※ 현업에서 위와 같이 부모자식관계의 테이블을 구성하는 이유? -> outer join을 사용하지 않아도 equi join으로 제대로 조인된 결과를 볼 수 있게 해 주기 때문. -> 엉뚱한 부서버노가 emp테이블에 있으면 어쩔 수 없이 outer join을 써야 됨. (대용량 데이터 베이스 환경에서는 outer join의 검색성능이 좋지 않고 데이터 분석 시에도 빠른 분석을 하기가 어려움_ 데이터 품 질의 위해 부모자식 관계를 현성해 주는 게 바람직함)
문제 1.5. dept 테이블의 primary key 제약을 삭제하시오.
alter table dept
drop constraint dept_deptno_pk;
설명: emp테이블에 deptno가 dept테이블의 deptno를 참조하고 있기 때문에 제약이 drop이 안됨. drop 하려면 cascade 옵션을 사용해야 함
alter table dept
drop constraint dept_deptno_pk cascade;
설명: 이렇게 삭제하면 자식키(foreign key)와 같이 삭제됨.
* 제약조건 확인
select *
from user_constraints
where table_name in ('EMP','DEPT');
문제 2.1. DEPT900 테이블을 생성하는데 DEPTNO에 PRIMARY KEY 제약을 걸어서 생성하시오! 1. 테이블 레벨 문법
문제 3.3.emp 테이블의 empno, ename, sal, deptno를 emp900에 입력하시오. 서브쿼리를 사용한 insert 문을 이용하세요!
insert into emp900(empno, ename, sal, deptno )
select empno, ename, sal, deptno
from emp;
문제 3.4. dept900 테이블에 부서번호 20번을 delete 하시오.
delete from dept900
where deptno =20;
설명: emp 테이블에 deptno가 20번 있기 때문에 지워지지 않음
문제 4. 다음의 테이블과 제약구성을 하시오.
1) dept800 (부모테이블 생성)
create table dept800
(deptno number(10) constraint dept800_deptno_pk primary key,
dname varchar2(10),
loc varchar2(10));
2) emp800 (자식테이블 생성)
create table emp800
(empno number(10),
ename varchar2(10),
sal number(10),
job varchar2(10),
deptno number(10) constraint emp800_deptno_fk references dept800(deptno));
3) 데이터 삽입 (부모테이블부터!!)
insert into dept800 (deptno,dname, loc)
select deptno,dname, loc from dept;
insert into emp800 (empno, ename, sal, job, deptno)
select empno, ename, sal, job, deptno from emp;
109. WITH~AS
예제 109. WITH 절 사용하기 1(WITH~AS)
WITH절을 사용하는 이유? -> FROM 절의 서브쿼리처럼 데이터 쿼리문을 select 해온 결과 데이터를 가지고 연산을 하거나 조건읠 줘서 출력하고 싶을 때 유용한 sql문
그런데 from 절의 서브쿼리와 차이점은 from 절의 서브쿼리는 데이터를 메모리에 저장하는데 with 절은 디스크에 저장함 (데이터를 임시 테이블오 저장하고 있다는 게 차이)
Q1. 이름, 월급, 월급의 순위를 출력하시오.
select ename, sal , dense_rank()over(order by sal desc) as 순위
from emp;
Q2. from 절의 서브쿼리를 이용하여 이름과 월급, 월급의 순위를 출력하는데 순위가 1,3,5등만 출력되게 하시오.
select ename, sal , 순위
from (select ename, sal , dense_rank()over(order by sal desc) as 순위
from emp)
where 순위 in (1,3,5);
설명: from 절의 서브쿼리로 가져오는 데이터를 메모리에 올리는 SQL인데 오라클 프로세서 하나가 사용할 수 있는 메모리가 몇 십메가 ~ 몇백메가 밖에 안됩니다. 그런데 위의 FROM 절 서브쿼리 안에 이름, 월급, 순위를 가져오는 데이터가 굉장히 많다면 메모리에 다 올릴 수 가 없습니다. 그러면 메모리 부족 오류가 발생하면서 위의 SQL이 오류가 납니다. -> 이럴때 with 절을 쓰면 됨!!
with emp_rank as
(select ename, sal , dense_rank()over(order by sal desc) as 순위
from emp
)
select ename, sal, 순위
from emp_rank;
Q3. 위의 WITH절에서 사용하고 있는 임시 테이블이 정말 만들어졌는지 확인하시오.
explain plan for
with emp_rank as
(select ename, sal , dense_rank()over(order by sal desc) as 순위
from emp
)
select ename, sal, 순위
from emp_rank;
select * from table(dbms_xplan.display);
설명: 위의 실행계획은 오라클 옵티마이져가 with절을 from 절의 서브쿼리로 SQL문장으로 변경해서 수행한것 입니다. 그래서 WITH 절의 효과를 못본겁니다. WITH 절의 효과는 작은 메모리 영역을 서로 사용하겠다고 경합을 일으키지 않아도 되고 넉넉한 디스크를 사용하는것입니다. 경합을 일으키면 SQL 이 느려집니다. 그래서 임시 테이블 스페이스를 사용하겠금 오라클 힌트를 써야합니다.
** with 절 사용할때 유용한 힌트 2가지 1. /*+ materializw */ 힌트: 임시테이블 스페이스에 임시 테이블을 생성해라 2. /*+ inlune */ 힌트: 임시테이블 만들이 말고 from절의 서브쿼리처럼 수행해 메모리에 데이터에 올려라.
explain plan for
with emp_rank as
( select /*+ materialize */ ename, sal, dense_rank() over ( order by sal desc ) 순위
from emp
)
select ename, sal, 순위
from emp_rank
where 순위 in ( 1, 3, 5 );
select * from table(dbms_xplan.display);
Q4. 아래의 WITH절에 INLINE 힌트를 이용해서 임시 테이블을 만들지 말고 수행되게 하시오
explain plan for
with emp_rank as
( select /*+ INLINE */ ename, sal, dense_rank() over ( order by sal desc ) 순위
from emp
)
select ename, sal, 순위
from emp_rank
where 순위 in ( 1, 3, 5 );
select * from table(dbms_xplan.display);
문제 1. 아래 sql을 with절로 변경하시오
1) 튜닝전
select ename, sal, round(부서평균)
from (select ename, sal , avg(sal) over(partition by deptno) 부서평균
from emp
)
where sal > 부서평균;
2) 튜닝 후
with emp_avg as
( select ename, sal , avg(sal) over(partition by deptno) 부서평균
from emp
)
select ename, sal, round(부서평균) from emp_avg
where sal > 부서평균;
설명: 힌트를 사용하는 이유는 아직 오라클 옵티마이져가 사람이 손길이 많이 필요한 아주 미숙한 상태임.
문제 2. 아래 sql을 with절로 변경하시오
1) 튜닝전
select ename,loc, sal, 순위
from (Select e.ename, d.loc, e.sal ,
dense_rank()over(partition by loc order by sal desc) 순위
from emp e, dept d
where e.deptno= d.deptno)
where 순위 =1;
2) 튜닝후
with ed_sal as
(Select e.ename, d.loc, e.sal ,
dense_rank()over(partition by loc order by sal desc) 순위
from emp e, dept d
where e.deptno= d.deptno)
select ename, loc, sal, 순위 from ed_sal
where 순위 =1;
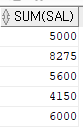
문제 3.1. 직업과 직업별 토털월급을 출력하시오.
select job, sum(sal)
from emp
group by job;
문제 3.2. 위의 결과에서 직업별 토털월급들만 출력하시오.
select sum(sal)
from emp
group by job;
문제 3.3 위의 결괏값의 평균값을 출력하시오.
select avg(sum(sal))
from emp
group by job;
※ group 합수 특징 1. 그룹함수는 중첩을 할 수 있습니다. 2. 그룹함수는 null값을 무시합니다.
문제 3.4. 직업과 직업별 토털월급을 출력하는데 직업별 토털월급이 직별 토털월급들에 대한 평균값보다 더 큰 것만 출력하시오.
select job, sum(sal)
from emp
group by job
having sum(sal)> (select avg(sum(sal))
from emp
group by job);
설명: 직업이 아주 많아서 직업을 grouping 하는데 시간이 20분이 걸린다고 해보면 메인쿼리 20분, 서브쿼리 20분 걸려서 총 40분이 걸리는 SQL이라고 가정합니다. 문제 3.5. 위 sql을 with 절로 변경하시오.
select job, 토탈
from job_sumsal
where 토탈>(select avg(토탈)
from job_sumsal);
문제 3.6. 위의 SQL을 WITH 절로 변경하시오 !
with job_sumsal as (select job,sum(sal) as 토탈
from emp
group by job)
select job, 토탈
from job_sumsal
where 토탈>(select avg(토탈)
from job_sumsal);
설명: 이 sql은 직업별 토털월급을 구하는 임시테이블을 구성할 때만 20분 걸리고 더 이상 오래 걸리지 않음.
문제 4. 통신사, 통신사별 토탈 나이를 출력하는데 토탈나이의 평균값보다 더 큰 것만 출력하시오.
1) 튜닝전
select lower(telecom), sum(age)
from emp19
group by lower(telecom)
having sum(age) >(select avg(sum(age))
from emp19
group by lower(telecom));
2) 튜닝후
with telecom_sumage as ( select lower(telecom)as 통신사, sum(age) as 토탈
from emp19
group by lower(telecom))
select 통신사, 토탈
from telecom_sumage
where 토탈 > (select avg(토탈) from telecom_sumage);
※ with절을 사용 했을 때의 장점 - 일부러 테이블& view를 생성하지 않아도
★★ 문제5. 숫자 1-10까지의 토탈값, 평균값, 최대값, 최소값을 출력하시오.
with number_ten as(select level as num
from dual
connect by level <=10)
select sum(num),avg(num),max(num), min(num)
from number_ten;
문제 6. 1~10까지의 숫자중에서 짝수만 출력하시오
select num
from number_even
where mod(num,2)=0;
문제 7. 1-10까지의 숫자중에서 홀수 숫자의 합을 출력하시오.
with number_sum as(select level as num
from dual
connect by level <=10)
select sum(num)
from number_sum
where mod(num,2)=1;
문제 8. 직업과 직업별 토탈월급에 대하여 평균값, 분산값, 표준편차값을 출력하시오.
with job_sumsal as(select job, sum(sal) as 토탈
from emp
group by job)
select avg(토탈), var_pop(토탈), stddev(토탈)
from job_sumsal;
1) 분산값 ? 데이터의 퍼짐 정도 데이터값들이 평균으로 부터 얼마나 떨어져있는지를 나타내는 척도 평균에 몰려있는지 아니면 평균에서 멀어져 있는지를 나타내는 척도 - var_pop: 모집단의 분산을 계산하는 함수 - var_samp: 표본의 분산을 계산하는 함수
2) 표준편차? 분산값에 루트를 씌운값(제곱근) 데이터값들이 평균으로 부터 얼마나 떨어져 있는지 나타내는 값
110. SUBQUERY FACTORING
select deptno, 부서토탈
from( select job, sum(sal) as 직업토탈
from emp
group by job) as job_sumsal,
( select deptno, sum(sal) as 부서토탈
from emp
group by deptno
having sum(sal) > (select avg(직업토탈) + 3000
from job_sumsal)) as dept_sumsal;
Q2. 위의 결과를 WITH 절로 구현하시오. : with 절에는 여러 문장 사용가능
with job_sumsal as(select job, sum(sal) 직업토탈
from emp
group by job),
deptno_sumsal as(select deptno, sum(sal) 부서토탈
from emp
group by deptno
having sum(sal) > (select avg(직업토탈) +3000 from job_sumsal)
)
select deptno,부서토탈
from deptno_sumsal;
※ 현업 tip 튜닝 요청 받은 SQL의 이전 작성 SQL을 찾아서 두개의 차이점을 비교합니다. (TOAD, ORANGE 프로그램 이용) 그래서 변경된 부분만 튜닝하면 됨. 변경된 부분이 어느 임시테이블을 만드는 쿼리문 1개인데 그짧은 SQL만 튜닝하면 됨. 예제 111. WITH 절 사용하기 2(SUBQUERY FACTORING) : 기존의 서브쿼리문으로는 구현하지 못하는 기능을 WITH절로 구현하기 위한 기능
Q. 임시 테이블을 다음과 같이 2개로 해서 WITH 절을 작성하시오 !
with man_info as ( select ename, gender, age
from emp19
where gender='남' ),
woman_info as ( select ename, gender, age
from emp19
where gender='여' )
select gender, round(avg(age))
from man_info
group by gender
union all
select gender, round(avg(age))
from woman_info
group by gender;
문제 1. 아래의 SQL을 WITH 절로 변경하시오.
1) 튜닝전
select lower(telecom), max(age), min(age), round(avg(age))
from emp19
where lower(telecom)='sk'
group by lower(telecom)
union all
select lower(telecom), max(age), min(age), round(avg(age))
from emp19
where lower(telecom)='lg'
group by lower(telecom)
union all
select lower(telecom), max(age), min(age), round(avg(age))
from emp19
where lower(telecom)='kt'
group by lower(telecom);
2) 튜닝 후
with sk_telecom as ( select lower(telecom) 통신사, age
from emp19
where lower(telecom)='sk' ),
lg_telecom as ( select lower(telecom) 통신사, age
from emp19
where lower(telecom)='lg' ),
kt_telecom as ( select lower(telecom) 통신사, age
from emp19
where lower(telecom)='kt' )
select 통신사, max(age), min(age), round(avg(age) )
from sk_telecom
group by 통신사
union all
select 통신사, max(age), min(age), round(avg(age) )
from lg_telecom
group by 통신사
union all
select 통신사, max(age), min(age), round(avg(age) )
from kt_telecom
group by 통신사;
111. 유저생성하기
예제 111. 유저 생성하기 Q1. C##KING 이라는 유저의 패스워드를 TIGER로 해서 생성하시오.
create user c##king
identified by tiger;
설명: c##을 앞에 붙여서 유저를 만드는 이유가 컨테이너 데이터 베이스의 공용유저를 만들 때는 c##을 앞에 붙여야됨.
Q2. C##을 안붙이고 유저를 생성하시오.
명령 프롬프트창을 열고 sys 유져로 접속을 합니다.
sys 유져는 오라클의 최고 권한자 입니다.
# 1. 오라클 최고 권한자로 접속을 합니다.
C:\Users\ITWILL>sqlplus sys/oracle_4U as sysdba
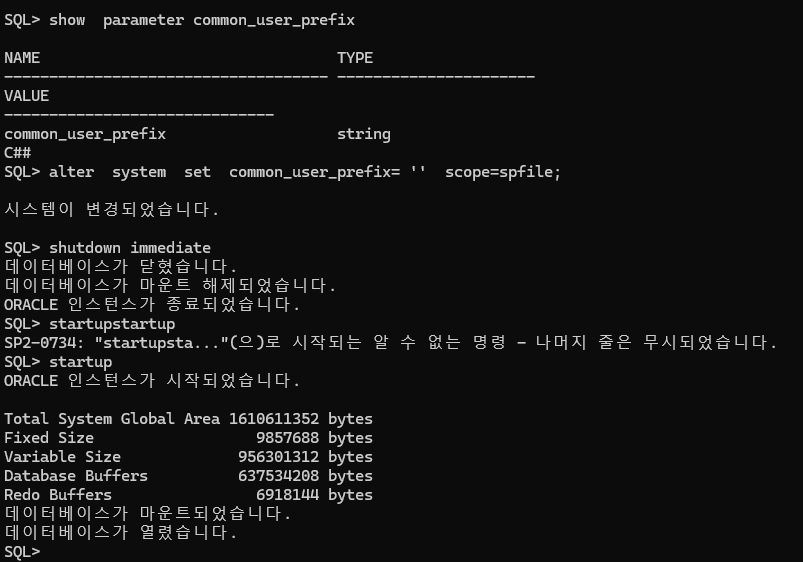
#2. 유져를 생성할 때 유져이름 앞에 필수로 접두어로 붙여줘야하는 키워드를 확인
SQL> show parameter common_user_prefix
#3. c## 을 안붙여도 되겠금 null 로 common_user_prefix 를 셋팅함
SQL> alter system set common_user_prefix= '' scope=spfile;
#4. db를 내렸다 올립니다.
SQL> shutdown immediate
SQL> startup
#5. c## 없이 king 유져를 생성합니다.
SQL> create user king
identified by tiger;
#6. connect 와 resource 권한을 king 에게 부여합니다.
SQL> grant connect, resource to king;
설명: king 에게 connect (db에 접속할 수 있는 권한 ) 을 주고
resource(테이블 생성과 같은 기본적인 권한) 을 줍니다.
#7. king 으로 접속해봅니다.
SQL> connect king/tiger
연결되었습니다.
SQL> show user
문제 1. sys 유져에서 smith 라는 유져를 생성하는데 패스워드를 oracle1234 로 해서 생성하고 connect 와 resource 권한을 부여하시오 !
SQL> connect sys/oracle_4U as sysdba
연결되었습니다.
문제687. sys 유져에서 smith 라는 유져를 생성하는데 패스워드를 oracle1234 로 해서
생성하고 connect 와 resource 권한을 부여하시오 !
SQL> create user smith
identified by oracle1234;
사용자가 생성되었습니다.
SQL> grant connect, resource to smith;
권한이 부여되었습니다.
문제 2. sqldeveloper 로 smith 유져로 접속해보시오
** 만약 권한이없다는 오류가 뜨면 명령프롬프트에 권한부여
grant dba to smith;
문제 3. sqldeveloper을 끄고 명령 프롬프트창의 sys 유저에서 smith 유저를 drop 하시오.
SQL> show user
USER은 "SYS"입니다
SQL> drop user smith cascade;
사용자가 삭제되었습니다.
문제 4. 다시 sys 유저에서 smith 유저를 패스워드 oracle 1234 로 생성하고 dba권한을 부여하시오.
SQL> create user smith
2 identified by oracle1234;
사용자가 생성되었습니다.
SQL> grant dba to smith;
권한이 부여되었습니다.
문제 5. smith 유저의 패스워드를 tiger로 변경하시오.
SQL> alter user smith
2 identified by tiger;
사용자가 변경되었습니다.
설명: 패스워드를 잃어버리면 변경하여 알아
문제 6. smith2라는 유저를 password: tiger 로 해서 생성하고 dba 권한을 부여하시오.
SQL> create user smith2
2 identified by tiger;
사용자가 생성되었습니다.
SQL> grant dba to smith2;
권한이 부여되었습니다.
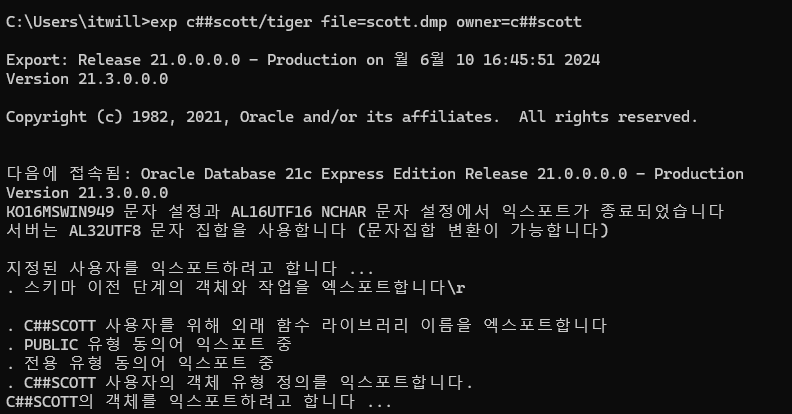
문제 7. c##scott 유저가 가지고 있는 모든 테이블, 인덱스, 스퀀스, 뷰를 모두다 export 하시오