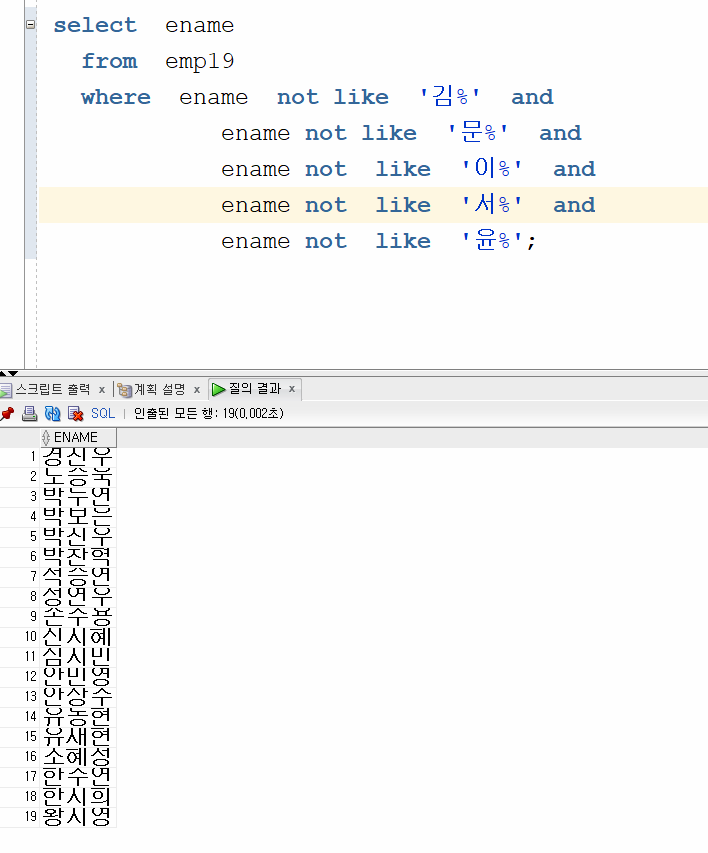
select ename from emp19
where not regexp_like(ename,'^(김|문|이|서|윤)' );
[TIL 23] 240614
복습 1. 숫자 1~2까지의 숫자를 풀어보시오
select level
from dual
connect by level <3;
복습 2. 위의 sql의 dual을 dept로 변경해서 출력하시오.
select level
from dept
connect by level <3;
설명: dual을 dept로 바꿨을 뿐인데 숫자 1과 2가 여러가 출력
복습 3. 어떤 패턴으로 level의 숫자 1과 2가 반복되어 나오고 있는가?
select level, count(*)
from dept
connect by level <4
group by level;
설명: 결과를 보면 dept 테이블의 건수 만큼 배가 되어서 level의 숫자의 개수가 출력되고 있습니다.
복습 4. level 의 숫자값으 dual에서 제공되게 하려면?
select substr(mail_num, digit,1) 숫자, count(*)
from email_number e, (select level as digit
from dual
connect by level < 8) n
where substr(mail_num, digit,1) is not null
group by substr(mail_num, digit,1)
order by 2 desc;
설명: 숫자 1 ~ 7 까지를 출력하는 from 절의 서브쿼리를 따로 만들어서 email_number 랑 조인해서 숫자 1~7까지를 substr(mail_num, digit,1)에 digit에 제공하고 있는 겁니다.
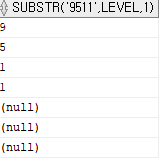
+ 이해 돕기 위한 예제
select substr('9511', level, 1)
from dual
connect by level < 8;
복습 5. 우리반 테이블에서 이메일 중 가장 많이 사용된 숫자를 알아보시오
with num
as
(select level as digit
from dual
connect by level < 8)
select substr(mail_num, digit,1) 숫자, count(*)
from email_number e, num n
where substr(mail_num, digit,1) is not null
group by substr(mail_num, digit,1)
order by 2 desc;
설명: dual이 아닌 테이블에서 level 문장을 출력하려면 다른 조건을 걸어야 한다.
select substr(mail_num, level, 1) as digit
from email_number
connect by prior mail_num = mail_num and prior dbms_random.value is not null
and level <= length(mail_num);
수정
SELECT substr(mail_num, level, 1) AS digit
FROM email_number
CONNECT BY level <= length(mail_num)
AND PRIOR mail_num = mail_num
AND PRIOR sys_guid() IS NOT NULL;
[ SQL 튜닝 ]
1. SELECT문의 실행과정
예제1. SELECT 문의 실행과정 3단계
* SELECT 문의 처리과정
1. 파싱(Parsing)
: SQL을 기계어로 변환하는 작업
2. 실행(Execute)
: 실행계획대로 검색하는 데이터를 DB에서 찾는 과정
3. 패치(Fetch)
: DB에서 찾은 결과를 SQL을 수행한 유저 프로세서에게 전달
* 실행 계획 종류 2가지
1. 예상 실행 계획
: SQL을 실행하기 전에 옵티마이져가 생성한 실행 계획
explain plan for ( select ~~ from~~) ; select * from table(dbms_xplan.display);
2. 실제 실행 계획
: SQL을 실제로 실행할 때 사용한 실제 실행계획 (buffer 의 개수가 나와서 전후비교 가능)
예제 2. 옵티마이져란? : sql을 가장 효율적이고 빠르게 수행할 수 있는 최적의 처리경로를 선택해 주는 오라클 핵심엔진.
설명: SQL 이 들어오면 Query transformer 가 SQL을 변경을 합니다. 변경이 필요 없으면 안 하고 변경이 필요하면 변경을 합니다. 그러고 나서 estimator 가 데이터 딕셔너리(user_tables)를 보고 해당 테이블의 통계정보를 이용해서 실행계획을 plan generator에게 만들 수 있도록 합니다.
문제 3. 아래의 SQL을 query transformer 가 어떻게 변경했는지 확인하시오! (확인하는 이유: 내가 원하는 실행 계획이 안 나오는 경우)
select ename, sal, job
from emp
where job in ( 'SALESMAN', 'ANALYST');
답)
explain plan for
select ename, sal, job
from emp
where job in ( 'SALESMAN', 'ANALYST');
select * from table(dbms_xplan.display);
설명: where 절에 in으로 썼는데 query transformer 가 or로 바꿔서 실행된 것 (비용이 적게 실행되어서)
문제 4. 아래의 sql을 어떻게 쿼리 변형했는지 확인하시오.
select deptno, job, sum(sal)
from emp
group by grouping sets((deptno),(job));
explain plan for
select deptno, job, sum(sal)
from emp
group by grouping sets((deptno),(job));
select * from table(dbms_xplan.display);
설명: temp transformation이라고 나오면 with절로 쿼리 변형을
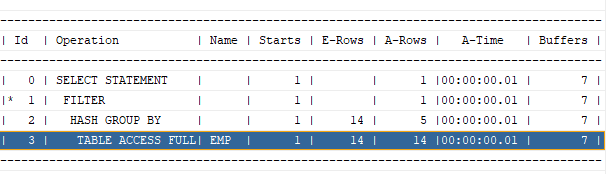
문제 5. 아래의 sql의 튜닝 전 버퍼의 개수와 튜닝 후 버퍼 개수를 출력하시오.
create index emp_job on emp(job);
튜닝전:
select /*+ gather_plan_statistics */ ename, job
from emp
where substr(job, 1, 5)='SALES';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
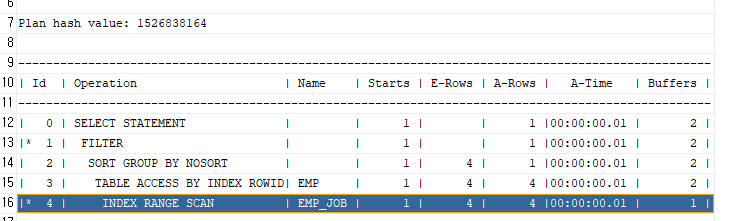
튜닝후:
select /*+ gather_plan_statistics */ ename, job
from emp
where job like 'SALES%';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 6. 아래의 SQL을 튜닝하시오.
create index emp_hiredate on emp(hiredate);
1) 튜닝전 - BUFFER 7개
select /*+ gather_plan_statistics */ ename, hiredate
from emp
where to_char(hiredate,'RRRR')='1980';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후 - BUFFER 2개
select /*+ gather_plan_statistics */ ename, hiredate
from emp
where hiredate >= to_date ('1980/01/01' ,'RRRR/MM/DD') and
hiredate < to_date('1981/01/01','RRRR/MM/DD');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
3. WHERE절에 INDEX 가공 X ( /*+ gather_plan_statistics */ )
예제 3. WHERE절에 인덱스 칼럼 가공하지 않기 WHERE 절에 INDEX COLUMN을 가공하게 되면 FULL TABLE SCAN 하게 됨
Create index emp_sal on emp(sal)
1) 튜닝전 --full scan
select ename , sal
from emp
where sal * 12 = 36000; -- index column
2) 튜닝후
select ename, sal
from emp
where sal = 36000/12;
문제 1. 아래의 sql을 튜닝하시오.
create index emp_ename on emp(ename);
create index emp_sal on emp(sal);
1) 튜닝전
select /*+ gather_plan_statistics */ ename, sal, job
from emp
where ename || sal = 'SCOTT3000';
2) 튜닝후
select /*+ gather_plan_statistics */ ename, sal, job
from emp
where ename = 'SCOTT' and job =3000;
문제 2. 아 례의 sql을 튜닝하시오
1) 튜닝전 -7개
select /*+ gather_plan_statistics */ ename, sal, job
from emp
where job || deptno ='SALESMAN30';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후- 2개
select /*+ gather_plan_statistics */ ename, sal, job
from emp
where job = 'SALESMAN' and deptno =30;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 3. /*+ gather_plan_statistics */ 힌트 없이 실제 실행계획에서 버퍼의 개수를 볼 수 있도록 설정하시오.
설명: statistics_level이라는 파라미터가 default 값이 typical인데 이를 all로 변경하면 앞으로 /*+ gather_plan_statistics */ 를 쓰지 않아도 됩니다.
문제 4. 힌트를 쓰지 않고 실제 실행 계획을 봐보시오.
1) 튜닝전 -7개
select ename, sal, job
from emp
where job || deptno ='SALESMAN30';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후- 2개
select ename, sal, job
from emp
where job = 'SALESMAN' and deptno =30;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
-- 힌트 없이도 잘 실행됨
4. having절에 검색조건 사용x
예제 4. having 절에 검색조건 사용x - having절은 group 함수로 검색조건을 줄때만 사용해야함 - 일반 검색조건을 주게 되면 인덱스를 엑세스 하지 못하게 됨
1) 튜닝전
select job, sum(sal)
from emp
group by job
having sum(sal) > 5000 and job ='SALESMAN';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
select job, sum(sal)
from emp
where job ='SALESMAN'
group by job
having sum(sal) > 5000 ;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제1. 아래의 SQL을 튜닝하시오 !
create index emp_deptno on emp(deptno);
1) 튜닝전:
select deptno, avg(sal)
from emp
group by deptno
having avg(sal) > 2000 and deptno = 20;
1) 튜닝후:
select deptno, avg(sal)
from emp
where deptno = 20
group by deptno
having avg(sal) > 2000;
예제5. where에 인덱스 컬럼 가공이 불가피하다면 함수 기반 인덱스를 생성하시오.
insert into emp(empno, ename, sal) values( 1111, ' jack ', 3000 );
create index emp_ename on emp(ename);
1) 튜닝전:
select ename, sal
from emp
where trim(ename)='jack';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
create index emp_ename_func
on emp(trim(ename));
select ename, sal
from emp
where trim(ename)='jack';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 3. 아래의 sql의 튜닝하시오.
create index emp_ename on emp(ename);
1)튜닝전
select ename, sal
from emp
where ename like '%EN%' OR ename like %IN%'; -- 와일드 카드가 앞에 있으면 FULL SCAN
2) 튜닝후
select /*+ index(emp emp_ename_reg) */ ename, sal
from emp
where regexp_like( ename, '(EN|IN)' );
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: /*+ index(테이블 인덱스이름) */ 이렇게 힌트를 주면 인덱스를 스캔합니다.
설명: 정규 표현식 함수로는 함수기반 인덱스르 생성할 수 없음(위와같이 중간데이터를 검색하는 SQL튜닝방법은 나중에 나옴
문제 4. 아래의 sql의 튜닝하시오.
create index emp19_ename on emp19(ename);
1) 튜닝전
select ename, age
from emp19
where ename like '%연우%' or
ename like '%진우%' or
ename like '%동현%';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
create index emp19_ename_reg
on emp19 regexp_like( ename, '(연우|진우|동현)') ;
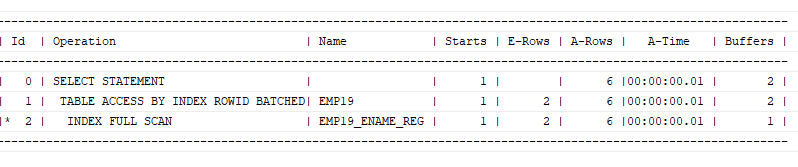
select /*+ index(emp19 emp19_ename_reg) */ ename, age
from emp19
where regexp_like(ename, '(연우|진우|동현)');
튜닝예제7. 암시적 형변환에 주의하세요 !
튜닝전: select ename, sal
from emp
where sal like '30%';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
튜닝후: create index emp_sal_tochar
on emp( to_char(sal) );
select ename, sal
from emp
where sal like '30%';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 5. 아래의 환경을 만들고 아래의 SQL을 튜닝하시오 !
drop table emp9000;
create table emp9000
( ename varchar2(10),
sal varchar2(10) );
insert into emp9000 values('scott', '3000');
insert into emp9000 values('smith', '1000');
insert into emp9000 values('allen', '2000');
commit;
create index emp9000_sal on emp9000(sal);
튜닝전: select ename, sal
from emp9000
where sal = 3000;
튜닝후
select ename, sal
from emp9000
where sal = '3000';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: SQL을 재작성할 수 있으면 SQL재작성하는게 먼저입니다. 인덱스를 만드는것은 아주 값비싼 작업입니다.
※ 현업 튜닝 사례
튜닝 날짜 : 튜 너 : 유연수 차장 튜닝 내용 : 8월 4일 16시 11분 부산지원 청구 1호기에서 DB FILE SCATTRED READ 대기 이벤트를 일으키면서 47초 이상 수행되는 SQL 발견하여 관련된 SQL 튜닝. (튜닝전 47초 --> 튜닝후 1초)
☞ 문제의 SQL 을 수행한 프로그램 정보및 DB 유져정보
DB SCHEMA : HIRA_LINK OS USER : BWJF01 SYSTEM ID: ORA8 MACHINE : bonbu01 PROGRAM : @bonbu01 (TNS V1-V3)
☞ 튜닝전 SQL 과 TRACE 정보
SELECT "RECV_NO" , "RECV_YYYY" , "BRCH_CD" , "RECV_DATA_TYPE" , "YKIHO" , "DMD_TYPE_CD" , "PAY_SYS_TYPE" , "RECV_DT" , "EDPS_RECV_CLOS_YN" , "DIAG_YYYYMM" , "TOT_DMD_CNT" , "RETN_TYPE" FROM "TBJFC02" "TBJFC02" WHERE TO_NUMBER( "RECV_DT" ) >=20060724 AND TO_NUMBER( "RECV_DT" ) <=20060805 AND "RECV_DATA_TYPE" ='1' AND ( "DMD_TYPE_CD" ='2' OR "DMD_TYPE_CD" ='3' ) AND "PAY_SYS_TYPE" ='A' AND "RETN_TYPE" IS NULL AND "EDPS_RECV_CLOS_YN" ='Y' AND SUBSTR( "YKIHO" , 3 , 1 ) <>'9';
Event waited on Count Zero Ela Elapse AVG(Ela) MAX(Ela) Blocks ---------------------------------------- -------- -------- ---------- ---------- ---------- -------- db file sequential read 12 9 0.04 0.00 0.02 12 global cache cr request 36 0 0.11 0.00 0.01 0 SQL*Net message to client 357 0 0.01 0.00 0.01 0 SQL*Net message from client 357 0 11.53 0.03 0.38 0 file open 3 0 0.00 0.00 0.00 0 SQL*Net more data to client 234 0 0.09 0.00 0.01 0 latch free 2 0 0.04 0.02 0.02 0
Rows Row Source Operation ---------- --------------------------------------------------- 8884 TABLE ACCESS BY INDEX ROWID TBJFC02 10716 INDEX RANGE SCAN
예제 7. order by 를 통한 과도한 정렬작업을 피하세요 !
order by 절을 사용해서 SQL을 작성하게 되면 오라클은 내부적으로 정렬작업을 수행하기 위해 오라클 메모리인 pga 영역에서 정렬작업을 수행합니다. 그런데 이 pga 영역이 한정된 메모리 영역이기 때문에 너무 과도한 정렬작업을 해야한다면 db 에 부하를 주게 됩니다.
그래서 만약 인덱스를 활용할 수 있다면 order by 절 쓰지말고 인덱스를 통해서
정렬된 결과를 보는 튜닝방법입니다.
다음과 같이 인덱스를 생성하면 인덱스의 구조는 컬럼값 + rowid 로 되어있고
컬럼값은 ascending 하게 정렬되어 저장되게 됩니다.
@demo
create index emp_sal on emp(sal);
12번째 ppt 그림을 참고 하세요 ~
테이블에 rowid 를 조회하시오 !
select rowid, e.*
from emp e;
rowid 가 해당 로우의 주소입니다. 이 주소가 테이블에도 있고 인덱스에도 있습니다.
※ 인덱스의 데이터를 모두 다 스캔하는 where 절 검색 조건
1. 숫자 >=0
2. 문자 > ' '
3. 날짜 <= to_date('9999/12/31','RRRR/MM/DD')
문제1. 아래의 SQL을 튜닝하시오 !
@demo
create index emp_sal on emp(sal);
튜닝전: select ename, sal
from emp
order by sal asc;
-- 실행계획에서 order by 가 출현하면 빅데이터 환경에서는 느려집니다.
튜닝 후: select ename, sal
from emp
where sal >=0;
설명: 실행계획에서 order by 가 출현하면 빅데이터 환경에서는 느려집니다. where 절에 인덱스 컬럼을 가지고 검색조건을 줘야 인덱스를 사용할 수 있습니다.
※ 인덱스를 스캔할 때 사용하는 힌트 2가지 ?
1. index_asc 힌트 : 인덱스를 위에 아래로 ascending 하게 스캔하겠다. 2. index_desc 힌트 : 인덱스를 밑에 위로 descending 하게 스캔하겠다.
문제 2. 아래의 SQL 을 튜닝하시오 !
create index emp_sal on emp(sal);
튜닝전: select ename, sal
from emp
order by sal desc;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
튜닝후: select /*+ index_desc(emp emp_sal) */ ename, sal
from emp
where sal >= 0 ;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
★ 마지막 문제: 아래의 SQL을 튜닝하시오.
create index emp_hiredate on emp(hiredate);
튜닝전:
select ename, hiredate
from emp
order by hiredate desc;
튜닝후:
select /*+ index_desc(emp emp_hiredate) */ ename, hiredate
from emp
where hiredate < to_date ('9999/12/31','RRRR/MM/DD');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));