select ename, age, telecom
from emp19
where age = 24 and telecom ='sk';
실행계획을 확인하고 인덱스를 생성한 후 같은 SQL의 실행계획을 확인해서 버퍼의 개수가 줄었는지 확인하세요.
(튜닝 후)_ 유니크한 칼럼이 앞에 있는 결합 칼럼을 만듦
1) 결합 인덱스 생성
create index emp19_age_telecom on emp19(age,telecom);
2) 튜닝
select /*+ index emp19 emp19_age_telecom */ ename, age, telecom
from emp19
where age = 24 and telecom ='sk';
3) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
15. index skip scan
예제 15. index skip scan을 사용하시오. : index skip scan을 이해하려면 결합 칼럼 인덱스가 어떤 SQL에서 사용될 수 있는지를 먼저 이해해야 됨 결합 칼럼 인덱스는 결합 컬럼 인덱스의 첫번째컬럼이 WHERE 절에 있어야지만 그 SQL이 결합 컬럼 인덱스를 사용할 수 있음. Q1. 결하칼럼 인덱스의 첫 번째 칼럼이 WHERE절에 없으면 FULL TABLE SCAN을 하는지 확인하기.
create index emp_deptno_job
on emp(deptno, job) ;
select ename, job, deptno
from emp
where job='MANAGER';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: 결합칼럼 index는 deptno+job 으로 되어있는데 select 절에서 검색되는 컬럼은 job만 있으며 인덱스를 사용하지 못하고 full table scan을 하게 됩니다. 결합 컬럼 인덱스의 첫번째컬럼이 반드시 where 절 있어야 결합 컬럼 인덱스를 사용할 수 있게 됩니다.
설명:emp_deptno_job 인덱스에서 부서번호 10번부터 스캔하면서 읽어가는데 job 이 manager를 찾았으면 바로 테이블 액세스를 하러 가고 그다음이 manager 가 아니면 나머지는 스킵합니다. 그리고 20번을 스캔하러 갑니다. 20번도 마찬가지로 직업이 MANAGER를 찾았으면 바로 테이블 액세스하러 가고 나머지는 스킵합니다. (스킵을 많이 할수록 full table scan 보다 성능이 좋음 )
Q2. 아래의 SQL이 인덱스 스킵스캔을 하는지 실행계획을 확인하시오.
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
select /*+ index_ss(emp emp_deptno_job) */ ename,deptno, job
from emp
where job ='MANAGER';
설명: 버퍼 7개 -> 2개
문제 1. 아래 환경을 만드시오.
drop table mcustsum purge;
create table mcustsum
as
select rownum custno
, '2008' || lpad(ceil(rownum/100000), 2, '0') salemm
, decode(mod(rownum, 12), 1, 'A', 'B') salegb
, round(dbms_random.value(1000,100000), -2) saleamt
from dual
connect by level <= 1200000 ;
create index m_salemm_salegb on mcustsum(salemm,salegb);
문제 2. 아래 sql을 튜닝하시오
create index m_salemm_salegb on mcustsum(salemm,salegb);
(튜닝전)
select count(*)
from mcustsum t
where salegb ='A';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: index fast full scan 실행계획이 나왔는데 full table scan 보다는 좀 더 빠른 실행계획입니다. (버퍼 개수: 336개) salegb 이 결합 칼럼 인덱스의 두 번째 칼럼이어서 index range scan을 하지 못한 겁니다. 부분범위 처리를 해야 하는데 전체범위처리를 한 것입니다.
(튜닝후)
select /*+ index_ss(t m_salemm_salegb) */ count(*)
from mcustsum t
where salegb ='A';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
create index emp_job_sal
on emp(job,sal);
select ename, job, sal
from emp
where sal = 1250;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: emp_job_sal 인덱스가 있어도 full scan이 된 이유는 where 절에 인덱스 첫 번째인 job 칼럼이 아닌 sal이 있기 때문
select /*+ index_ss( emp emp_job_sal ) */ ename, job, sal
from emp
where sal = 1250;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
※ (SQL 전문가 시험) index skip scan의 효과를 보려면 결합 칼럼 인덱스의 첫 번째 칼럼의 종류가 몇 가지 안 되어야 효과가 좋습니다.
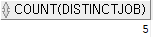
문제 5. job + sal으로 만들어진 결합 칼럼인덱스의 효과를 보기 위해서 직업의 종류가 몇 개인지 조회해 봅니다.
select count(distinct job)
from emp;
문제 6. deptno + sal의 결합 칼럼인덱스의 효과를 보기 위해서 deptno의 종류가 몇 개인지 조회해 봅니다.
select count(distinct deptno)
from emp;
16. index full scan
예제 16. index full scakm을 사용하기. : 인덱스 full scan 은 인덱스의 구조에 따라 전체를 스캔하는 스캔 방법입니다. 대용량 테이블의 데이터를 빠르게 count 하고 싶을 때 주로 사용합니다.
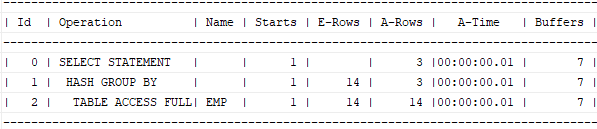
Q1. 직업, 직업별 인원수를 출력하시오
create index emp_job on emp(job);
select job, count(*)
from emp
group by job;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: full table scan을 하면서 버퍼의 개수가 7개가 됨
Q2. 위의 실행계획을 index full scan으로 유도하시오. (not null 제약 사용)
1) not null 제약 걸기
alter table emp
modify job constraint emp_job_nn not null;
select table_name, constraint_name
from user_constraints
where table_name ='EMP';
2) 실행계획 확인
select job, count(*)
from emp
group by job;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 1. 아래의 sql을 검색속도를 높이시오. (7개->2개)
1) 튜닝전
select deptno, count(*)
from emp
group by deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
alter table emp
modify deptno constraint emp_deptno_nn not null;
select deptno, count(*)
from emp
group by deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
+) not null 제약을 걸수 없다면?
select deptno, count(*)
from emp
where deptno is not null
group by deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
* 제약 삭제 (drop constraint)
alter table emp
drop constraint emp_deptno_nn;
문제 2. 직업, 직업별 토털월급을 출력하는데 index full scan 이 될 수 있도록 인덱스도 걸고 sql도 작성하시오.
create index emp_job_sal on emp(job,sal);
select job, sum(sal)
from emp
where job is not null
group by job;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: order by를 안 걸었는데 abcd 순으로 나열되고 있음 -> index full scan 이 되었기 때문.
17. index fast full scan
예제 17. index fast full scan 을 사용하시오
: index fast full scan 은 index full scan 처럼 table full scan 보다 빠르게 데이터를 검색해낸다.( index fast full scan 이 index full scan 보다 더 빠름)
index fast full scan > index full scan > table full scan
※ 왜 index fast full scan 이 index full scan 보다 더 빠른가?
1. 데이터를 정렬하지 않음
2. single block i/o 가 아니라 muti block i/o를 합니다.
예) 책의 목차가 50장이 있으면 목차를 full 로 스캔하고 만약 싱글 블럭 i/o를 한다면 책장을 한번 넘길때 1장씩 넘기는거고 multi block i/o를 한다면 책장을 한번 넘길때 10장씩 넘기는겁니다.
문제 1. 직업, 직업별 토탈월급 출력하는데 index fast full scan이 되게하시오.
create index emp_job_sal on emp(job,sal);
1) 튜닝전
select job,sum(sal)
from emp
where job is not null
group by job;
2) 튜닝 후
select /*+ index_ffs(emp emp_job_sal)*/ job,sum(sal)
from emp
where job is not null
group by job;
문제 2. 부서번호, 부서번호별 토탈월급을 출력하는데 아래의 쿼리 결과가 index full scan 했을 때와 index fast full scan 을 했을 대 정렬된 결과 차이가 있는지 확인하시오.
1) 튜닝전
select deptno, sum(sal)
from emp
group by deptno;
2) 튜닝후
select /*+ index_ffs(emp emp_deptno_sal)*/ deptno, sum(sal)
from emp
where deptno is not null
group by deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 3. 아래의 환경을 구성하고 salegb 별 salegb 별 토탈salesamt 를 출력하시오
drop table mcustsum purge;
create table mcustsum
as
select rownum custno
, '2008' || lpad(ceil(rownum/100000), 2, '0') salemm
, decode(mod(rownum, 12), 1, 'A', 'B') salegb
, round(dbms_random.value(1000,100000), -2) saleamt
from dual
connect by level <= 1200000 ;
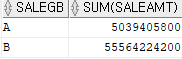
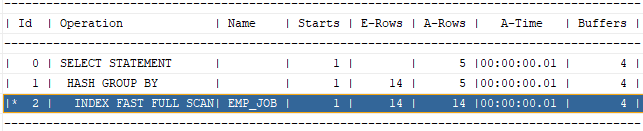
create index m_salegb_saleamt on mcustsum(salegb, saleamt);
select /*+ index(m m_salegb_saleamt) */ salegb, sum(saleamt)
from mcustsum m
where salegb is not null
group by salegb;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
select /*+ index_ffs(m m_salegb_saleamt) */ salegb, sum(saleamt)
from mcustsum m
where salegb is not null
group by salegb;
설명:index fast full scan은 index full scan 과는 다르게 정렬을 안하기 때문에 결과가 더 빨리 출력됩니다.
문제 4. index fast full scan 을 더 빠르게 하는 방법을 이용해서 직업과 직업별 인원수를 출력하시오.
create index emp_job on emp(job);
select /*+ index_ffs(emp emp_job) parallel_index(emp, emp_job, 16) */
job, count(*)
from emp
where job is not null
group by job;
설명: paralle_index(테이블명, 인덱스 이름, 병렬도) 로 힌트를 주게 되면 인덱스를 여러 프로세서들이 동시에 나눠서 병렬로 스캔합니다.
문제 5. 아래의 쿼리의 인덱스를 index fast full scan 하고 병렬로 스캔할 수 있게 하시오 !
@demo
create index emp_deptno on emp(deptno);
튜닝전: select deptno, count(*)
from emp
group by deptno;
튜닝후: select /*+ index_ffs(emp emp_deptno) parallel_index(emp, emp_deptno,16) */
deptno, count(*)
from emp
where deptno is not null
group by deptno;
18. index bitmap merge scan
예제. index bitmap merge scan을 사용하시오 설명: 두개의 인덱스를 같이 스캔해서 테이블 엑세스를 줄이는 방법이 앞에서 배웠던 index merge scan 입니다. index bitmap merge scan 은 index merge 와 방식은 똑같은데 인덱스를 bitmap 으로 변환해서 인덱스의 사이즈를 아주 많이 줄인 다음 인덱스를 merge 하는게차이 입니다. 인덱스의 사이즈가 작아지므로 인덱스를 스캔하는 시간이 짧아집니다.
그림 설명: index bitmap merge scan 은 일반 b tree 인덱스 2개를 각각 bitmap index 로 변환해서 크기를 작게 만든 다음이 2개의 bitmap 인덱스를 하나의 bitmap 인덱스로 합친 인덱스를 스캔하는 스캔방법입니다.
문제 1. 아래의 환경을 만들고 index merge scan 하시오
@demo
create index emp_job on emp(job);
create index emp_deptno on emp(deptno);
튜닝전:
select /*+ and_equal( emp emp_job emp_deptno) */ empno, ename, job, deptno
from emp
where deptno = 30 and job='SALESMAN';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
-> 버퍼의 갯수를 5개를 읽고 있습니다.
문제 2. 위의 SQL을 index bitmap merge scan 이 되게 하시오 !
튜닝후:
select /*+ index_combine(emp) */ empno, ename, job, deptno
from emp
where deptno = 30 and job='SALESMAN';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 3. 아래의 환경을 만들고 아래의 sql을 튜닝하시오
drop table mcustsum purge;
create table mcustsum
as
select rownum custno
, '2008' || lpad(ceil(rownum/100000), 2, '0') salemm
, decode(mod(rownum, 12), 1, 'A', 'B') salegb
, round(dbms_random.value(1000,100000), -2) saleamt
from dual
connect by level <= 1200000 ;
create index m_indx1 on mcustsum(custno);
create index m_indx2 on mcustsum(salemm);
create index m_indx3 on mcustsum(salegb);
1) 튜닝전
select /*+ and_equal(t m_indx2 m_indx3) */ count(*)
from mcustsum t
where salegb='A'
and salemm ='200801';
2)튜닝후
select /*+ index_combine(t) */ count(*)
from mcustsum t
where salegb='A'
and salemm ='200801';
--> index bitmap merge 스캔을 했던 버퍼의 갯수가17245 에서 395로 줄어들었습니다.
19. index unique scan
예제 19. index unique scan 을 사용하세요. - unique 인덱스는 non unique 인덱스와는 다르게 컬럼의 값이 unique 해야지만 걸린다. ex) emp테이블의 경우 empno 같은 컬럼에 unique 인덱스가 걸린다
※ unique 인덱스를 생성하는 방법 2가지
1. 수동
: create uique index emp_ename_un on emp(ename);
2. 자동 ( primary key 제약이나 unique 제약)
: alter table emp add constraint emp_empno_pk primary key(empno);
* unique 인덱스 확인
select index_name, uniqueness
from user_indexes
where table_name='EMP';
문제1. 월급에는 non unique 인덱스를 생성하고 다음과 같이 SQL을 실행하면 오라클은 ename 에 걸린 unique 인덱스와 sal 에 걸린 non unique 인덱스중 어떤 인덱스를 선택할까 ?
create index emp_sal on emp(sal);
select empno, ename, sal
from emp
where ename='SCOTT' and sal = 3000;
만약 값이 중복되지 않았다면 non unique 인덱스 보다는 unique 인덱스를 걸어주는게 성능 향상을 위해 바람직합니다.
문제 2. 아래의 sql의 검색속도를 높이기 위한 가장 좋은 인덱스를 생성하시오.
1) 튜닝전
SELECT *
from emp19
where email ='constell85@naver.com';
2) 튜닝후
create unique index emp19_email
on emp19(email) ;
SELECT *
from emp19
where email ='constell85@naver.com';
★ 쪽지 시험 힌트 1. index access 방법 7가지중 하나를 선택해서 실행계획에 나오게끔 힌트를 선택하는 문제
20. 조인문장 튜닝 순서
예제 20. 조인문장을 튜닝할 때 조인 순서 튜닝이 중요합니다.
★ 조인문장 튜닝할 때 꼭 알아할 2가지 ?
:
★ 조인문장 튜닝할 때 꼭 알아할 2가지 ?
1. 조인 방법
1. nested loop join
조인하려는 데이터의 양이 많지 않을 때 유리한 조인방법
2. hash join
조인하려는 데이터의 양이 많을 때 유리한 조인 방법
3. sort merge join
조인하려는 데이터의 양이 많을 때 유리한 조인방법인데 연결고리의 키 컬럼을 기준으로 정렬까지 해서 결과를 봐야할 때 유용한 조인방법
2. 조인 순서
ordered 힌트
from 절에서 기술한 테이블 순서데로 조인해라 !
leading 힌트
leading 힌트 안에 쓴 테이블 순서데로 조인해라 !
문제 1. emp와 dept를 조인해서 이름과 부서위치를 출력하시오.
select e.ename, d.loc
from emp e, dept d
where e.deptno =d.deptno;
관련 설명 : emp ---> dept 순으로 조인하면 14번 조인 시도를 해야하는데 dept ---> emp 순으로 조인하면 4번 조인 시도 하면 됩니다.
문제 2. leading 힌트를 이용해서 아래의 2개의 조인순서를 조정하여 버퍼의 갯수를 비교하시오 ! 1. emp ------------> dept 2. dept ------------> emp
select /*+ leading(e d)use_nl(d) */ e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno ;
select /*+ leading(d e) use_nl(e) */ e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno ;
35개로 버퍼의 갯수가 줄어들었습니다.
문제 3. 아래의 sql을 튜닝하시오. (조인방법은 그대로 두고 순서만 변경)
1) 튜닝전
select /*+ leading (e s) use_nl(s) */ e.ename, e.sal, s.grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
select /*+ leading (s e) use_nl(e) */ e.ename, e.sal, s.grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal;
예제21. 검색조건에 따라 조인 순서를 잘 정해줘야합니다.
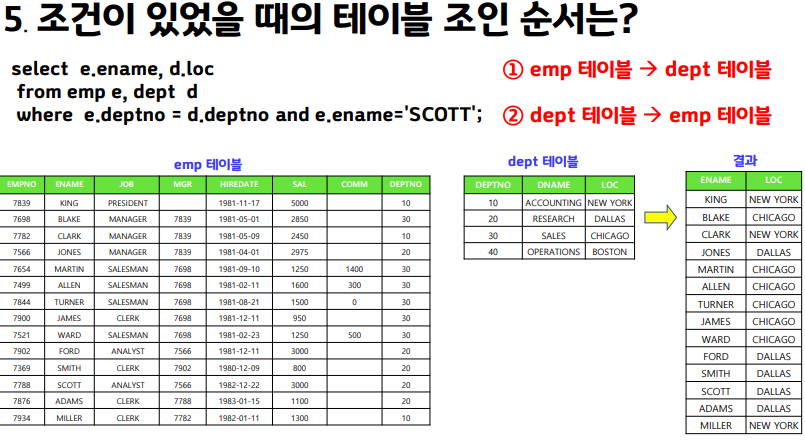
Q1. 이름이 SCOTT 인 사원의 이름과 부서위치를 출력하시오.
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno and e.ename ='SCOTT';
Q2. 위의 SQL 조인순서는 아래의 2가지중에 어떤게 좋을까요. (답2번) 1. dept --> emp 2. emp --> dept
만약 dept 를 먼저 읽고 emp랑 조인해야한다면 조인시도를 4번해야하지만 emp를 먼저 읽고 dept랑 조인한다면 1번만 조인시도하면 됩니다. 이름scott인 사원의 부서위치만 알면 되기 때문입니다.
문제1. 아래의 SQL의 조인방법은 무조건 NESTED LOOP 조인으로 하되 조인 순서를 emp ----> dept 순이 되게 하시오
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno and e.ename ='SCOTT';
답: select /*+ leading(e d) use_nl(d) */ e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno and e.ename ='SCOTT';
문제 2. 아래의 SQL의 가장 좋은 조인순서를 힌트로 정하시오 ! 조인 방법은 무조건 nested loop 조인이 되게 하세요 !
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno
and e.job ='SALESMAN' -- 4건
and d.loc ='CHICAGO'; -- 1건
답)
select /*+ leading(d e) use_nl(e) */ e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno
and e.job ='SALESMAN'
and d.loc ='CHICAGO';
문제 3. (대용량 테이블 join) 아래 sql을 튜닝하시오.
1) 환경 설정
create table sales200
as
select * from sh.sales;
create table times200
as
select * from sh.times;
2) 튜닝전
select /*+ leading(s t) use_nl(t) */ t.calendar_year, sum(amount_sold)
from sales200 s , times200 t
where s.time_id = t.time_id
and t.week_ending_day_id = 1582
group by t.calendar_year;
3) 튜닝후
select /* leading(t s) use_nl(s) */ t.calendar_year, sum(amount_sold)
from sales200 s , times200 t
where s.time_id = t.time_id
and t.week_ending_day_id = 1582
group by t.calendar_year;
예제 22. nested loop
예제22. 조인되는 데이터의 양이 작을 때는 nested loop조인으로 조인하세요 !
메모리에서 조인하는 해쉬조인을 쓰면 빠르게 조인할 수 있지만 회사의 database 는 나혼자 사용하는것이 아니라 여러 사람들이 같이 사용하므로 너도 나도 해쉬조인을 사용하겠다고 하면 다같이 느려집니다 조인되는 데이터의 양이 작으면 nested loop 조인으로 유도하고 조인되는 데이터의 양이 클때만 hash 조인을 사용하세요 !
※ 조인 방법 3가지 ?
1. nested loop join
use_nl 힌트
2. hash join
use_hash 힌트
3. sort merge join
use_merge 힌트
이중에서 nested loop 조인으로 조인할 때 가장 중요한 점은 조인의 연결고리 컬럼에 인덱스의 유무에 따라 성능이 크게 차이가 납니다. 그래서 nested loop 조인을 할때는 조인 연결고리 컬럼에 인덱스가 있는지 확인을 꼭 해야합니다. 없으면 걸어줘야합니다.
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno
문제 1. 연결고리 컬럼에 인덱스가 없었을때의 버퍼의 갯수 확인 하기
@demo
select /*+ leading(d e) use_nl(e) */ e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
35개의 버퍼를 읽어들이고 있습니다.
(튜닝후)
create index emp_deptno on emp(deptno);
create index dept_deptno on dept(deptno);
select /*+ leading(d e) use_nl(e) index(e emp_deptno) */ e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 2. 아래의 sql의join 순서는 무조건 nested loop 조인이 되게하는데 조인 연결고리가 되는 컬럼의 인덱스를 걸어서 버퍼의 갯수를 줄이시오 .
select /* leading(t s) use_nl(s) */ t.calendar_year, sum(amount_sold)
from sales200 s , times200 t
where s.time_id = t.time_id
and t.week_ending_day_id = 1582
group by t.calendar_year;
2) 튜닝후
create index sales200_id on sales200(time_id);
create index times200_id on times200(time_id);
select /* leading(t s) use_nl(s) index (s sales200_id) */ t.calendar_year, sum(amount_sold)
from sales200 s , times200 t
where s.time_id = t.time_id
and t.week_ending_day_id = 1582
group by t.calendar_year;