlim = range(0:10),ylim= range(0:10))
#7. 지금 방금 군집화한 결과를 좀더 확실히 바운더리를 정해서 시각화 하시오 !install.packages("factoextra")
library(factoextra)
km <- kmeans( data, 2 )
fviz_cluster( km , data= data, stand=F)
실습 2. 아래의 데이터를 3개의 군집으로 분류해서 시각화하시오!
c <- c(10, 9, 1, 4, 10, 1, 7, 10, 3, 10, 1, 1, 6, 7 )
row <- c('apple', 'bacon', 'banana', 'carrot', 'salary', 'cheese', 'tomato')
col <- c('X','Y') # x 축이 단맛, y 축은 아삭한 정도
data <- matrix( c, nrow=7, ncol=2, byrow=TRUE, dimnames=list(row,col) )
data
#1. 기본 데이터셋c <- c(10, 9, 1, 4, 10, 1, 7, 10, 3, 10, 1, 1, 6, 7 )
row <- c('apple', 'bacon', 'banana', 'carrot', 'salary', 'cheese', 'tomato')
col <- c('X','Y') # x 축이 단맛, y 축은 아삭한 정도
data <- matrix( c, nrow=7, ncol=2, byrow=TRUE, dimnames=list(row,col) )
data# 2. 위에서 만든 데이터셋으로 plot 그래프 출력력plot(data)
#3. k-means 모델을 생성해서 3개로 군집화km<- kmeans(data,3)
km#4. 군집화된 결과와 기존 데이터를 합침cbind(data,km$cluster)
#5. 중심점 두 지점 시각화plot(round(km$center),col= c('red','blue','pink'), pch =22 ,bg='darkblue',
xlim = range(0:10),ylim= range(0:10))
#6. 원래 데이터와 중심점(2개) 시각화plot(round(km$center),col= c('red','blue','pink'), pch =22 ,bg='darkblue',
xlim = range(0:10),ylim= range(0:10))
par(new=T)
plot(data,col= c('red','blue','pink'),
xlim = range(0:10),ylim= range(0:10))
#7. 지금 방금 군집화한 결과를 좀더 확실히 바운더리를 정해서 시각화 하시오 !install.packages("factoextra")
library(factoextra)
km <- kmeans( data, 3 )
fviz_cluster( km , data= data, stand=F)
좌: 군집3개/ 우: 군집2개
실습 3. 국영수 성적 데이터로 학생들을 군집화 하기
#1. 기본 데이터셋setwd('c:\\data')
data<-read.csv('academy.csv',header =T, fileEncoding ='euc-kr')
head(data)
# 2. 수학점수와 영어점수만 선택하기data2 <- data[ ,c(3,4)]
data2#3. k-means 모델을 생성해서 4개로 군집화set.seed(1)
km<- kmeans(data2,4)
km#4. 학생번호, 수학점수, 영어점수, 군집번호를 같이 출력하기result <- cbind( data[ , c(1, 3, 4)], km$cluster )
result#5. 군집을 시각화 하기 library(factoextra)
fviz_cluster( km , data=data2, stand=F)
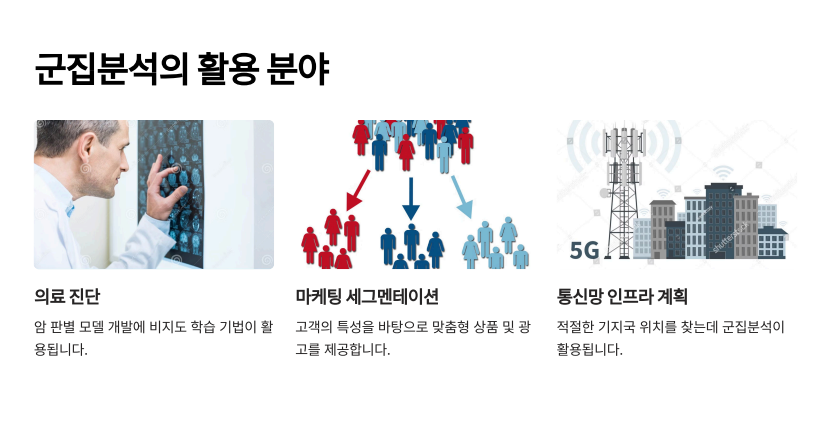
설명: 마케팅에서 사용하는 segmentation 기법 마케팅 전략을 더욱 정교하게 설계하고 각 그룹의 특성과 요구에 맞춤형 마케팅 활동을 전개할 수 있습니다.
실습 4. 유방암 데이터의 악성종양과 양성종양을 k-means 알고리즘으로 2개 군집화해서 분류해 보기 (정답 없이 데이터만 보고 분류하는 실습)
#1. 기본 데이터셋setwd('c:\\data')
data <-read.csv('wisc_bc_data.csv',header =T, fileEncoding ='euc-kr')
head(data)
# 2. 필요한 컬럼 선택하기(id와 정답데이터 제외한 데이터)data2 <- data[ ,3:32]
data2#3. k-means 모델을 생성해서 2개로 군집화set.seed(1)
km<- kmeans(data2,2)
kmcbind(data$id,data$diagnosis,km$cluster)
## 잘못 라벨링을 했는지 확인하려고 위의 작업을 하는것## 암판정하려고 만드는 것은 아님님#4. 시각화하기library(factoextra)
fviz_cluster( km , data=data2, stand=F)
설명: 2번이 정상환자 그룹인데 데이터가 밀집되어 있어서 정상환자들의 특성이 보다 균일하게 나타나고 있습니다.
빨간색 1번 클러스터는 암환자 그룹으로 보이는데 데이터가 넓게 퍼져있어서 다양향 유형의 암환자들이 포함되어 있을 가능성이 있습니다.
k-means 클러스터링 결과를 통해서 암환자와 정상환자를 효과적으로 분류할 수 있으며 각 그룹의 특성을 분석하여 보다 정확한 진단과 치료방안을 마련할 수 있습니다.
실습 5. 아이리스 데이터를 정답을 제외하고 독립변수들만 가지고3개의 군집으로 군집화해서 시각화하시오!
#1. 기본 데이터셋setwd('c:\\data')
data <-read.csv('iris2.csv',header =T, fileEncoding ='euc-kr')
head(data)
# 2. 필요한 컬럼 선택하기(정답데이터 제외한 데이터)data2 <- data[ ,-5]
data2#3. k-means 모델을 생성해서 2개로 군집화set.seed(1)
km<- kmeans(data2,3)
km#4. 시각화하기library(factoextra)
fviz_cluster( km , data=data2, stand=F)
점심시간문제. 다음은 2차원 좌표 평면 위의 3개의 점입니다. 점 A: (-3, -3)점 B: (-1, 1)점 C: (2, 0) 이 3개의 점을 2차원 그래프에 표시하고 이 3개의 점의 평균 좌표를 구하세요. 평균 좌표를 그래프에 표시하세요.
실습 6. 텍스트를 분석해서 성향이 비슷한 텍스트끼리 분류하기
"I just bought a new smartphone and it's amazing!""방금 새 스마트폰을 샀는데 정말 놀라워요!""The battery life of this laptop is incredible.""이 노트북의 배터리 수명은 믿을 수 없을 정도로 좋아요.""Check out this new wireless earbuds, they are fantastic.""이 새로운 무선 이어버드를 확인해보세요, 정말 환상적이에요.""This tablet has a stunning display quality.""이 태블릿은 놀라운 디스플레이 품질을 가지고 있어요.""This smartwatch has excellent features.""이 스마트워치는 훌륭한 기능을 가지고 있어요.""I love exploring new restaurants in the city.""저는 도시에서 새로운 레스토랑을 탐험하는 것을 좋아해요.""The food at this restaurant is delicious.""이 레스토랑의 음식은 정말 맛있어요.""Just tried a new cafe, and their coffee is great.""새로운 카페를 가봤는데, 그들의 커피가 정말 좋아요.""You should try the sushi at this place, it's top-notch.""이곳의 스시를 꼭 드셔보세요, 최고예요.""I had the best pizza at this new Italian restaurant.""이 새로운 이탈리안 레스토랑에서 최고의 피자를 먹었어요."
특성 1. 전자제품에 관심이 있는 사람들의 글 특성 2. 맛집에 관심이 있는 사람들의 글
# 필요한 패키지 설치 및 로드
install.packages("tm")
install.packages("SnowballC")
install.packages("cluster")
install.packages("factoextra")
library(tm) # 텍스트 마이닝하는 패키지
library(SnowballC) #어간추출하는 패키지 (happy, happily, happiness --> happy)
library(cluster) # 군집 알고리즘 패키지
library(factoextra) # 군집 시각화# 텍스트 데이터 생성
texts <- c(
"I just bought a new smartphone and it's amazing!",
"The battery life of this laptop is incredible.",
"Check out this new wireless earbuds, they are fantastic.",
"This tablet has a stunning display quality.",
"This smartwatch has excellent features.",
"I love exploring new restaurants in the city.",
"The food at this restaurant is delicious.",
"Just tried a new cafe, and their coffee is great.",
"You should try the sushi at this place, it's top-notch.",
"I had the best pizza at this new Italian restaurant."
)
# 텍스트를 벡터화
docs <- Corpus(VectorSource(texts)) # 텍스트 데이터를 Corpus 객체로 생성# 변환 단계별로 적용하고 확인
docs <- tm_map(docs, content_transformer(tolower)) # 텍스트를 소문자로 변환
inspect(docs) # 변환 결과 확인
docs <- tm_map(docs, removePunctuation) # 구두점 제거
inspect(docs) # 변환 결과 확인
docs <- tm_map(docs, removeWords, stopwords("english")) # 불용어 제거
inspect(docs) # 변환 결과 확인
docs <- tm_map(docs, stemDocument) # 어간추출
inspect(docs) # 변환 결과 확인# 문서용어 행렬 변환
dtm <- DocumentTermMatrix(docs)
dtm_matrix <- as.matrix(dtm) # 행렬로 변환# TF-IDF 변환
tfidf <- weightTfIdf(dtm) # TF-IDF 가중치를 적용(빈도수 높은 단어 찾기)
tfidf_matrix <- as.matrix(tfidf) # 행렬로 변환
tfidf_matrix
# PCA를 사용하여 차원 축소 (시각화를 위해 2차원으로 축소)
pca_result <- prcomp(tfidf_matrix, center = TRUE, scale. = TRUE) # 차원축소
pca_data <- data.frame(pca_result$x[, 1:2]) # 데이터 표준화# K-means 클러스터링 수행
set.seed(123)
kmeans_result <- kmeans(pca_data, centers = 2, nstart = 20)
# 클러스터 결과 확인
cluster <- kmeans_result$cluster
print(cluster)
# 클러스터 결과 시각화
fviz_cluster(list(data = pca_data, cluster = cluster))
# 각 클러스터에 속하는 텍스트 출력
cluster_texts <- split(texts, cluster)
print(cluster_texts)
실습 7. 한글 데이터도 비지도 학습으로 분류가 되는지 확인하시오
랜덤 "또 모르지 내 마음이",
"저 날씨처럼 바뀔지",
"날 나조차 다 알 수 없으니 (나나나나나나)",
"그게 뭐가 중요하니",
"지금 네게 완전히",
"푹 빠졌단 게 중요한 거지 (나나나나나나)",
"아마 꿈만 같겠지만 분명 꿈이 아니야",
"달리 설명할 수 없는 이건 사랑일거야",
"방금 내가 말한 감정 감히 의심하지 마",
"그냥 좋다는 게 아냐"
)
# 텍스트를 벡터화
docs <- Corpus(VectorSource(texts)) # 텍스트 데이터를 Corpus 객체로 생성
docs <- tm_map(docs, content_transformer(tolower)) # 텍스트를 소문자로 변환
docs <- tm_map(docs, removePunctuation) # 구두점을 제거( 마침표, 물음표, 괄호등)
docs <- tm_map(docs, removeWords, stopwords("english")) # 불용어 제거(the, a, an 등)
docs <- tm_map(docs, stemDocument) # 어간추출(happiness --> happy)
dtm <- DocumentTermMatrix(docs) # 문서용어 행렬로 변환
dtm_matrix <- as.matrix(dtm) # 행렬로 변환# TF-IDF 변환
tfidf <- weightTfIdf(dtm) # TF-IDF 가중치를 적용(빈도수 높은 단어찾기)
tfidf_matrix <- as.matrix(tfidf) # 행렬로 변환
tfidf_matrix
# PCA(주성분 분석) 를 사용하여 차원 축소 (시각화를 위해 2차원으로 축소)
pca_result <- prcomp(tfidf_matrix, center = TRUE, scale. = TRUE) # 차원축소
pca_data <- data.frame(pca_result$x[, 1:2]) # 데이터를 표준화 합니다. # K-means 클러스터링 수행
set.seed(1)
kmeans_result <- kmeans(pca_data, centers = 2, nstart = 20) # 20번의 램덤 초기중심# 설정을 시도한다. # 클러스터 결과 확인
cluster <- kmeans_result$cluster
print(cluster)
# 클러스터 결과 시각화
fviz_cluster(list(data = pca_data, cluster = cluster))
# 각 클러스터에 속하는 텍스트 출력
cluster_texts <- split(texts, cluster)
print(cluster_texts)
[빅분기 문제] 아래의 빈칸에 들어갈 내용으로 가장 알맞은 것은?
Q. 비지도 학습은 레이블이 ( )인 데이터를 학습하고 주요기법에는 ( )가 있다. 1. 알려진, 선형 회귀분석 2. 알려지지 않은 , 군집분석 3. 알려진, 로지스틱 회귀분석 4. 알려지지 않은, 선형회귀분석