@democreate index emp_ename on emp(ename); 1) 튜닝 전 (12개)
select ename, sal
from emp
order by ename asc;
2) 튜닝후 (2개)
select ename, sal
from emp
where ename > ' ' ;
[TIL 24] 240617
[sql 포트폴리오] 1. 어떤 데이터 분석인지 질문 2. 데이터셋 소개 3. 어떻게 분석을 했는지 설명과 관련 코드들 4. 결론
8. 그룹함수 대신 인덱스를 사용하기
예제 8. 그룹 함수 대신 인덱스를 사용하기. 그룹함수도 정렬작업이 내부적으로 발생한다. 정렬 작업을 최소화하기 위해서 인덱스를 활용을 해서 sql을 작성하는 게 권장합니다.
Q1. 최대월급을 출력하고 실행계획을 보시오.
select max(sal)
from emp;
explain plan for
select max(sal)
from emp;
select * from table(dbms_xplan.display);
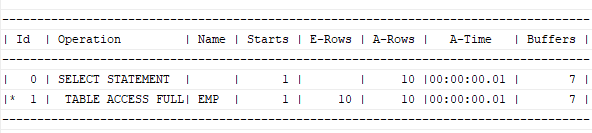
설명: sort aggregate가 실행계획에 나오면서 정렬작업을 내부적으로 수행했다는 것을 확인할 수 있음.
※ 전체 범위 처리와 부분 범위 처리라는 용어를 알고 있어야 됨
1.전체 범위 처리
테이블 전체를 다 읽어야 결과를 볼 수 있는 SQL (full table scan)
select max(sal)
from emp;
2. 부분 범위 처리
테이블이나 인덱스의 일부분만 읽어서도 결과를 볼 수 있는 SQL
create index emp_sal on emp(sal);
select /*+ indec_desc(emp emp_sal) */ sal
from emp
where sal >=0 and rownum =1;
문제 1. 아래의 sql을 부분범위 처리가 되도록 튜닝하시오! 1) 튜닝 전
select max(hiredate)
from emp;
2) 튜닝 후
select /*+ index_desc(emp emp_hiredate) */ hiredate
from emp
where hiredate < to_date('9999/12/31','RRRR/MM/DD') and rownum=1;
설명: 튜닝 전 sql은 인덱스가 hiredate에 있든 없든 간에 full이라는 키워드가 실행계획에 나옴 (but, 부분 범위 처리로 유도하는 게 OLTP 환경에서는 더 검색성능이 좋음)
1. OLTP 환경 DB ( online transaction processing)
쿠팡이츠로 주문을 했으면 지금 주문이 주문 테이블 insert 하게 되면서 insert라는 트랜잭션이 발생합니다. 그리고 이 주문을 조회하는 쿼리문이 수행이 되는데 이 쿼리문이 빨리 검색이 되어야 합니다.
select ename, sal from emp where sal = (select max(sal) from emp);
2. DW 환경 DB (data warehouse)
쿠팡에서 밤 12시부터 새벽 시간에 지난 하루동안에 있었던 주문을 분석해서 사람들이 어떤 걸 좋아하고 앞으로 우리가 어떤 것을 준비해야 하는지 분석하는 SQL을 돌리는데 이게 시간이 많이 걸립니다. 이 SQL 은 전체 범위 처리를 할 수밖에 없는 SQL 이 많습니다.
select /*+ index_desc(emp emp_sal) */ ename, sal from emp where sal > 0 and rownum =1;
문제 2. 다음의 전체 범위 처리를 하는 sql을 부분범위 처리로 튜닝하시오.
1)튜닝전
select ename, sal
from emp
where sal = (select max(sal)
from emp);
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: 서브쿼리를 먼저 수행면서 index를 full로 스캔함. (min/max)가 나왔다는 것은 min 또는 max 함수를 사용하는 쿼리에 대해 특정열의 가장 작은 값이나 가장 큰 값을 찾기 위해 최적화된 스캔 유형임. 그런데 부분범위 처리를 했다는 것은 아니고 전체범위를 처리를 하지만 결과적으로 필요한 값을 빠르게 추출하는 최적화된 접근 방법임.
2) 튜닝후
select /*+ index_desc(emp emp_sal) */ ename, sal
from emp
where sal >= 0 and rownum =1;
설명: 튜닝 전은 index full scan이라는 실행 계획이 나오면서 전체 범위를 처리함. 튜닝 후에는 index range scan과 count stop key가 나오면서 부분 범위 처리를 함.
문제 3. 아래의 sql을 부분범위 처리로 유도하시오.
1) 튜닝전
select ename, hiredate
from emp
where hiredate = ( select max(hiredate)
from emp );
2) 튜닝후
select /*+ index_desc(emp emp_hiredate) */ ename, hiredate
from emp
where hiredate < to_date('9999/12/31', 'RRRR/MM/DD') and rownum =1
9. 인덱스를 액세스 하지 못하는 검색조건
예제 9. 인덱스를 액세스 하지 못하는 검색조건을 알아야 됨. where 절에 다음과 같은 검색조건이 있으면 인덱스를 엑세스 하지 못함.
인덱스를 엑세스 하지 못하는 검색조건
1. is null / is not null
2. like 검색 시의 % 를 앞에 사용한 경우
3. 부정연산자 (!=, <>, ^=)
4. 인덱스 칼럼을 가공했을 때
Q1. COMM이 NULL인 사원들의 이름과 COMM을 출력하시오.
create index emp_comm on emp(comm);
select ename, comm
from emp
where comm is null;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: comm의 index를 걸어 놨는데도 불구하고 full index로 실행됨.
Q2. 위 SQL을 튜닝하시오(함수기반 인덱스 생성)
create index emp_comm_func
on emp (nvl(comm, -1));
select ename, comm
from emp
where nvl(comm, -1) = -1;
문제 1. 이름의 끝글자가 t로 끝나는 사원들의 이름, 월급을 출력하시오. 1) 튜닝 전
create index emp_ename on emp(ename);
select ename, sal
from emp
where ename like '%T'
2) 튜닝 후
create index emp_ename_func
on emp(substr(ename,-1,1));
select ename, sal
from emp
where substr(ename,-1,1)='T';
문제 2. 우리 반 테이블에서 주소가 읍으로 끝나는 학생들의 이름, 주소를 출력하는 쿼리문을 튜닝 후 sql로 작성하시오.
1)튜닝전
select ename, address
from emp19
where address like '%읍%';
2) 튜닝후
create index emp_address_func
on emp19(substr(address,-1,1));
select ename, address
from emp19
where substr(address,-1,1)='읍';
문제 3. 직업에 인덱스를 걸고 salesman이 아닌 사원들의 이름, 직업을 출력하는 sql의 실행 계획을 확인하시오.
create index emp_job on emp(job);
select ename, job
from emp
where job <> 'SALESMAN';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
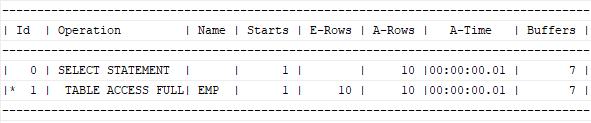
설명: 이경우는 full table scan을 할 수밖에 없어서 full table scan을 빠르게 수행하게 하는 튜닝방법을 사용해야 함.
10. full table scan을 빠르게 수행하는 방법
예제 10. full table scan을 할 수밖에 없어서 full table scan을 빠르게 수행하게 하는 튜닝방법
※ full table scan을 할 수밖에 없는 경우
1. where 절이 아예 없거나 인덱스가 없는 칼럼의 데이터를 검색할 때
2. 인덱스를 생성할 때
3. 검색조건이 부정문일 때 (!=, <>,^=)
4. 테이블의 통계정보를 수집할 때
-> full table scan을 할 수밖에 없다면 full table scan을 빠르게 수행하면 됨 (대표적: 병렬 쿼리)
Q1. 아래의 SQL이 병렬 쿼리가 되도록 힌트를 주시오
1) 튜닝전
select ename, sal, job
from emp
where job!='SALESMAN';
2) 튜닝후
select /*+ full(emp) parallel(emp,4) */ ename, sal, job
from emp
where job!='SALESMAN';
설명: FULL이라는 힌트를 FULL TABLE SCAN 하라는 힌트임. (parallel(테이블명, 병렬도)를 써서 병렬도의 개수만큼 프로세서를 띄워서 full scan을 함
Q2. 병렬도를 몇 개까지 줄 수 있는지 확인하시오. - 20 * 2 =40개까지 줄 수 있음
show parameter cpu_count
문제 1. 아래 sql을 병렬로 full table scan 하는데 병렬도를 12로 하고 수행하시오.
1) 튜닝전
select ename, sal, job
from emp
where deptno <>10;
2) 튜닝후
select /*+ full(emp) parallel(emp,12) */ ename, sal, job
from emp
where deptno <>10;
문제 2. 아래 sql을 튜닝하시오. (병렬)
1) 튜닝전
select job, count(*)
from emp
group by job;
2) 튜닝후
select /*+ full(emp) parallel(emp,12) */ job, count(*)
from emp
group by job;
11. 인덱스를 할 수 있도록 힌트
예제 11. 인덱스를 할 수 있도록 힌트를 사용하세요. -> index라는 힌트가 있는데 이 힌트를 이용하면 인덱스를 액세스 할 수 있도록 실행계획을 생성할 수 있습니다.
@demo
create index emp_sal on emp(sal);
select /*+ index(emp emp_sal) */ ename, sal
from emp
where sal = 3000;
※ index힌트를 사용해야 하는 경우
1. 인덱스가 있음에도 불구하고 full table scan을 하는 경우
2. where 절에 검색조건이 여러 개가 and로 연결되어 있을 때 그중 하나의 칼럼의 인덱스를 선택하게 하고 싶을 때
Q1. 다음과 같이 2개의 인덱스를 생성하고 아래의 SQL의 실행계획을 확인하시오.
create index emp_deptno on emp(deptno);
create index emp_job on emp(job);
select ename, sal, deptno, job
from emp
where deptno =20 and job ='ANALYST';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: ㅡ똑똑한 옵티마이져 (스스로 학습하는 옵티마이져) 이면 emp_job 인덱스를 선택했을 겁니다. 왜냐하면 emp_job 인덱스를 통해서는 2개의 행만 액세스 하면 되지만 emp_deptno 인덱스를 통해서 액세스 하면 5개를 찾은 다음 그다음에 직업이 ANALYST 인 2건을 걸러냅니다. 그래서 옵티마이져는 비용이 적게 드는 인덱스를 선택합니다. 그런데 만약에 옵티마이져가 emp_deptno 인덱스를 선택했다면 사람이 힌트를 줘서 emp_job 인덱스를 선택하게 해야 합니다.
예: select /*+ index( emp emp_job) */ ename, sal, job, deptno
from emp
where job='ANALYST' and deptno = 20;
문제 1. 아래의 SQL의 인덱스를 EMP_DEPTNO를 선택하게 힌트를 주고 실행하시오.
1) 튜닝전
select ename, sal, job, deptno
from emp
where job='ANALYST' and deptno =20;
2) 튜닝후
select /*+ index emp emp_deptno)*/ename, sal, job, deptno
from emp
where job='ANALYST' and deptno =20;
문제 2. 우리 반 테이블의 다음과 같이 인덱스를 생성하고 아래의 sql이 여러 개의 인덱스 중 가장 좋은 인덱스를 선택할 수 있도록 힌트를 주고 실행하시오.
1) 튜닝전
create index emp19_age on emp19(age);
create index emp19_gender on emp19(gender);
select ename, age, gender
from emp19
where gender = '여'and age =26;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
select /*+ index emp19 emp19_age)*/ ename, age, gender
from emp19
where gender = '여'and age =26;
설명: 위와 같이 index라는 힌트를 사용해서 실행계획을 고정시키는 경우는 앞으로 age가 gender의 데이터 변화가 생기지 않는다는 가정하에 고정시킵니다.
12. 좋은 인덱스 2개 함께 사용하기.
예제 12. 훌륭한 인덱스 2개를 같이 사용하여 시너지 효과를 볼 수 있다. (index merge scan)
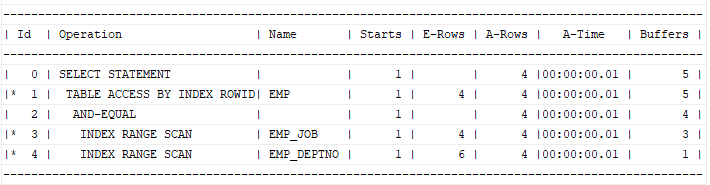
설명: 두 개의 인덱스를 같이 스캔해서 "테이블 랜덤 액세스"를 줄인 스캔 방법입니다. 만약에 col1 인덱스만 스캔했다면 총 6번의 인덱스를 통한 테이블 랜덤액세스를 해야 하고 col2 인덱스만 스캔했다면 총 12번의 인덱스를 통한 테이블 랜덤 액세스를 해야합니다. 그리고 나서 테이블에 가서 두 개의 컬럼 조건에 다 만족하는 2개의 데이터를 찾아냅니다. 그런데 이렇게 하지 말고 그냥 col1 의 인덱스와 col2 의 인덱스를 두개를 동시에 같이 스캔해서 테이블 랜덤 엑세스를 2번으로 줄이는 스캔 방법이 index merge scan입니다.
Q1.
create index emp_deptno on emp(deptno);
create index emp_job on emp(job);
select /*+ and_equal(emp emp_deptno emp_job) */ ename, job, deptno
from emp
where deptno = 30 and job='SALESMAN';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: 하나의 인덱스를 사용했을 때보다 두 개의 인덱스를 사용했을 때 더 성능이 좋을 때 사용
문제 1. 아래의 인덱스를 걸고 아래의 SQL이 2개의 인덱스를 같이 사용하는 INDEX MERGE SCAN 이 되게 하시오.
1) 튜닝전
create index emp19_gender on emp19(gender);
create index emp19_telecom on emp19(telecom);
select ename, age, gender, telecom
from emp19
where gender ='남' and telecom ='sk';
1) 튜닝후
select /*+ and_equal(emp19 emp19_gender emp19_telecom) */ ename, age, gender, telecom
from emp19
where gender ='남' and telecom ='sk';
13. 결합칼럼 인덱스
예제 13. 테이블 랜덤 액세스를 줄이기 위해 결합 칼럼 인덱스를 사용하세요. : 단일 칼럼 인덱스보다 결합 컬럼 인덱스를 사용하는 것이 인덱스를 통한 테이블 랜덤 인덱스를 줄일 수 있습니다.
Q1. EMP테이블에 DEPTNO와 JOB에 결합 칼럼 인덱스를 거시오
create index emp_deptno_job
on emp(deptno, job);
Q2. EMP_DEPTNO_JOB이 덱스가 어떻게 생겼는지 구조를 확인하시오. ; 인덱스는 칼럼값 + ROWID로 구성되어 있음(ex. 책의 목차)
select deptno, job, rowid
from emp
where deptno>=0;
설명: 부서번호를 먼저 정렬해 놓은 것을 기준으로 직업을 abcd 순으로 정렬하고 있습니다.
Q3. 아래 SQL이 단일 칼럼 인덱스를 사용할 때와 결합칼럼 인덱스를 사용할 때의 차이가 무엇이겠는가?
select *
from tab1
where co1='ABC' and col2='123';
설명: col 단일 칼럼 인덱스만 사용했다면 6번을 테이블 액세스를 하러 가서 그중에 col2가 123인 것을 찾아내야 합니다. 근데 col1+col2 결합 칼럼 인덱스를 이용한다면 테이블 액세스를 2번만 하면 됩니다.
Q4. 아래의 실습환경을 만들고 다음의 SQL이 아래의 3개 INDEX 중에 어느 INDEX를 옵티마이져가 선택할지 확인하시오.
create index emp_deptno on emp(deptno);
create index emp_job on emp(job);
create index emp_deptno_job on emp(deptno,job);
select ename, sal, job, deptno
from emp
where deptno=20 and job = 'ANALYST';
설명: 결합칼럼 인덱스르 선택하면서 버퍼의 개수는 2개이다.
문제 1. 아래의 SQL이 emp_deptno인덱스를 선택하게 힌트를 주고 실행하고 버퍼의 개수가 몇 개인지 확인하시오 -2개
select /*+ index em emp_deptno)*/ename, sal, job, deptno
from emp
where deptno=20 and job = 'ANALYST';
문제 2. 아래의 환경을 만드시오!
create table mcustsum
as
select rownum custno
, '2008' || lpad(ceil(rownum/100000), 2, '0') salemm
, decode(mod(rownum, 12), 1, 'A', 'B') salegb
, round(dbms_random.value(1000,100000), -2) saleamt
from dual
connect by level <= 1200000 ;
create index m_salegb on mcustsum(salegb);
create index m_salemm on mcustsum(salemm);
create index m_salegb_salemm on mcustsum(salegb,salemm);
문제 3. 아래의 SQL이 m_salegb 인덱스를 선택할 수 있도록 힌트를 주고 실행하시오! 그리고 실행계획도 확인하시오!
select count(*)
from mcustsum t
where salegb ='A'
and salemm between '200801' and '200812';
답:
select /*+ index( t m_salegb ) */ count(*)
from mcustsum t
where salegb ='A'
and salemm between '200801' and '200812';
단일컬럼 버퍼 4000개이
문제 4. 결합 칼럼 인덱스를 사용하게끔 힌트를 주고 실행하고 버퍼의 개수를 확인하세요!
select count(*)
from mcustsum t
where salegb ='A'
and salemm between '200801' and '200812';
-- 답 281개
select /*+ index( t m_salegb_salemm ) */ count(*)
from mcustsum t
where salegb ='A'
and salemm between '200801' and '200812';
14. 결합 칼럼 인덱스 칼럼순서
예제 14. 결합 칼럼 인덱스 구성시 칼럼순서가 중요하다.
설명: col+col2 인덱스가 col2+col1 결합 인덱스보다 인덱스를 짧게 스캔하면서 원하는 결과를 검색하고 있습니다. 그래서 결합 칼럼 인덱스 생성 시 칼럼 순서가 중요합니다.
예를 들어 다음과 같이 쿼리문을 있다고 하면
select *
from tab1
where col1 ='A' -- 점 조건
and col2 between '111' and '113'; -- 선분조건
1. 점조건
= 이나 in을 사용
2. 선분조건
between...and 나 like 를 사용
★ 점조건이 있는 컬럼을 결합 컬럼 인덱스의 첫번째 컬럼으로 구성을 하는게 선분 조건이 있는 컬럼을 첫번째 컬럼으로 구성하는 것 보다 더 인덱스를 짧게 스캔할 수 있어서 성능이 더 좋음
문제 1. 아래의 환경을 구성하시오!
drop table mcustsum purge;
create table mcustsum
as
select rownum custno
, '2008' || lpad(ceil(rownum/100000), 2, '0') salemm
, decode(mod(rownum, 12), 1, 'A', 'B') salegb
, round(dbms_random.value(1000,100000), -2) saleamt
from dual
connect by level <= 1200000 ;
create index m_salegb_salemm on mcustsum(salegb,salemm);
create index m_salemm_salegb on mcustsum(salemm,salegb);
문제 2. 아래의 select 문을 실행하는데 m_salegb_Salemm 인덱스를 이용할 수 있도록 힌트를 주시오.
select count(*)
from mcustsum t
where salegb='A'
and salemm between '200801' and '200812';
답:
select /*+ index( t m_salegb_salemm) */ count(*)
from mcustsum t
where salegb='A'
and salemm between '200801' and '200812';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 3. 이번에는 선분조건을 선두 칼럼에 둔 m_salemm_salegb 인덱스를 액세스 하게끔 힌트를 주시오!
select /*+ index( t m_salemm_salegb )
no_index_ss( t m_salemm_salegb ) */ count(*)
from mcustsum t
where salegb='A'
and salemm between '200801' and '200812';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: 일부러 index skip scan을 하지 못하게 index_ss라는 힌트를 줌 그래서 그냥 m_salesmm_salegb 인덱스를 range 스캔하게 했더니 2767개의 버퍼를 읽어 들이고 있음
문제 4. 아래의 환경을 구성하고 아래의 sql을 튜닝하시오
create index emp_deptno_job on emp(deptno,job);
create index emp_job_deptno on emp(job,deptno);
1) 튜닝전
select /*+ index(emp emp_deptno_job ) */ count(*)
from emp
where deptno between 10 and 30
and job ='CLERTK';'
2) 튜닝후
select /*+ index(emp emp_job_deptno) */ count(*)
from emp
where deptno between 10 and 30
and job ='CLERK';
테이블이 작어서 버퍼의 갯수는 차이가 나지 않지만 점조건이 선두 컬럼으로 있는
결합 컬럼 인덱스를 선택하는게 더 성능에 좋습니다.
문제 5. 선두 칼럼이 선분조건인 결합 컬럼 인덱스만 있는 상태에서 아래의 sql을 튜닝하시오.
튜닝전: select /*+ index( t m_salemm_salegb)
no_index_ss( t m_salemm_salegb ) */ count(*)
from mcustsum t
where salegb ='A'
and salemm between '200801' and '200812';
튜닝후: 선분조건을 점조건으로 변경해서 SQL을 재작성합니다.
select /*+ index( t m_salemm_salegb)
no_index_ss( t m_salemm_salegb ) */ count(*)
from mcustsum t
where salegb ='A'
and salemm in ('200801', '200802', '200803', '200804', '200805',
'200806', '200807', '200808', '200809', '200810',
'200811', '200812');
설명: col2 between 111 and 112 이면 111과 112 사이에는 111.1 있을 수도 있고 111.2 가 있을 수 도 있으므로 col2+col1 의 결합 컬럼 인덱스를 많이 넓게 스캔해야합니다. 그런데 col2 in (111, 112) 이면 col2 가 111 과 col2 가 112 만 스캔하면서 col1 이 A 인 것을 찾으면 끝납니다.
★ 마지막 문제 : 튜닝하시오.
create index emp19_age_telecom on emp19(age, telecom);
1) 튜닝전
select ename, age, telecom
from emp19
where telecom in ('sk', 'kt')
and age between 25 and 30;
2) 튜닝후
select /*+ index(emp19 emp19_age_telecom) */ ename, age, telecom
from emp19
where telecom in ('sk', 'kt')
and age in(25,26,27,28,29,30);