[빅데이터분석] SQL_TIL 22 (정규표현, regxpe,kaggle, random forest)
chonny
2024. 6. 13. 16:30
★점심시간문제 어제 마지막 문제로 만든 테이블에서 살인기수가 많이 일어나는 요일과 건수, 순위를 출력하는데 순위가 1등, 3등, 5등만 출력하시오!
select 요일, 건수, 순위
from (
select week_day AS 요일, c_cnt AS 건수,
dense_rank() over (order by c_cnt desc) as 순위
from crime_week_pivot
where c_small_type = '살인기수'
)
where 순위 in (1, 3, 5);
[TIL 22] 240613
복습 1. 테이블에 대한 설명이 있는지 알아보는 방법? -> 테이블 정의서를 열어보거나 user_tab_comments를 보면 됨됨
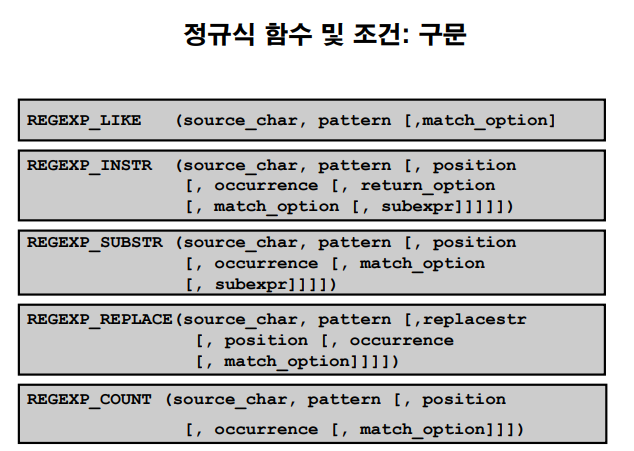
124. 정규표현
예제 124. 정규 표현식 오라클 함수 5가지
reqular expression support (정규 표현식)
1. regexp_like
select ename, sal from emp where regexp_like(ename, '(EN|IN)' );
2. regexp_replace
select ename, regexp_replace(sal, '[0-3]', '*') from emp;
3. regexp_substr
1) 숫자만 select ename, email, regexp_substr( email, '[[:digit:]]+') from emp19; 2) 문자만 select ename, email, regexp_substr( email, '[[:alpha:]]+') from emp19;
4. regexp_instr
select street_address, regexp_instr(street_address, '[[:alpha:]]') as 문자시작위치 from hr.locations;
5. regexp_count
SELECT REGEXP_COUNT ('123123123123', -- source char or search value '123', -- regular expression pattern 2, -- position where the search should start 'i') -- match option (case insensitive) As Count FROM dual;
reqular expression support의 약자로 정규 표현식이 라고 합니다. 정규 표현식이란 자바, 파이썬, c언어, 리눅스, 쉘 등 다른 프로그램언어에서도 동일한 표현을 쓰자고 약속한 표현식입니다.
※ 현업 tip 메트라이프 생명에서는 콜센터 상담원들이 상담하는 모든 내용을 다 녹취를 하고 잘못 상담내용이 있는지 없는지 다 조사해서 금융감독원에 보고를 하게 되어있습니다. 수많은 상담원들이 상담한 내용을 다 청취해서 분석한다는 것은 상당한 시간과 비용이 소요됩니다.
요청 메트라이프 생명 ----------------> 데이터 분석 회사
상담내용 --> 녹음 -----> 텍스트로 추출 ---> 오라클 데이터 베이스에 저장 ---> SQL과 파이썬으로 이용해서 분석을
예: 보험 가입 후 실효일이 30일 후입니다.라고 얘기해야 하는데 한 달이라고 애기했을면 잘못 공지해 준 것입니다.
문제 1. 사원이름에 en 또는 in이 포함되어 있는 사원들의 이름과 월급을 출력하시오.
1) LIKE를 이용하는 방법
select ename, sal
from emp
where ename like '%EN%' or ename like '%IN%';
2) REGEXP_LIKE를 이용하는 방법
select ename, sal
from emp
where regexp_like(ename, '(EN|IN)' );
문제 2. 우리 반에서 이름이 진우, 연우, 동현을 포함하는 이름과 나이를 출력하시오.
select ename, age
from emp19
where regexp_like(ename, '(연우|동현|진우)');
문제 3. 아래 sql을 튜닝하시오.
1) 튜닝전
select ename
from emp19
where ename like '김%' or
ename like '문%' or
ename like '이%' or
ename like '서%' or
ename like '윤%';
2) 튜닝후
select ename
from emp19
where regexp_like( ename, '^(김|문|이|서|윤)' );
문제 4. 아래의 SQL을 regexp_like로 튜닝하시오!
1)튜닝전
select ename
from emp19
where ename like '%서' or
ename like '%윤' or
ename like '%우' ;
2)튜닝후
select ename
from emp19
where regexp_like(ename, '(서|윤|우)$');
설명: ^ 는 앞에 썼는데 $ 는 뒤쪽에 써야 합니다.
※ 소괄호와 대괄호의 차이
select ename
from emp19
where regexp_like( ename,'(이현서)' );
-> '이현서'라는 이름만 나옴
select ename
from emp19
where regexp_like( ename,'[이현서]' );
-> '이', '현', '서' 세 글자 중 하나만 해당돼도 나옴
문제 5. 우리 반 테이블에서 이름, 이메일(숫자만 추출)_ regexp_substr ( 칼럼명, '[[:digit:]]+')
select ename, email, regexp_substr( email, '[[:digit:]]+')
from emp19;
문제 6. 우리 반 테이블에서 이름, 이메일(문만 추출)_ regexp_substr( 칼럼명, '[[:alpha:]]+')
select ename, email, regexp_substr( email, '[[:alpha:]]+')
from emp19;
★ (풀어야 할) 문제 7. 우리 반 학생들은 이메일에 어떤 숫자가 더 많이 나오는지 빈도수를 출력하시오.
create view email_number
as
select regexp_substr( email, '[[:digit:]]+') as email_number
from emp19
where regexp_substr( email, '[[:digit:]]+') is not null;
select * from email_number;
select substr( mail_num, level, 1 ) as digit
from dual
connect by level <= length(mail_num);
문제 8. 위 사진을 보고 locations 테이블에서 street_address의 문자가 시작되는 자리의 인덱스 번호를 출력하시오.
select street_address,
regexp_instr(street_address, '[[:alpha:]]') as 문자시작위치
from hr.locations;
문제 9. 우리반 테이블에서 이름, 이메일, 이메일에서 숫자가 시작되는 자리의 인덱스번호를 출력하시오.
select ename, email,
regexp_instr(email, '[[:alpha:]]') as 문자시작위치
from emp19;
문제 10. 아래의 문자열에서 i 가 몇 번 나오나오?
SELECT REGEXP_COUNT
('skfldjfweijfpm', 'i')
As Count
FROM dual;
문제 11. 영화 겨울왕국에서 엘사가 많이 나올까 안나가 많이 나올까? 이 질문에 답을 찾기 위해서 겨울 왕국의 대본을 오라클로 생성하고 결과를 출력하시오.
select '엘사의 건수', sum(regexp_count(lower(w_text),'elsa'))
from winter
union all
select '안나의 건수', sum(regexp_count(lower(w_text),'anna'))
from winter;
문제 12. 이름과 월급을 출력하는데 이름을 출력할 때 0 대신 *로 출력하시오
select ename, replace(sal, 0,'*')
from emp;
설명: * 이 0이라는 걸 알면 위의 sql은 무의미해짐
문제 13. 위의 결과를 숫자 0부터 3까지는 *로 출력하시오.
select ename, regexp_replace(sal, '[0-3]','*')
from emp;
문제 14. employee라는 테이블의 소유자가 누구인지 조회하시오.
select owner, table_name
from dba_tables
where lower(table_name) ='employees';
문제 15. employee 테이블에서 last_name과 phone_number(\. 을 -로) 출력하시오
select last_name, phone_number,regexp_replace(phone_number, '\.','-') as phone
from hr.employees;
설명. 앞에 \를 쓴 이유가. 을 읽기 위해서 임.
125. KAGGLE_ RANDOMFOREST_IRIS data
예제 125. 캐글 데이터 분석 순위 상위권에 도전하기
예측
회귀분석, 신경망
분석
나이브베이즈 확률, 랜덤포레스트
실습 1. 아이리스 데이터로 테이블을 생성하시오!
문제 1. iris 테이블에서 species의 데이터를 출력하는데 중복을 제거해서 출력하시오.
select distinct species
from iris;
문제 2. 훈련데이터와 테스트 데이터로 데이터를 분리하기 위해서 train_iris와 test_iris 테이블을 각각 9대 1로 생성하시오.
create table train_iris
as
select *
from iris
where caseno<136;
create table test_iris
as
select *
from iris
where caseno>=136;
select count(*) from train_iris; -- 135
select count(*) from test_iris; --15
문제 3.random forest 알고리즘을 이용해서 훈련 데이터를 학습해서 모델을 생성하시오.
-- ■ 부록 예제1. Kaggle 상위권에 도전하기1
-- 1. 머신러닝 모델이 학습할 테이블을 생성합니다.
create table train_iris
as
select *
from iris
where caseno < 136;
create table test_iris
as
select *
from iris
where caseno >= 136;
-- 2. 머신러닝 모델을 구성하기 위한 환경 설정 테이블을 생성합니다.
DROP TABLE SETTINGS_GLM;
CREATE TABLE SETTINGS_GLM
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.ALGO_NAME, 'ALGO_RANDOM_FOREST');
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.PREP_AUTO, 'ON');
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.GLMS_REFERENCE_CLASS_NAME,
'GLMS_RIDGE_REG_DISABLE');
-- 목적이 분류여서 수치예측인 회귀를 disable 시킴
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.ODMS_MISSING_VALUE_TREATMENT,
'ODMS_MISSING_VALUE_MEAN_MODE');
-- 결측치가 있다면 결측치를 그 데이터의 평균값으로 치환하겠다.
COMMIT;
END;
/
-- 3. 머신러닝 모델을 삭제합니다.
BEGIN
DBMS_DATA_MINING.DROP_MODEL( 'MD_CLASSIFICATION_MODEL');
END;
/
-- 4. 머신러닝 모델을 생성합니다.
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'MD_CLASSIFICATION_MODEL',
mining_function => DBMS_DATA_MINING.CLASSIFICATION,
data_table_name => 'TRAIN_IRIS',
case_id_column_name => 'CASENO',
target_column_name => 'SPECIES',
settings_table_name => 'SETTINGS_GLM');
END;
/
-- 5. 머신러닝 모델을 확인합니다.
SELECT MODEL_NAME,
ALGORITHM,
MINING_FUNCTION
FROM ALL_MINING_MODELS
WHERE MODEL_NAME = 'MD_CLASSIFICATION_MODEL';
-- 6. 머신러닝 모델 설정 정보를 확인합니다.
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_CLASSIFICATION_MODEL';
-- 7. 모델이 예측한 결과를 확인합니다.
SELECT CASENO , SPECIES AS 실제값,
PREDICTION (MD_CLASSIFICATION_MODEL USING *) 예측값
FROM TEST_IRIS
order by CASENO;
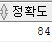
-- 8. 모델의 정확도 확인
select sum(decode(실제값, 예측값,1,0))/ count(*) *100
from (SELECT CASENO , SPECIES AS 실제값,
PREDICTION (MD_CLASSIFICATION_MODEL USING *) 예측값
FROM TEST_IRIS
order by CASENO)
;
5) 머신러닝 모델을 확인합니다.
6) 머신러닝 모델 설정 정보를 확인
7) 모델이 예측한 결과를 확인
8) 정확도
문제 4. iris 데이터를 랜덤으로 섞으시오.
select * from iris
order by dbms_random.value();
문제 5. 위 출력값을 iris2 테이블로 만들고 랜덤으로 섞어서 iris3라는 테이블로 생성하시오!
desc iris;
create table iris2
as
select SEPALLENGTH, SEPALWIDTH, PETALLENGTH, PETALWIDTH, SPECIES
from iris
order by dbms_random.value();
create table iris3
as
select rownnum as caseno, i.*
from iris2 i;
select * from iris3;
문제 6. iris3 테이블을 훈련테이블과 테스트 테이블로 9대 1로 나눠서 랜덤 포레스트 머신러닝 모델을 생성하고 정확도를 확인하시오.
-- ■ 부록 예제1. Kaggle 상위권에 도전하기1
-- 1. 머신러닝 모델이 학습할 테이블을 생성합니다.
drop table train_iris;
drop table test_iris;
create table train_iris
as
select *
from iris3
where caseno < 136;
create table test_iris
as
select *
from iris3
where caseno >= 136;
-- 2. 머신러닝 모델을 구성하기 위한 환경 설정 테이블을 생성합니다.
DROP TABLE SETTINGS_GLM;
CREATE TABLE SETTINGS_GLM
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.ALGO_NAME, 'ALGO_RANDOM_FOREST');
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.PREP_AUTO, 'ON');
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.GLMS_REFERENCE_CLASS_NAME,
'GLMS_RIDGE_REG_DISABLE');
-- 목적이 분류여서 수치예측인 회귀를 disable 시킴
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.ODMS_MISSING_VALUE_TREATMENT,
'ODMS_MISSING_VALUE_MEAN_MODE');
-- 결측치가 있다면 결측치를 그 데이터의 평균값으로 치환하겠다.
COMMIT;
END;
/
-- 3. 머신러닝 모델을 삭제합니다.
BEGIN
DBMS_DATA_MINING.DROP_MODEL( 'MD_CLASSIFICATION_MODEL');
END;
/
-- 4. 머신러닝 모델을 생성합니다.
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'MD_CLASSIFICATION_MODEL',
mining_function => DBMS_DATA_MINING.CLASSIFICATION,
data_table_name => 'TRAIN_IRIS',
case_id_column_name => 'CASENO',
target_column_name => 'SPECIES',
settings_table_name => 'SETTINGS_GLM');
END;
/
-- 5. 머신러닝 모델을 확인합니다.
SELECT MODEL_NAME,
ALGORITHM,
MINING_FUNCTION
FROM ALL_MINING_MODELS
WHERE MODEL_NAME = 'MD_CLASSIFICATION_MODEL';
-- 6. 머신러닝 모델 설정 정보를 확인합니다.
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_CLASSIFICATION_MODEL';
-- 7. 모델이 예측한 결과를 확인합니다.
SELECT CASENO , SPECIES AS 실제값,
PREDICTION (MD_CLASSIFICATION_MODEL USING *) 예측값
FROM TEST_IRIS
order by CASENO;
-- 8. 모델의 정확도 확인
select sum(decode(실제값, 예측값,1,0))/ count(*) *100
from (SELECT CASENO , SPECIES AS 실제값,
PREDICTION (MD_CLASSIFICATION_MODEL USING *) 예측값
FROM TEST_IRIS
order by CASENO)
;
126. KAGGLE(2)_TITANIC data
예제 126. 캐글 데이터 분석 순위 상위권에 도전하기 (2) _p558 실습 1. 타이타닉 테이블을 생성하고 titanic.csv를 입력하시오
create table tit
( caseno number(10),
survived number(10),
pclass number(10),
sex varchar2(10),
age number(10),
sibsp number(10),
parch number(10),
fare number(10,4),
embarked varchar2(10),
class varchar2(20),
who varchar2(20),
adult_male varchar2(20),
deck varchar2(10),
embark_town varchar2(10),
alive varchar(10),
alone varchar2(10) );
예: 미국민 의료 데이터에서 기계학습 시킬때 비만이면 담배를 피는 경우의 파생컬럼을 만들었더니 갑자기 모델의 성능이 올라갔듯이 좋은 학습 데이터 컬럼이 있어야합니다.
실습 2. tit 테이블에 결측치 칼럼이 많은 컬럼이 뭔지 알아내시오! 결측치가 너무 많으면 아예 drop을 하는 게 바람직합니다. 결측치가 조금 있는 칼럼이면 다른 데이터로 채워 넣어야 합니다
select 'select count(*) from tit where ' ||lower(column_name)||' is null;'
from user_tab_columns
where table_name='TIT';
select count(*) from tit where caseno is null;
select count(*) from tit where survived is null;
select count(*) from tit where pclass is null;
select count(*) from tit where sex is null;
select count(*) from tit where age is null; -177개
select count(*) from tit where sibsp is null;
select count(*) from tit where parch is null;
select count(*) from tit where fare is null;
select count(*) from tit where embarked is null; -2개
select count(*) from tit where class is null;
select count(*) from tit where who is null;
select count(*) from tit where adult_male is null;
select count(*) from tit where deck is null; -688개
select count(*) from tit where embark_town is null; -2개
select count(*) from tit where alive is null;
select count(*) from tit where alone is null;
90%는 좋은 학습 데이터를 만들기 위한 데이터 전처리이고 10%가 기계학습 시키는 것과 모델선정하는 것임
실습 3. tit 테이블의 age칼럼에 null값을 age칼럼의 평균값으로 변경하시오.
select count(*)
from tit
where age is null;
select round(avg(age))
from tit;
update tit
set age=30
where age is null;
select embarked, count(*)
from tit
group by embarked
order by 2 desc;
update tit
set embarked = 'S'
where embarked is null;
select embark_town, count(*)
from tit
group by embark_town
order by 2 desc;
update tit
set embark_town = 'Southampton'
where embark_town is null;
실습 5. 필요한 컬럼만 선별해서 다시 테이블을 구성합니다.
alter table tit
drop column survived;
alter table tit
drop column class;
alter table tit
drop column embark_town;
실습 6. tit 테이블을 훈련 9, 테스트1로 나누고 머신러닝을 돌려 정확도를 확인 하시오
-- ■ 부록 예제1. Kaggle 상위권에 도전하기1
-- 1. 머신러닝 모델이 학습할 테이블을 생성합니다.
drop table train_tit;
drop table test_tit;
create table train_tit
as
select *
from tit
where caseno < 801;
create table test_tit
as
select *
from tit
where caseno >= 801;
-- 2. 머신러닝 모델을 구성하기 위한 환경 설정 테이블을 생성합니다.
DROP TABLE SETTINGS_GLM;
CREATE TABLE SETTINGS_GLM
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.ALGO_NAME, 'ALGO_RANDOM_FOREST');
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.PREP_AUTO, 'ON');
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.GLMS_REFERENCE_CLASS_NAME,
'GLMS_RIDGE_REG_DISABLE');
-- 목적이 분류여서 수치예측인 회귀를 disable 시킴
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.ODMS_MISSING_VALUE_TREATMENT,
'ODMS_MISSING_VALUE_MEAN_MODE');
-- 결측치가 있다면 결측치를 그 데이터의 평균값으로 치환하겠다.
COMMIT;
END;
/
-- 3. 머신러닝 모델을 삭제합니다.
BEGIN
DBMS_DATA_MINING.DROP_MODEL( 'MD_CLASSIFICATION_MODEL');
END;
/
-- 4. 머신러닝 모델을 생성합니다.
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'MD_CLASSIFICATION_MODEL',
mining_function => DBMS_DATA_MINING.CLASSIFICATION,
data_table_name => 'TRAIN_tit',
case_id_column_name => 'CASENO',
target_column_name => 'ALIVE',
settings_table_name => 'SETTINGS_GLM');
END;
/
-- 5. 머신러닝 모델을 확인합니다.
SELECT MODEL_NAME,
ALGORITHM,
MINING_FUNCTION
FROM ALL_MINING_MODELS
WHERE MODEL_NAME = 'MD_CLASSIFICATION_MODEL';
-- 6. 머신러닝 모델 설정 정보를 확인합니다.
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_CLASSIFICATION_MODEL';
-- 7. 모델이 예측한 결과를 확인합니다.
SELECT CASENO , ALIVE AS 실제값,
PREDICTION (MD_CLASSIFICATION_MODEL USING *) 예측값
FROM TEST_tit
order by CASENO;
-- 8. 모델의 정확도 확인
select ROUND(sum(decode(실제값, 예측값,1,0))/ count(*) *100) 정확도
from (SELECT CASENO , ALIVE AS 실제값,
PREDICTION (MD_CLASSIFICATION_MODEL USING *) 예측값
FROM TEST_tit
order by CASENO)
;
문제 1. 위의 머신러닝 정확도를 올리기위해 파생컬럼을 추가하시오.
alter table tit
add women_child number(10);
update tit m
set women_child = ( select case when age < 10 or sex='femail'
then 1 else 0 end
from tit s
where s.caseno = m.caseno );
select * from tit;
commit;
문제2. 파생변수 추가한 테이블을 가지고 다시 훈련 테이블과 테스트 테이블을 구성하고 랜덤포레스트 모델을 만들어서 정확도가 올라가는지 확인하시오 .