# 패키지 설치 (한번만 실행하면 됩니다)
install.packages("randomForest")
# 패키지 로드
library(randomForest)
# iris 데이터셋 로드
data(iris)
# 데이터 확인
head(iris)
# 데이터셋을 랜덤하게 섞고, 70%를 훈련 데이터, 30%를 테스트 데이터로 분리
set.seed(42) # 랜덤 시드 설정 (재현 가능성 위해)
train_indices <- sample(1:nrow(iris), 0.7 * nrow(iris))
train_data <- iris[train_indices, ] #105
test_data <- iris[-train_indices, ] #45
# 랜덤 포레스트 모델 학습
rf_model <- randomForest(Species ~ ., data=train_data, ntree=100, mtry=2, importance=TRUE)
# 모델 요약 정보 확인
print(rf_model)
# 테스트 데이터에 대한 예측 수행
predictions <- predict(rf_model, test_data)
# 혼동 행렬(Confusion Matrix) 확인
confusion_matrix <- table(predictions, test_data$Species)
print(confusion_matrix)
# 정확도 계산
accuracy <- sum(diag(confusion_matrix)) / sum(confusion_matrix)
print(paste("Accuracy:", accuracy))
# 변수 중요도 확인
importance(rf_model)
# 변수 중요도 시각화
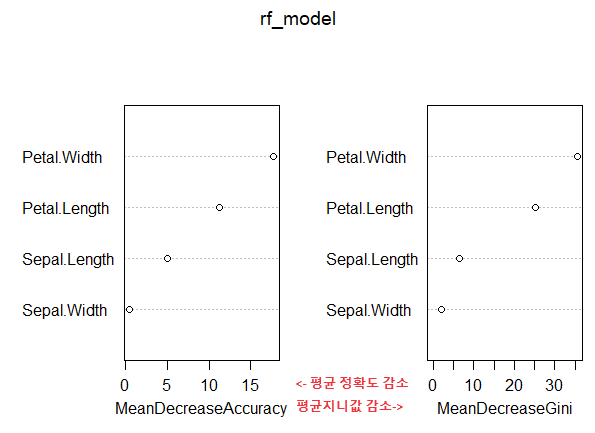
varImpPlot(rf_model)
설명: 1. ntree=100(랜덤으로 생성할 나무 100개) / mtry=2 (노드를 분할 시 선택된 2개의 변수만 고려하여 최적의 분할 을 찾음) 2. mtry 값이 적을 때는 질문이 적어지고 과적합 될 가능성이 줄어듦/ 많을 때는 과적합 될 가능성 높아짐 3. importance=TRUE 는 랜덤 포레스트 모델을 학습 할때 변수의 중요도를 계산하도록설명하는 옵션입니다. 이 옵션을 설정하면 모델이 각 변수의 중요도를 계산하고어떤 변수가 예측에 더 중요한 변수인지를 알수 있게 해줍니다.어떤 변수가 중요한지는 지니계수와 엔트로피를 이용해서 정보획득량으로 중요도를 정합니다.
※ 그래프 설명: 1. MeanDecreaseAccuracy : 변수를 제거 했을 때 모델의 정확도가 얼마나 감소하는지를 측정하는 지표이고 값이 클수록 해당 변수가 모델의 예측 성능에 큰 영향을 미침 2. MeanDecreaseGini: 변수의 gini 불순도 지수를 얼마나 감소 시키는지를 측정함. 값이 클 수록 해당 변수가 분류에 중요한 역할을 한다는 의미임.
분류 모델에서 꽃잎의 길이와 넓이가 꽃받침의 길이와 넓이에서 비해서 상대적으로 더 중요한 변수라는 것을 보여주고 있음.
문제. 와인 데이터를 활용하여 와인의 종류를 분류하는 모델을 생성하고 분류하는데 있어서 중요한 변수가 무었인지 확인하시오.
# 패키지 설치 (한번만 실행하면 됩니다)
#install.packages("randomForest")
# 패키지 로드
library(randomForest)
# iris 데이터셋 로드
data <- read.csv("c:\\data\\wine2.csv")
# 데이터 확인
data$Type <- as.factor(data$Type)
# 데이터셋을 랜덤하게 섞고, 70%를 훈련 데이터, 30%를 테스트 데이터로 분리
set.seed(42) # 랜덤 시드 설정 (재현 가능성 위해)
train_indices <- sample(1:nrow(data), 0.7 * nrow(data))
train_data <- data[train_indices, ]
test_data <- data[-train_indices, ]
# 랜덤 포레스트 모델 학습
rf_model <- randomForest(Type ~ ., data=train_data, ntree=100, mtry=2, importance=TRUE)
# 모델 요약 정보 확인
print(rf_model)
# 테스트 데이터에 대한 예측 수행
predictions <- predict(rf_model, test_data)
# 혼동 행렬(Confusion Matrix) 확인
confusion_matrix <- table(predictions, test_data$Type)
print(confusion_matrix)
# 정확도 계산
accuracy <- sum(diag(confusion_matrix)) / sum(confusion_matrix)
print(paste("Accuracy:", accuracy))
# 변수 중요도 확인
importance(rf_model)
# 변수 중요도 시각화
varImpPlot(rf_model)