[빅데이터분석] SQL_TIL 20 (권한부여 명령어, ROLE, 컬럼 감추기, on delete set null, on delete cascade ,제약 기능 중지 시키기, 함수기반 인덱스, 은닉층)
chonny
2024. 6. 11. 17:04
★ 점심시간문제: 다음의 from 절의 서브쿼리를 with 절로 변경하세요.
1) 튜닝전
select deptno, ename, sal, 순위
from ( select deptno, ename, sal, dense_rank() over ( partition by deptno
order by sal desc ) 순위
from emp
)
where 순위 = 1;
2) 튜닝후
with dept_rank as
(select deptno, ename, sal, dense_rank() over ( partition by deptno
order by sal desc ) 순위
from emp)
select deptno, ename, sal, 순위
from dept_rank
where 순위 = 1;
[TIL 20] 240611
112. 권한부여 명령어
예제 112번. 권한을 부여하는 명령어
* DB 권한의 종류 2가지 1. system 권한: db내에서 특정 작업을 수행하기 위한 권한 예: create, create index 권한 등 2. object 권한: db객체의 data를 엑세스하거나조작 할 수 있는 권한 예: select on emp 와 같이 emp테이블을 select 할 수 있는 권한
Q2. 여러분들이 어느회사에 데이터 엔지니어인데 여러분들에게 데이터 분석가나 개발자들이 유져를 만들어달라고 요청을 했습니다. 그리고 그 유져가 테이블을 생성할 수 있는 권한이 있어야한다고 요청을 받았습니다. 유져를 jack 이라는 이름으로 생성하시오 !
1) 명령 프롬프트 창을 열기
C:\Users\itwill> sqlplus sys/oracle_4U as sysdba
SQL> create user jack
identified by tiger;
SQL> grant connect to jack;
SQL> grant create table to jack;
Q3. JACK으로 접속해서 JACK이 가지고 있는 시스템 권한이 뭔지 확인하시오.
SQL> connect jack/tiger
SQL> show user
SQL> select * from session_privs;
설명: set container -> 오라클 12c부터 데이터 베이스를 컨테이너 db에 쉽게 생성할 수 있게 만들었음. create table -> 테이블을 생성할 수 있는 권한(인덱스 생성 권한도 자동으로 들어옴) create session -> 오라클에 접속할 수 있는 권한
Q4 다시 SYS유저에서 JACK에게 CREATE VIEW권한과 CREATE SEQUENCE 권한을 부여하시오.
SQL> Connect sys/oracle_4U as sysdba
연결되었습니다.
SQL> show user
USER은 "SYS"입니다
SQL> grant create view,create sequence to jack;
권한이 부여되었습니다.
Q5. JACK에게 접속해서 JACK이 가지고 있는 SYSTEM 권한이 뭔지 확인하시오
select * from session_privs;
Q6. 다시 create sequence 권한과 create view 권한을 취소하시오
SQL> connect sys/oracle_4U as sysdba
SQL> revoke create sequence , create view from jack;
문제 1. jack2라는 유저를 생성하고 접속할 수있는 권한만 부여하고서 jack2유저로 접속해서 가지고있는 권한이 뭔지를 확인하시오.
1) 먼저 sys 로 접속한다.
sqlplus sys/oracle_4U as sysdba
2) 유저 생성
SQL> create user jack2
2 identified by tiger;
3) 권한부여
SQL> grant connect to jack;
3) 신규 유저 접속
SQL> connect jack2/tiger
4) 권한 확인
SQL> select * from session_privs;
문제 2. 명령 프롬프트창을 3개열고 각각 다음과 다르게 접속하시오.
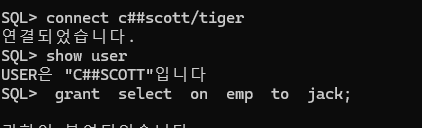
문제3. c##scott 유져에서 jack 에게 c##scott 유져가 소유한 emp 테이블을 select 할 수 있는 권한을 주시오 !
SQL> show user
USER은 "SCOTT"입니다
SQL> grant select on emp to jack;
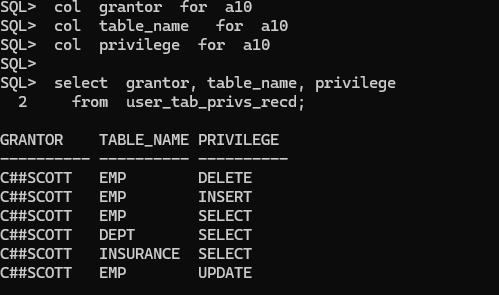
문제 4. jack 유져가 보유한 객체권한이 무엇인지 확인하시오 !
SQL> select grantor, table_name, privilege
2 from user_tab_privs_recd;
col grantor for a10 col table_name for a10 col privilege for a10
※ user_tab_privs_recd : 내가 부여받은 객체 권한을 확인할 때 보는 데이터 사전 user_tab_privs_made : 내가 부여한 객체 권한을 확인할 때 보는 데이터 사전
문제 5. jack 유저에서 emp 테이블을 select 해보시오.
select * from c##scott.emp;
설명: 테이블명 앞에 유저이름을 붙여줘야됨 현업팁: 위와 같이 유저이름 안붙이고 테이블을 select 할 수 있게하는게 뭔지? -> synonym(시너님)
문제 6. c##scott 유저에서 c##scott.emp에 대한 동의어를 emp 로 생성하시오.
SQL> create public synonym emp
2 for c##scott.emp;
설명: c##scott.emp로 select 할 수도 있고 emp로 select 할 수 있다는 것
문제 7. jack유저에서 c##scott 의 emp 테이블을 유저명 없이 select 하시오
SQL> create public synonym emp
2 for c##scott.emp;
동의어를 만들었기 때문에 유저이름 앞에 시스템명을 안붙여도 됨
문제 8. c##scott유저에서 jack에게 dept테이블을 select 할 수 있는 권한을 부여하시오;
SQL> grant select on dept to jack;
권한이 부여되었습니다.
SQL> create public synonym dept
2 for c##scott.dept;
문제 9. c##scott 유저에서 jack 에게 c##scott유저의 insurance 테이블을 select 할 수 있는 권한을 부여하시오. 그리고 나서 시너님도 만들어주시오
SQL> show user
USER은 "C##SCOTT"입니다
SQL> grant select on insurance to jack;
권한이 부여되었습니다.
SQL> create public synonym insurance
2 for c##scott.insurance;
동의어가 생성되었습니다.
문제 10. jack 유저에서 부여받은 객체 권한이 무엇인지 확인하시오.
select grantor, table_name, privilege
2 from user_tab_privs_recd;
문제 11. c##scott 유저에서 jack유저에게 c##scott 유저의 emp테이블을 insert, update, delete할 수 있는 권한도 부여하시오. 1) 권한부여 ( c##scott cmd에서) 2) 권한확인(jack cmd에서)
문제 12. c##scott유저에거 jack에게 dept 테이블의 insert,update할 수 있는 권한을 부여하시오. 1) 권한부여(c##scottcmd에서)
SQL> grant insert,update on dept to jack;
2) 권한확인(jack cmd에서)
col grantor for a10
col table_name for a10
col privilege for a10
select grantor, table_name, privilege
from user_tab_privs_recd;
★ 문제 13. (sqld와 ocp 시험 문제) jack유저에서 jack2 유저에게 c##scott유저의 emp테이블을 select 할 수 있는 권한을 부여하시오.
설명: jack은 c##scott 유저에서 emp 테이블을 select 할 수 있는 권한을 받았지만 그 권한을 남에게 줄 수 있는 권한은 받지 못했음 그래서 jack이 권한을 jack2에게 주려면 c## 유저에서 다음과 같이 권한을 부여해야함(c##scott 에서 실행)
1) jack 유저게 권한 부여
grant select on emp to jack with grant option;
2) jack 이 jack2에게 권한부여할 수 있는지 확인.
grant select on c##scott.emp to jack2;
113. ROLE
예제113번. 권한관리를 쉽게 하기 위한 방법으로 role 을알아야합니다. : 오라클 처음 설치하고 유져 생성한 다음에 권한을 유져에게 부여하는 방법이 role 을이용하는것 입니다.
role 이란 ? 권한 관리를 쉽게하기 위한 권한들의 집합
그림설명: 롤을 이용하면 그냥 롤만 유져에게 부여하면 간단합니다. ex)dba 권한을 jack 에게 부여하고 싶다면 dba 는 200가지가 넘는 권한을 받아야합니다. 그런데 다음과같이dba 라는 롤만 부여받으면 끝입니다.
1) sys 유져에서 다음과 같이 수행합니다.
SQL> grant dba to jack;
2) dba 라는 롤이 부여받은 시스템 권한이 뭔지 확인하는 방법
SQL> select *
from role_sys_privs
where role='DBA';
회사에서는 DBA 라는 role 은 아무에게나 주지 않고 회사에서 몇몇만 가지고 있습니다.
대부분은 아래의 role 들을 가지고 있습니다.
SQL> grant resource, connect to jack2;
SQL> grant create table to resource;
SQL> grant create view to resource;
SQL> grant create sequence to resource;
SQL> select *
from role_sys_privs
where role='RESOURCE';
위의 작업은 sys에서 수행해야합니다.resource 라는role 에 9개의 권한이 들어가 있습니다. 9개의 권한을 한번에jack2 에게 주고 싶다면 ?
SQL> grant reosurce to jack2;
정리하면 집에 노트북에 오라클을 설치하고 유져를 생성했으면 그냥 dba 롤을 주고 연습하고 회사에서는 resource, connect 라는 롤 정도만 받아서 수행합니다.
문제1. 책 1-12쪽에 나온 것 처럼 sys유저에서 manager이라는 롤을 만들고 manager롤에게 create table, create view 권한을 부여하고 manager이라는 롤을 jack2에게 부여하시오.
1) sys sql 들어가기
sqlplus sys/oracle_4U as sysdba
create role manager;
grant create table, create view to manager;
grant manager to jack2;
2) jack2 으로 접속해서 내가 부여받은 role을 확인하세요.
connect jack2/tiger
select * from session_roles;
114. 컬럼감추기
예제 113번. 컬럼 감추기 기능 구현하기 : 컬럼을 추가하고 삭제하고 감추는 기능 1. 컬럼추가
alter table emp
add address varchar2(10);
2. 컬럼삭제
alter table emp
drop column address;
3. 컬럼 변경(데이터 타입의 길이를 늘릴때 사용)
alter table emp
modify ename varchar2(50);
4. 컬럼 감추기 (사용량이 많을 때 컬럼을 삭제하게 되면 성능이 떨어짐- 삭제하지 않고 잠깐 감출 때)
alter table emp
set unused column sal;
문제 1. emp 테이블에서 job컬럼을 감추시오.
alter table emp
set unused column job;
문제 2. job컬럼을 다시 나타나게하시오.
alter table emp
set used column job;
설명: 이미 감춰졌으면 끝임, 감추겠다는 것은 당장 컬럼을 drop 못하니까 감춰놨다가 나중에 drop하려고감추는것임.
문제 3. 감춰진 column을 모두 삭제하시오.
alter table emp
drop unused columns;
115. on delete set null 과 on delete cascade
예제 114번. on delete set null 과 on delete cascade 옵션 사용 SQLD 와 OCP 시험용
1. on delete cascade 옵션이란 ?
dept 테이블을 부모 테이블로 두고 emp 테이블을 자식 테이블로 구성했을때 emp 테이블에 10번 부서번호가 있으면 dept 테이블의 10번 부서번호를 삭제할 수 없습니다. 그런데 제약을 걸때 on delete cascade 옵션을 써서 걸게 되면 dept 테이블의 10번을 지울때 지워지면서 emp 테이블의 10번 부서번호의 데이터가 같이 지워집니다.
** 부모 자식간의 특정 행을 삭제하면 동시에 사라짐 (on delete cascade)
** 부모 자식간의 특정 행을 삭제하면 null 로 변경됨 (on delete set null)
of) 제약조건 삭제:
alter table telecom_table
drop constraint telecom_pk cascade;
문제1.dept 테이블에 deptno 에 primary key 제약을 걸고 emp 테이블의 deptno에 foreign key 제약을 걸면서 dept 테이블에 deptno를 참조하겠다고 설정하시오 !
alter table dept
add constraint dept_deptno_pk primary key(deptno);
alter table emp
add constraint emp_deptno_fk foreign key(deptno) references dept(deptno);
문제 2. 위의 상황에서 dept테이블의 10번 부서번호를 지우시오.
delete from dept
where deptno =10;
문제 3. dept테이블에 deptno에 걸린 primary key 제약을 삭제하시오 (cascade 사용)
alter table dept
drop constraint dept_deptno_pk cascade;
문제 4. 다시 부모자식 관계를 형성하는데 on delete cascade 옵션을 써서 만드시오
alter table dept
add constraint dept_deptno_pk primary key(deptno);
alter table emp
add constraint emp_deptno_fk foreign key(deptno) references dept(deptno) on delete cascade;
문제 5. dept테이블의 10번 부서번호를 삭제하시오.
delete from dept
where deptno =10;
문제 6. DEPT 테이블의 20번 부서번호를 delete 하시오.
delete from dept
where deptno =20;
emp와 dept 테이블의 부서번호 20 둘다 없어
문제 7. 다음과 같이 on delete set null 옵션으로 부모 자식 관계를 형성하고 dept 테이블의 30번 부서번호를 지우면 emp 테이블의 30번 부서번호가 어떻게 되는지 확인하시오 !
alter table dept
add constraint dept_deptno_pk primary key(deptno);
alter table emp
add constraint emp_deptno_fk foreign key(deptno) references dept(deptno) on delete set null;
delete from dept
where deptno=30;
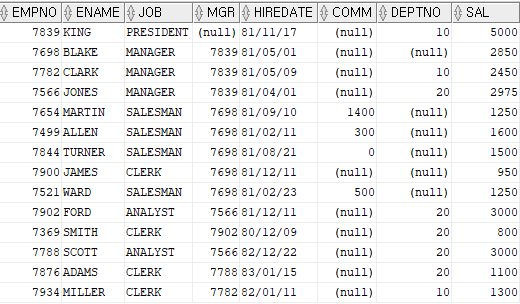
select * from emp;
설명: 부서번호 30번의 값이 null 이됨.
문제 8. telecom_table을 부모테이블로 두고 emp19를 자식 테이블로 만드는데 telecom_table에서 특정 통신사를 delete 하면 emp19의 관련 통신사인 학생들도 지워지게 부모자식관계를 설정하시오.
alter table telecom_table
add constraint telecom_pk primary key(telecom);
alter table emp19
add constraint telecom_fk foreign key(telecom) references telecom_table(telecom) on delete cascade;
116. 제약 기능 중지 시키기
예제 116. 제약 기능 중지 시키기
Q1.EMP 테이블의 SAL에 체크 제약을 거시오.(월급이 0-9000 사이의 데이터만 입력 또는 수정되게끔 하시오)
alter table emp
add constraint emp_sal_ck check( sal between 0 and 9000 );
update emp
set sal = 9600
where ename='KING';
RA-02290: 체크 제약조건(SCOTT.EMP_SAL_CK)이 위배되었습니다
Q2. 월급에 걸린 체크 제약을 잠깐 중지 시키고 KING의 월급을 9600으로 수정하시오!
alter table emp
disable constraint emp_sal_ck;
select constraint_name, status
from user_constraints
where table_name='EMP';
update emp
set sal = 9000
where ename='KING';
Q3. 이제 다시 emp_sal_ck 제약을 활성화 시키시오.
alter table emp
enable constraint emp_sal_ck;
- 오류뜸
ㄴ 이전에 king을 변경했기 때문에 데이터가 제약에 위반된 데이터라서 오류
novalidate 사용으로 오류 해결
alter table emp
enable novalidate constraint emp_sal_ck;
설명: novalidate 옵션을 쓰게되면 기존에 들어 있던 데이터들에 대햇는 제약 검사하지않고 앞으로 들어온 데이터만 제약 걸겠다는 소리임
문제 1. 우리반 테이블에 이름이 성연우 학생의 나이를 28로 변경하시오.
update emp19
set age=28
where ename= '성연우';
문제2.우리반 테이블의 나이에 체크제약을 거는데 나이가 20-36의 데이터만 입력 또는 수정되게 체크제약을 거시오.
alter table emp19
add constraint emp19_age_ck check( age between 20 and 36);
문제3. 성연우 학생의 나이를 38로 변경하기 위해서 체크제약을 중지시키시오,
alter table emp19
disable constraint emp19_age_ck;
문제 4. 성연우학생의 나이를 38로 변경하시오
update emp19
set age=38
where ename= '성연우';
문제 5. 체크 제약을 활성화 시키시오.
alter table emp19
enable novalidate constraint emp19_age_ck;
117. 함수기반 인덱스
예제 117. 함수기반 인덱스 생성
Q1. 아래의 SQL이 인덱스 스캔을 할 수 있도록 인덱스를 생성하시오.
select ename, sal
from emp
where ename ='SCOTT';
답)
create index emp_ename
on emp(ename);
문제1. 아래의 SQL의 실행계획을 확인해서 인덱스를 통해서 데이터를 검색하는지 확인하시오.
explain plan for
select ename, sal
from emp
where ename ='SCOTT';
select * from table(dbms_xplan.display);
문제2. 월급이 2400 이상이 사원들의 이름을 소문자로 변경하고 commit 하시오.
update emp
set ename=lower(ename)
where sal >=2400;
commit;
설명: 현업처럼 대소문자가 섞여있는 상황으로 데이터를 변경됨
문제 3. 이름이 scott인 사원의 이름과 월급을 출력하시오.
select ename, sal
from emp
where ename ='SCOTT';
select ename, sal
from emp
where upper(ename) ='SCOTT';
설명: 이름의 대소문자가 섞여 있기 때문에 안나옴 - upper을 해줘야 나
문제 4. 위 sql의 실행 계획을 확인하시오
explain plan for
select ename, sal
from emp
where upper(ename) ='SCOTT';
select * from table(dbms_xplan.display);
설명: index가 있는데 full table scan 을 함 -> where 절에 ename만 써야되는데upper 과 같은 함수를 이용하여 가공하게 되면 인덱스를 사용할 수 없음
문제 5. 위와 같은 상황에서도 index scan 하려면?
** 함수 기반 index를 만듬
create index emp_ename_fuc
on emp(upper(ename));
explain plan for
select ename, sal
from emp
where upper(ename) ='SCOTT';
select * from table(dbms_xplan.display);
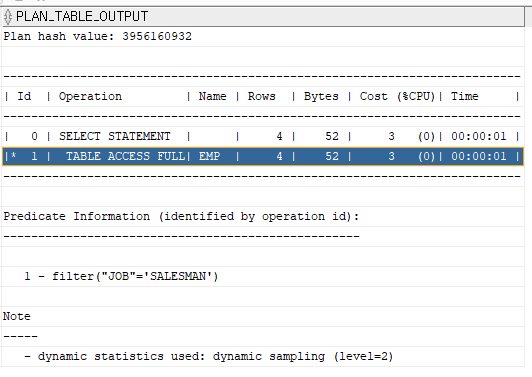
문제 6. 아래의 sql을 빠르게하기위한 인덱스를 생성하시오.
select ename, job
from emp
where job='SALESMAN';
explain plan for
select ename, job
from emp
where job='SALESMAN';
select * from table(dbms_xplan.display);
답)
create index emp_job
on emp(job);
explain plan for
select ename, job
from emp
where job='SALESMAN';
select * from table(dbms_xplan.display);
문제 7. 아래의 sql을 고치지 않고 그대로 두면서 인덱스를 통해서 데이터를 엑세스 할 수 있도록 인덱스를 생성하시오.
select ename, job
from emp
where substr(job, 1,5)='SALES';
답) 함수기반 index 만들기
create index emp_job_func
on emp(substr(job,1,5));
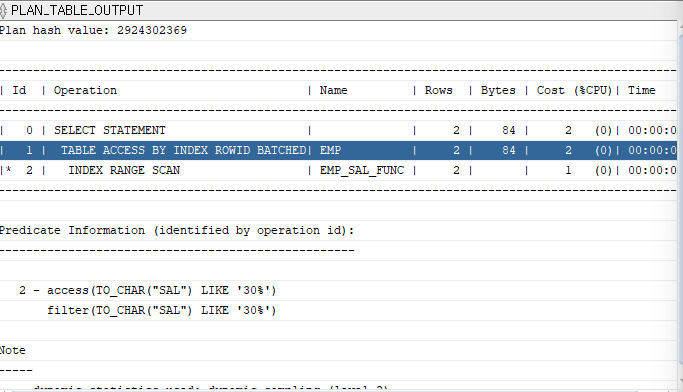
문제 8. 아래의 sql을 튜닝하시오. 인덱스를 통해서 데이터가 엑세스 될 수 있도록 하시오! (실행계획 포함)
1) 튜닝전
select ename, sal
from emp
where sal like '30%';
2) 튜닝후
create index emp_sal_func
on emp(to_char(sal));
explain plan for
select ename, sal
from emp
where sal like '30%';
;
select * from table(dbms_xplan.display);
설명: like 연산자를 자주 사용할 것 같으면 처음부터 테이블 설계할 때부터 해당 컬럼을 문자형으로 만들어줘야합니다. 그런데 숫자형으로 만들고 like 연산자를 사용하게 되면 오라클이 암시적으로 형변환을 일으켜서 위의 SQL 같은 경우는 아래와 같이 실행을 합니다.
select ename, sal
from emp
where to_char(sal) like '30%';
그러면 월급의 인덱스를 사용하지 못하는 sql이 되버립니다. 이럴때 아주 유용한 인덱스가 함수 기반 인덱스 입니다.
create index emp_sal_func
on emp( to_char(sal) );
118. 퍼셉트론에 발전된 개념인 신경망을 SQL로 구현
예제118번. 퍼셉트론에 발전된 개념인 신경망을 SQL로 구현하기
SQL200제 책의 187번 예제, 487 페이지의 내용입니다. SQL 포트폴리오할때 신경망을 이용해서 예측이나 분류를 하고 싶다면 이 스크립트를 이용하면 됩니다.
※ 머신러닝으로 할 수 있는것2가지 ?
1. 예측 : 미국 국민 의료 데이터로 회귀분석 2. 분류 : 유방암 환자의 악성 종양과 양성 종양을 분류하는 신경망
신경망을 이용해서 예측과 분류, 2가지를 다 할 수 있는데 예측을 해보겠습니다.
Q. 콘크리트 강도를 예측하는 신경망을 생성합니다.
여러분 선배 데이터 분석가가 하는 일중에 하나가 태양열 전지를 생산하는 회사인데 태양열 전지를 만들때 재료를 어떻게 조합해서 전력을 많이 생산하는 태양열 전지를 만들 수 있는지 머신러닝으로 데이터 분석을 한 사례.
어떻게 콘크리트 재료를 조합해야 강도가 높은 콘크리트를 만들 수 있는가 ?
이것을 경험이 많은 사람의 직관이 아닌 빅데이터를 이용해서 기계학습 시켜서 알아내겠다는 겁니다.
<CONCRETE 테이블 생성> 1. mount of cement: 콘크리트의 총량 2. slag : 시멘트 3. ash : 회분 (시멘트) 4. water : 물 5. superplasticizer : 고성능 감수재(콘크리트 강도를 높이는 첨가제) 6. coarse aggregate : 굵은 자갈 7. fine aggregate : 잔 자갈 8. aging time : 숙성시간
-- 1. 머신러닝 모델을 훈련시킬 데이터를 만듭니다.
DROP TABLE CONCRETE;
CREATE TABLE CONCRETE
( C_ID NUMBER(10),
CEMENT NUMBER(20,4),
SLAG NUMBER(20,4),
ASH NUMBER(20,4),
WATER NUMBER(20,4),
SUPERPLASTIC NUMBER(20,4),
COARSEAGG NUMBER(20,4),
FINEAGG NUMBER(20,4),
AGE NUMBER(20,4),
STRENGTH NUMBER(20,4) );
-- 데이터 입력: SQL Developer를 이용해서 concrete.csv 를 CONCRETE 테이블에 입력합니다.
SELECT COUNT(*) FROM CONCRETE;
-- 1030
--2. 훈련 데이터와 테스트 데이터를 9대 1로 분리합니다.
-- 훈련 데이터: 기계를 학습시킬 데이터
-- 테스트 데이터: 학습한 기계를 시험보게해서 시험점수가 얼마인지 확인하려는 데이터
DROP TABLE CONCRETE_TRAIN;
CREATE TABLE CONCRETE_TRAIN
AS
SELECT *
FROM CONCRETE
WHERE C_ID < 931;
DROP TABLE CONCRETE_TEST;
CREATE TABLE CONCRETE_TEST
AS
SELECT *
FROM CONCRETE
WHERE C_ID >= 931;
select * from CONCRETE_TRAIN; - 930건
select * from CONCRETE_TEST; - 100건
-- 3. 머신 러닝 모델의 환경설정을 위한 정보가 들어있는 테이블을 생성합니다.
DROP TABLE SETTINGS_GLM;
CREATE TABLE SETTINGS_GLM
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_GLM(SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.ALGO_NAME, DBMS_DATA_MINING.ALGO_NEURAL_NETWORK);
INSERT INTO SETTINGS_GLM (SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.PREP_AUTO, DBMS_DATA_MINING.PREP_AUTO_ON);
END;
/
select
-- 4. 머신러닝 모델을 생성합니다.
BEGIN
DBMS_DATA_MINING.DROP_MODEL('MD_GLM_MODEL');
END;
/
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
MODEL_NAME => 'MD_GLM_MODEL', --모델명
MINING_FUNCTION => DBMS_DATA_MINING.REGRESSION, --수치예측, 분류(classification)
DATA_TABLE_NAME => 'CONCRETE_TRAIN', -- 훈련 테이블명
CASE_ID_COLUMN_NAME => 'C_ID', -- pk에 해당하는 컬럼명
TARGET_COLUMN_NAME => 'STRENGTH', -- 종속변수(정답)
SETTINGS_TABLE_NAME => 'SETTINGS_GLM');
END;
/
-- 5. 생성된 모델을 확인합니다.
SELECT MODEL_NAME,
ALGORITHM,
MINING_FUNCTION
FROM ALL_MINING_MODELS
WHERE MODEL_NAME = 'MD_GLM_MODEL';
-- 6. 인공신경망의 환경 구성정보를 확인합니다.
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_GLM_MODEL'
AND SETTING_NAME = 'NNET_HIDDEN_LAYERS';
-- 은닉층이 1개로 나타남 (공부끝)
-- 7. 신경망 모델이 예측한 결과를 확인합니다. (시험)
SELECT C_ID, STRENGTH 실제값, ROUND( PREDICTION(MD_GLM_MODEL USING *),2) 예측값
FROM CONCRETE_TEST;
-- 8. 실제 값과 예측 값 간의 상관관계를 확인합니다.
SELECT ROUND(CORR(PREDICTED_VALUE, STRENGTH),2) 상관관계
FROM (
SELECT C_ID, PREDICTION(MD_GLM_MODEL USING *) PREDICTED_VALUE,
PREDICTION_PROBABILITY(MD_GLM_MODEL USING * ) PROB, STRENGTH
FROM CONCRETE_TEST
);
★위의 신경망 모델의 모델의 은닉층이 1개임
문제 1. 위의 신경망의 은닉층을 2개로 만들고 각은닉층 마다뉴런수를 100개로 해서 신경망을 생성하고학습 시키시오(교재 489쪽)
-- 1. 인공신경망의 구조를 은닉1층에서 은닉2층으로 재구성합니다.
DROP TABLE SETTINGS_GLM;
CREATE TABLE SETTINGS_GLM
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_GLM(SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.ALGO_NAME, DBMS_DATA_MINING.ALGO_NEURAL_NETWORK);
INSERT INTO SETTINGS_GLM (SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.PREP_AUTO, DBMS_DATA_MINING.PREP_AUTO_ON);
INSERT INTO SETTINGS_GLM (SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.NNET_NODES_PER_LAYER, '100,100');
END;
/
-- 2. 머신러닝 모델을 생성합니다.
BEGIN
DBMS_DATA_MINING.DROP_MODEL('MD_GLM_MODEL');
END;
/
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
MODEL_NAME => 'MD_GLM_MODEL',
MINING_FUNCTION => DBMS_DATA_MINING.REGRESSION,
DATA_TABLE_NAME => 'CONCRETE_TRAIN',
CASE_ID_COLUMN_NAME => 'C_ID',
TARGET_COLUMN_NAME => 'STRENGTH',
SETTINGS_TABLE_NAME => 'SETTINGS_GLM');
END;
/
-- 3. 인공신경망의 환경 구성정보를 확인합니다.
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_GLM_MODEL'
AND SETTING_NAME IN ('NNET_HIDDEN_LAYERS','NNET_NODES_PER_LAYER');
-- 4. 신경망 모델이 예측한 결과를 확인합니다.
SELECT C_ID, STRENGTH 실제값, ROUND( PREDICTION(MD_GLM_MODEL USING *),2) 예측값
FROM CONCRETE_TEST;
-- 5. 실제 값과 예측 값 간의 상관관계를 확인합니다.
SELECT ROUND(CORR(PREDICTED_VALUE, STRENGTH),2) 상관관계
FROM (
SELECT C_ID, PREDICTION(MD_GLM_MODEL USING *) PREDICTED_VALUE,
PREDICTION_PROBABILITY(MD_GLM_MODEL USING * ) PROB, STRENGTH
FROM CONCRETE_TEST
);
은닉층의 수를 1개에서 2개로 늘리니 상관관계 계수가0.94 에서0.95로 올라갔음 (성능이 더 좋아짐)
★ 마지막문제. 위의 신경망의 뉴런수와 은닉층의갯수를조정해서 더 성능이 좋은 신경망이되게끔하시오. -> 적당한 뉴런수와 은닉층의갯수는사람이직접알아내야됨(chat gpt에서그게됨)
-- 1. 인공신경망의 구조를 은닉1층에서 은닉2층으로 재구성합니다.
DROP TABLE SETTINGS_GLM;
CREATE TABLE SETTINGS_GLM
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_GLM(SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.ALGO_NAME, DBMS_DATA_MINING.ALGO_NEURAL_NETWORK);
INSERT INTO SETTINGS_GLM (SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.PREP_AUTO, DBMS_DATA_MINING.PREP_AUTO_ON);
INSERT INTO SETTINGS_GLM (SETTING_NAME, SETTING_VALUE)
VALUES (DBMS_DATA_MINING.NNET_NODES_PER_LAYER, '50,50');
END;
/
select * from SETTINGS_GLM;
-- 2. 머신러닝 모델을 생성합니다.
BEGIN
DBMS_DATA_MINING.DROP_MODEL('MD_GLM_MODEL');
END;
/
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
MODEL_NAME => 'MD_GLM_MODEL',
MINING_FUNCTION => DBMS_DATA_MINING.REGRESSION,
DATA_TABLE_NAME => 'CONCRETE_TRAIN',
CASE_ID_COLUMN_NAME => 'C_ID',
TARGET_COLUMN_NAME => 'STRENGTH',
SETTINGS_TABLE_NAME => 'SETTINGS_GLM');
END;
/
-- 3. 인공신경망의 환경 구성정보를 확인합니다.
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_GLM_MODEL'
AND SETTING_NAME IN ('NNET_HIDDEN_LAYERS','NNET_NODES_PER_LAYER');
-- 4. 신경망 모델이 예측한 결과를 확인합니다.
SELECT C_ID, STRENGTH 실제값, ROUND( PREDICTION(MD_GLM_MODEL USING *),2) 예측값
FROM CONCRETE_TEST;
-- 5. 실제 값과 예측 값 간의 상관관계를 확인합니다.
SELECT ROUND(CORR(PREDICTED_VALUE, STRENGTH),2) 상관관계
FROM (
SELECT C_ID, PREDICTION(MD_GLM_MODEL USING *) PREDICTED_VALUE,
PREDICTION_PROBABILITY(MD_GLM_MODEL USING * ) PROB, STRENGTH
FROM CONCRETE_TEST
);