귀무가설: 나이가 많으면서 비만이면 의료비와 연관이 없다. 대립가설: 나이가 많으면서 비만이면 의료비와 연관이 있다.
나이는 60살을 기준으로 60살 이상이면 1 아니면 0으로 하는 파생컬럼을 추가하세요. 비만지수는 30을 기준으로 1과 0으로 구분된 bmi30을 그대로 사용합니다. bmi_age_old 라는 파생 컬럼을 만들어서 가설검정을 하면 됩니다.
나이는 60살을 기준으로 60살 이상이면 1 아니면 0으로 하는 파생컬럼을 추가하세요.
비만지수는 30을 기준으로 1과 0으로 구분된 bmi30을 그대로 사용합니다.
bmi_age_old 라는 파생 컬럼을 만들어서 가설검정을 하면 됩니다.
--파생 컬럼 만들기
alter table insurance
add bmi_age_old number(20);
alter table insurance
add age_old number(20);
select * from insurance;
-- 나이는 60살을 기준으로 60살 이상이면 1 아니면 0으로 하는 파생컬럼을 추가
update insurance
set age_old = 0;
update insurance
set age_old = 1
where age >= 60;
-- 60살이상이면서 bmi30이 넘는사람 파생컬럼 추가
update insurance
set bmi_age_old = 0;
update insurance
set bmi_age_old = 1
where bmi30=1 and age_old=1;
-- 다 drop 하고 결과 확인
DROP TABLE INSURANCE_TRAINING;
CREATE TABLE INSURANCE_TRAINING
AS
SELECT *
FROM INSURANCE
WHERE ID < 1114;
DROP TABLE INSURANCE_TEST;
CREATE TABLE INSURANCE_TEST
AS
SELECT *
FROM INSURANCE
WHERE ID >= 1114;
-- 3. 머신러닝 모델의 환경 구성 테이블을 생성합니다.
DROP TABLE SETTINGS_REG2;
CREATE TABLE SETTINGS_REG2
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_REG2
VALUES (DBMS_DATA_MINING.ALGO_NAME,'ALGO_GENERALIZED_LINEAR_MODEL');
INSERT INTO SETTINGS_REG2
VALUES (DBMS_DATA_MINING.PREP_AUTO, 'ON');
COMMIT;
END;
/
-- 4. 머신러닝 모델을 생성합니다.
BEGIN
DBMS_DATA_MINING.DROP_MODEL('MD_REG_MODEL2');
END;
/
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
MODEL_NAME => 'MD_REG_MODEL2',
MINING_FUNCTION => DBMS_DATA_MINING.REGRESSION,
DATA_TABLE_NAME => 'INSURANCE_TRAINING',
CASE_ID_COLUMN_NAME => 'ID',
TARGET_COLUMN_NAME => 'EXPENSES',
SETTINGS_TABLE_NAME => 'SETTINGS_REG2');
END;
/
-- 5. 생성된 머신러닝 모델을 확인합니다.
SELECT MODEL_NAME,
ALGORITHM,
MINING_FUNCTION
FROM ALL_MINING_MODELS
WHERE MODEL_NAME = 'MD_REG_MODEL2';
-- 6. 머신러닝 모델 구성 정보를 확인합니다.
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_REG_MODEL2';
-- 7. 회귀분석 모델의 회귀계수를 확인합니다.
SELECT ATTRIBUTE_NAME, ATTRIBUTE_VALUE, ROUND(COEFFICIENT)
FROM TABLE (DBMS_DATA_MINING.GET_MODEL_DETAILS_GLM ('MD_REG_MODEL2'));
-- 8. 예측 값을 확인합니다.
SELECT ID, AGE, SEX, EXPENSES,
ROUND(PREDICTION (MD_REG_MODEL2 USING *),2) MODEL_PREDICT_RESPONSE
FROM INSURANCE_TEST T;
-- 9. 결정계수 R 스퀘어 값 확인합니다.
SELECT GLOBAL_DETAIL_NAME, ROUND(GLOBAL_DETAIL_VALUE,3)
FROM
TABLE(DBMS_DATA_MINING.GET_MODEL_DETAILS_GLOBAL(MODEL_NAME =>'MD_REG_MODEL2'))
WHERE GLOBAL_DETAIL_NAME IN ('R_SQ','ADJUSTED_R_SQUARE');
-- 10. 전체 p-value 확인
SELECT ATTRIBUTE_NAME, ATTRIBUTE_VALUE, ROUND(COEFFICIENT), e.*
FROM TABLE (DBMS_DATA_MINING.GET_MODEL_DETAILS_GLM ('MD_REG_MODEL2'))e;
[TIL 17] 240604
97.INDEX
예제 97. 데이터 검색 속도 높이기 (INDEX) * db 오브젝트(object) 5가지?
1. 테이블
2. 인덱스
3. 뷰
4. 시너님
5. 시퀀스
인덱스란? : 테이블에서 데이터를 검색할 때 검색속도를 향상해 주는 데이터베이스 오브젝트 : 빅데이터 환경에서 인덱스가 없다면 검색이 너무 느려서 아무런 작업도 할 수 없다. (ex. 두꺼운 책의 목차) : 인덱스는 칼럼값(데이터 정렬: asending)과 rowid로 구성되어 있다. : ㄱㄴㄷㄹ순으로 저장되어 있기 때문에 페이지를 빠르게 검색할 수 있다. 그게 아니라면 full scan 하게 되어 시간이 많이 걸림 1. emp 테이블 처럼 작은 테이블에 인덱스를 걸면 별로 효과를 못 보기 때문에 데이터가 많은 테이블에 인덱스를 생성해야 인덱스 효과를 볼 수 있다.
2. null 값은 인덱스로 구성이 안되기 때문에 null 값이 많은 칼럼에 인덱스를 걸면 효과가 좋다. null 이 아닌 값들만으로 인덱스가 구성이 됩니다. full table scan을 하게 되면 NULL값을 전무 SCAN 하기 때문에 검색 시간만 오래 걸리게 된다.
3. ★ 중요 ★ where 절에 자주 등장하는 컬럼에 인덱스를 생성하는 게 바람직하다. ex ) select ename, sal from emp where empno = 7788;
4. 검색하려는 데이터가 전체 테이블의 데이터 중에 2~4% 미만인 컬럼에 인덱스를 거는 게 바람직하다. ex) - 인덱스 생성에 바람직한 컬럼: select ename, sal from emp where empno = 7788; - 인덱스 생성에 부적합한 컬럼 select ename, gender from emp19 where gender='남'; ** 검색하려는 데이터가 테이블의 50%면 그냥 full table scan 이 더 빠릅니다.
※ 어떤 컬럼에 인덱스를 생성하지 말아야 되나요? 1. where 절에서 자주 검색되지 않은 칼럼 2. emp 테이블처럼 작거나 검색하려는 데이터가 전체 데이터에 2~4% 이상으로 검색하려고 할 때 3. 자주 UPDATE 되는 칼럼 -> 자주 갱신되는 칼럼 테이블의 데이터를 자주 갱신하면 인덱스도 자주 갱신되어야 합니다. 테이블의 이름 BLAKE를 JANE으로 변경했으면 테이블은 변경이 되지만 인덱스는 변경되지 않고 새로운 데이터가 입력이 됩니다. 테이블에 UPDATE 가 많아지면 인덱스가 점점 커집니다.
※ 어떤 칼럼에 인덱스를 생성해야 하나요? 1. 큰 테이블( 몇 백만 건 ~ 몇 천만 건 이상) 2. WHERE 절에서 자주 검색되는 칼럼 3. 검색하려는 데이터가 전체 데이터에서 2~4% 미만인 칼럼 4. NULL 값이 많은 컬럼
문제 1. 사원 테이블의 월급에 인덱스를 생성하시오
create index emp_sal
on emp(sal);
문제 2. 사원 테이블 월급 인덱스가 잘 생성되었는지 데이터 사전을 조회하여 확인하시오.
select * from user_indexes
where table_name='EMP';
* 테이블 이름 쓸 때 반드시 대문자로! 작성!
문제 3. emp_sal이 어떻게 생겼는지 확인하시오.
select sal, rowid
from emp
where sal >=0;
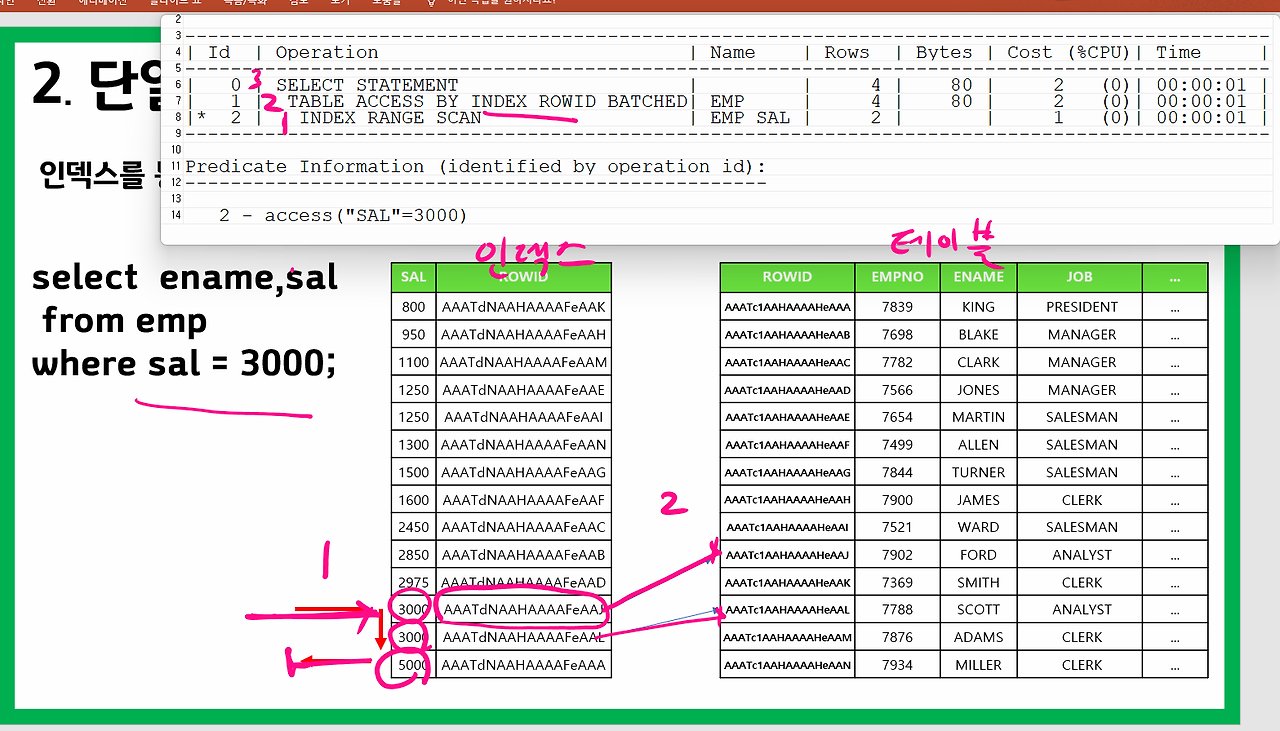
설명 : order by절을 사용 안 했는데 asc로 정렬이 되어 출력됨 -> 테이블에서 데이터를 읽어온 게 아니라 emp_sal 인덱스(asc 한 데이터)에서 데이터를 읽어왔기 때문 -> 인덱스에서 데이터를 읽어오려면 반드시 where절이 필요
숫자
>=
문자
> ' '
날짜
< to_date('9999/12/31', 'RRRR/MM/DD')
문제 4. 월급이 3000인 사원의 이름과 월급을 출력하시오
select ename, sal
from emp
where sal = 3000;
문제 5. 위의 데이터를 검색할 때 인덱스를 통해서 테이블의 데이터를 검색했는지 아니면 그냥 테이블을 full table scan 했는지 실행계획을 확인하시오.
explain plan for
select ename, sal
from emp
where sal = 3000;
select * from table(dbms_xplan.display);
실행계획 읽는 방법: 안쪽 -> 바깥쪽
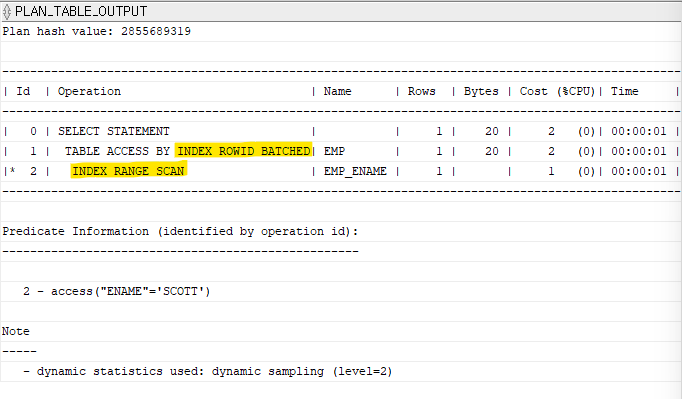
문제 6. 이름이 scott인 사원의 이름, 월급을 출력하는 쿼리문의 실행계획을 확인하시오.
explain plan for
select ename, sal
from emp
where ename = 'SCOTT';
select * from table(dbms_xplan.display);
문제 7. 위 결과의 검색속도를 올리기 위해 INDEX를 걸어 출력하시오.
create index emp_ename
on emp(ename);
explain plan for
select ename, sal
from emp
where ename = 'SCOTT';
select * from table(dbms_xplan.display);
문제 8. emp_ename 인덱스의 구조를 확인하시오.
select ename, rowid
from emp
where ename > ' ';
설명: ' ' 공백문자를 주면서 다 나오게 함
문제 9. 아래의 sql의 검색속도를 높이기 위해서 인덱스를 생성하시오
-- 인덱스 걸기전 실행계획확인 (full scan)
explain plan for
select ename, hiredate
from emp
where hiredate = to_date('81/11/17','RRRR/MM/DD');
select * from table(dbms_xplan.display);
-- 인덱스 생성 후 잘 생성 되었는지 확인
create index emp_hiredate
on emp(hiredate);
select * from user_indexes
where table_name ='EMP';
-- 인덱스 후 실행계획확인 (index scan)
explain plan for
select ename, hiredate
from emp
where hiredate = to_date('81/11/17','RRRR/MM/DD');
select * from table(dbms_xplan.display);
문제 10. 아래의 sql 검색속도를 높이기 위해 적절한 sql을 생성하시오.
select ename, sal, deptno
from emp
where deptno=10;
-- 인덱스 걸기전 실행계획확인 (full scan)
explain plan for
select ename, sal, deptno
from emp
where deptno=10;
select * from table(dbms_xplan.display);
-- 인덱스 생성 및 생성 되었는지 확인
create index emp_deptno
on emp(deptno);
select * from user_indexes
where table_name ='EMP';
-- 인덱스 후 실행계획확인 (index scan)
explain plan for
select ename, sal, deptno
from emp
where deptno=10;
설명: emp 테이블이 14건 밖에 안 돼서 인덱스가 있던 없던 상관없이 빠르게 데이터가 검색되어서 튜닝을 한 것 같지가 않습니다. 그래서 튜닝한 효과를 볼 수 있도록 buffer의 개수를 확인해서 튜닝을 하겠습니다. buffer의 개수가 작게 읽어질수록 SQL튜닝을 잘한 겁니다.
문제 11. emp 테이블에 걸려있는 모든 인덱스를 다 삭제하시오!
DROP INDEX EMP_SAL;
DROP INDEX EMP_ENAME;
DROP INDEX EMP_HIREDATE;
DROP INDEX EMP_DEPTNO;
select * from user_indexes
where table_name ='EMP';
문제 12. 아래의 sql의 실행계획을 확인하는데 버퍼의 개수도 확인할 수 있게 실행 계획을 확인하시오.
select ename, sal
from emp
where sal =3000;
답)
select /*+ gather_plan_statistics */ ename, sal
from emp
where sal =3000;
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
※ 실행계획 보는 방법 2가지?
1. 예상 실행계획
explan plan for select ename, sal from emp where ename='SCOTT'; SELECT * from table(dbms_xplan.display);
2. 실제 실행계획 :
select /*+ gather_plan_statistics */ ename, sal from emp where ename='SCOTT';
SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
문제 13. 아래의 sql을 튜닝하시오(index 생성)
create index emp_sal
on emp(sal);
select * from user_indexes
where table_name ='EMP';
설명: 7개에서 2개로 줄음
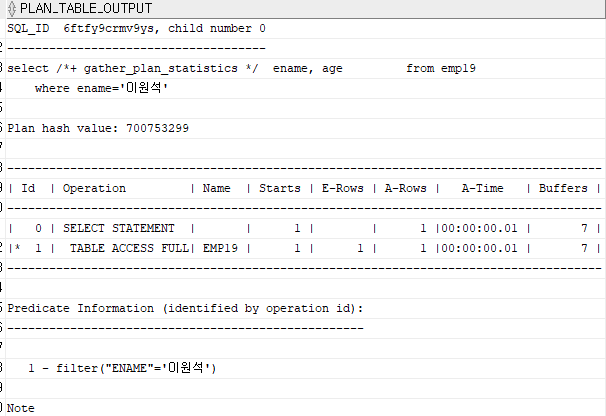
문제 14. 아래 sql을 튜닝하시오.
select ename, age
from emp19
where ename='이원석';
1) 튜닝 전 실행계획 확인
select /*+ gather_plan_statistics */ ename, age
from emp19
where ename='이원석';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
2) 인덱스 생성
create index emp19_ename
on emp19(ename);
3) 인덱스 생성 후 실행계획 확인
select /*+ gather_plan_statistics */ ename, age
from emp19
where ename='이원석';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
결론: buffers가 7개에서 2개로 줄었음 (실행이 빨라짐)
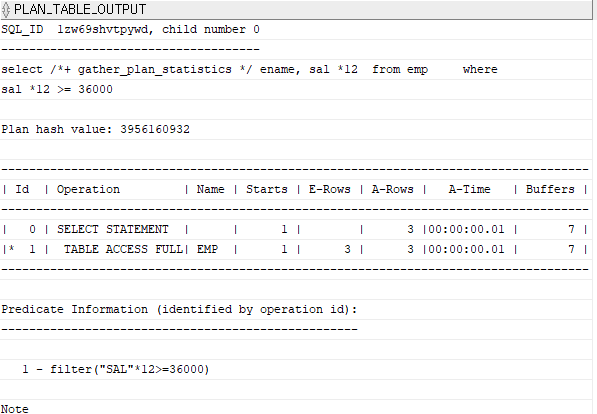
문제 15. 아래의 sql의 실행계획을 확인하시오. 튜닝 전
select ename, sal *12
from emp
where sal *12 >= 36000;
실행계획확인
select /*+ gather_plan_statistics */ ename, sal *12
from emp
where sal *12 >= 36000;
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
왜 full table scan을 했냐면 sal에 *12를 했기 때문입니다. 이를 전문 용어로 인덱스 칼럼을 가공했다고 합니다.
문제 16. 위의 sql을 튜닝하시오.
튜닝전:
select /*+ gather_plan_statistics */ ename, sal * 12 as 연봉
from emp
where sal * 12 >= 36000;
튜닝후:
select /*+ gather_plan_statistics */ ename, sal * 12 as 연봉
from emp
where sal >= 36000 /12 ;
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
문제 17. 아래의 SQL을 튜닝하시오.
1) 튜닝전 (7개)
select ename, job
from emp
where job ='SALESMAN';
2) 인덱스 생성
create index emp_job
on emp(job);
3) 튜닝후 (2개)
select /*+ gather_plan_statistics */ ename, job
from emp
where job ='SALESMAN';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
문제 18. 아래 sql을 튜닝하시오.
1) 튜닝전 (7개)
select ename, job
from emp
where substr(job,1,5) ='SALES';
select /*+ gather_plan_statistics */ ename, job
from emp
where substr(job,1,5) ='SALES';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
설명: job에 인덱스가 생성되어 있지만 위의 sql은 full table scan을 합니다. (where 절에 인덱스 칼럼이 substr로 가공되었기 때문)
튜닝후 (2개)
select /*+ gather_plan_statistics */ ename, job
from emp
where job like 'SALES%';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
문제 19. 아래 sql을 튜닝하시오.
1) 튜닝전 (7개)
select ename, hiredate
from emp
where to_char(hiredate,'RRRR')='1980';
select /*+ gather_plan_statistics */ ename, hiredate
from emp
where to_char(hiredate,'RRRR')='1980';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
2) 튜닝후 (2개)
select /*+ gather_plan_statistics */ ename, hiredate
from emp
where hiredate between to_date('1980/01/01','RRRR/MM/DD')
and to_date('1980/12/31','RRRR/MM/DD');
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
설명: where 절에 인덱스 칼럼을 가공하면 full table scan을 하게 되므로 인덱스 칼럼을 가공하면 안 됩니다.
문제 20. 내가 가지고 인덱스 리스트 확인하고 전부 drop 하시오.
select index_name
from user_indexes;
drop table EMP19_BIRTH ;
drop index EMP_SAL;
drop index EMP19_ENAME;
drop index EMP_JOB;
drop index EMP_HIREDATE;
98. SWQUENE
예제 98. 절대로 중복되지 않는 번호 만들기 (SEQUENE_일련번호 성기) - 테이블에 empno 같은 값은 unique 한 칼럼이 있어야 데이터 검색이나 머신러닝을 예측할 때 잘할 수 있다. - 사람이 emp 테이블에 empno의 값을 입력하게 되면 사람이 하는 일이다 보니 중복된 데이터를 입력할 수 있음. 그래서 시퀀스를 이용해 unique 하게 생성합니다.
Q1. 시퀀스 생성 문
create sequence seq1
start with 1
increment by 1
maxvalue 10000;
select seq1.nextval
from dual;
76 번 실행
create sequence seq1
start with 1
increment by 1
maxvalue 10000;
create table emp923
( empno number(10),
ename varchar2(10) );
insert into emp923 values(seq1.nextval, 'no name');
select * from emp923;
만약 시퀀스가 없었거나 또는 시퀀스라는 게 있는지 모르는 회사에서는 다음과 같이 insert를 합니다.
insert into emp923 valures(28, 'no name');
select max(empno)+1
from emp923;
insert into emp923 valures(29, 'no name');
# 불필요하고 수고스러운 행동
99. FLASHBACK QUERY
예제 99. 실수로 지운 데이터 복구하기 1(FLASHBACK QUERY) : flashback query 기술은 과거의 데이터를 확인하는 쿼리문입니다.
** 오라클의 타임머신 기능! 1. flashback Query : 과거의 데이터를 검색하는 기능 2. flashback table: 테이블을 과거시점으로 되돌리는 기능 3. flashback drop: 테이블을 휴지통에서 복구하는 기능 4. flashback version query: 테이블이 과거로부터 지금까지 어떻게 변경되어 왔는지 그 이력정보확인 5. flashback transaction query: 테이블을 과거로 되돌리기 위한 dml 문장을 보여주는 쿼리문.
문제 1. emp 테이블을 모두 delete 하고 commit 하세요
delete from emp;
commit;
문제 2. emp 테이블이 지워지기 전에 데이터 상태를 확인하시오.
select * from emp
as of timestamp
to_timestamp('2024/06/04 14:45:00','RR/MM/DD HH24:MI:SS');
문제 3. 위의 결과를 별도의 테이블로 백업하시오.
create table emp_20240604
as
select * from emp
as of timestamp
to_timestamp('2024/06/04 14:45:00','RR/MM/DD HH24:MI:SS');
문제 4. emp 테이블을 2024/06/04 14:45:00 초로 복구하시오.
alter table emp enable row movement;
flashback table emp to timestamp
to_timestamp('2024/06/04 14:45:00','RRRR/MM/DD HH24:MI:SS');
select * from emp;
commit;
문제 5. 내가 소유하고 있는 테이블들을 전부 백업하는 스크립트를 생성하시오.
select table_name
from user_tables;
문제 6. 내가 소유하고 있는 테이블들을 전부 백업하는 스크립트를 생성하시오
select ' create table ' || table_name || '_20240604 as
select * from ' || table_name || ';'
from user_tables
where table_name not like 'DM%';
문제 7. 테이블 데이터를 DB링크 없이 전달하는 방법 1) 명령 프롬프트창을 열고 다음과 같이 SQL포폴 테이블을 EXPORT 합니다.
2) 짝꿍에게 받은 emp.dmp 파일을 내 database에 import 합니다. -> 다운로드한 파일을 c드라이브에 넣기
imp c##scott/tiger tables=travel file=travel.dmp
문제 8. emp테이블을 전부 지우고 commit 하고 오 분 전으로 되돌리시오.
delete from emp;
commit;
alter table emp enable row movement;
flashback table emp to timestamp
(systimestamp - interval '5' minute);
문제 9.dept테이블을 모두 delete 하고 commit 하고 복구하시오.
-- 삭제
delete from dept;
commit;
-- 복구
alter table dept enable row movement;
flashback table dept to timestamp
(systimestamp - interval '5' minute);
100.FLASHBACK DROP
예제 100. 실수로 지운 데이터 복구하기 3. (FLASHBACK DROP) : 휴지통에서 DROP 된 테이블을 살려내는 복구 방법 Q1. 사원 테이블에 월급에 인덱스를 생성합니다.
create index emp_sal on emp(sal);
select index_name
from user_indexes
where table_name='EMP';
Q2. 사원 테이블을 DROP 하시오.
drop table emp;
Q3. 휴지통에 DROP 한 테이블이 있는지 확인 (1. show recyclebin 2. select * from user_recyclebin) ,
1.
show recyclebin
2.
select * from user_recyclebin
Q4. 휴지통에 있는 테이블을 복원하시오.
flashback table emp to before drop;
Q5. emp 테이블에 걸린 인덱스도 복구되는지 확인하시오.
select index_name
from user_indexes
where table_name ='EMP';
테이블을 DROP 하면 인덱스도 같이 DROP 되는데 테이블을 복원하면 인덱스도 복원이 됩니다. 그런데 다음과 같이 인덱스이름이 이상하게 보입니다.
Q6. 인덱스 이름을 원래 이름으로 변경합니다.
alter index "BIN$RHuwkVCkTru/5ffSFbT6Lg==$0" rename to emp_sal
;
Q7. 휴지통을 비우세요 ~
purge recyclebin;
show recyclebin;
문제 1. EMP테이블에 월급, 직업에 다음과 같이 인덱스를 거시오.
create index emp_sal on emp(sal);
create index emp_job on emp(job);
select index_name
from user_indexes
where table_name='EMP';
문제 2. emp테이블을 drop 하고 emp테이블에 걸린 인덱스도 같이 삭제되는지 확인하시오. (같이 drop 됨)
drop table emp;
select index_name
from user_indexes
where table_name='EMP
문제 3. 휴지통에 테이블과 인덱스가 있는지 확인하시오.
select * from user_recyclebin;
문제 4. emp 테이블을 휴지통에 복구하기 전에 인덱스 이름을 원래 이름으로 돌려놓는 스크립트를 생성하시오.
select ' alter index ' || '"' || object_name || '"' || ' rename to ' ||
original_name || ';'
from user_recyclebin
where TYPE='INDEX';
문제 5. EMP 테이블을 휴지통에서 빼내시오
flashback table emp to before drop;
문제 6. emp 테이블의 월급에 인덱스 구조를 확인하시오.
select sal, rowid
from emp
where sal>=0;
문제 7. 이름, 월급(낮은 사원부터 높은 사원 순) 출력하시오.
select ename, sal
from emp
order by sal asc;
설명: order by절이 빅데이터 환경에서 성능에 부하를 크게 줌 (따라서 튜닝된 데이터를 이용해야 함)
문제 8. 위의 sql을 튜닝하시오.
select ename, sal
from emp
where sal >=0;
설명: emp_sal 인덱스의 데이터를 읽어오려고 일부러 where 절에 sal >=0을 써줌
문제 9. 사원테이블에 ename 인덱스를 생성하시오.
create index emp_ename on emp(ename);
문제 10. 아래 sql을 튜닝하시오.
튜닝전
select ename, sal
from emp
order by ename;
튜닝후
select ename, sal
from emp
where ename >' ';
★ 문제 11. 아래 sql을 튜닝하시오 ( /*+ index_desc(emp emp_sal) */ 사용)
튜닝전
select ename, sal
from emp
order by sal desc;
튜닝후
select /*+ index_desc(emp emp_sal) */ ename, sal
from emp
where sal >=0;
설명: where절에 sal가 반드시 검색조건으로 있어야 하고 index_desc 힌트를 써서 emp_sal 인덱스를 descending 하게 정렬 시킴
★ 마지막 문제 1. 아래 sql을 튜닝하시오
-- 인덱스 추가
create index emp_hiredate on emp(hiredate);
튜닝전
select ename, hiredate
from emp
order by hiredate desc;
튜닝후
SELECT /*+ index_desc(emp emp_hiredate) */ ename, hiredate
from emp
where hiredate < = to_date('9999/12/31','RRRR/MM/DD');
★ 마지막 문제 2. 아래 sql을 튜닝하시오
튜닝전
select ename, sal
from emp
where job='SALESMAN'
order by sal desc;
튜닝후
SELECT /*+ index_desc(emp emp_sal) */ ename, sal
FROM emp
WHERE job='SALESMAN' AND sal >= 0;