[빅데이터분석] SQL_TIL 18(FLASHBACK VERSION QUERY,FLASHBACK TRANSACTION QUERY, PRIMARY KEY, UNIQUE, NOT NULL, CHECK, FOREIGN KEY)
chonny
2024. 6. 5. 17:24
★ 점심시간문제: 아래의 인덱스를 생성한 후 다음의 SQL을 튜닝하시오!
실행계획도 같이 출력해서 검사받으세요.
create index emp19_ename on emp19(ename);
튜닝 전:
select ename, age from emp19 where substr(ename,1,1)='김';
-- 실행후 & 실행계획 (buffers:2)
select ename, age
from emp19
where ename like '김%';
select /*+ gather_plan_statistics */ ename, age
from emp19
where ename like '김%';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
튜닝전 & 후
[TIL 18] 240605
[복습]
문제 1. 테이블 drop 할 때 휴지통 안 넣고 drop 하는 명령어를 수행하시오.
create table emp_backup3
as
select * from emp;
select * from emp_backup3;
답) 휴지통에도 안넣은 (purge)
drop table emp purge;
설명: 데이터 공간을 절약하기 위해 완전삭제 purge 함 (굳이 추천 x)
문제 2. emp_backup3 테이블의 이름을 emp로 변경하시오.
rename emp_backup3 to emp;
문제 3. emp 테이블의 sal칼럼을 salary로 변경하시오.
alter table emp
rename column sal to salary;
문제 4. emp테이블에 email이라는 컬럼을 추가하시오.
alter table emp
add email varchar2(100);
문제 5. email의 칼럼길이를 늘이시오.
alter table emp
modify email varchar2(200);
desc emp;
문제 6. 수치가 부적합합니다.라고 에러가 뜨면서 데이터입력이 안 되는 경우는? 1. 모든 칼럼을 문자현으로 해서 테이블을 생성합니다. 2. 엑셀 데이터를 sqldeveloper에 입력한다. 3. 다음과 같이 숫자로 변경한다.
create table emp234
as select to_number(empno)as empno, ename, to_number(sal) as sal ---;
문제 7. emp 테이블의 email 칼럼을 삭제하시오.
alter table emp
drop column email;
설명: 기계학습시킬 때 학습하기 부적합한 칼럼은 제거하는 게 바람직함
문제 8. EMP 테이블에 LOC 칼럼을 삭제하시오
alter table emp
drop column loc;
설명: 칼럼삭제는 rollback도 안되고 flashback도 안되니 신중하게 해야 함
101. FLASHBACK VERSION QUERY
예제 101. 실수로 지운 데이터 복구하기 4 (FLASHBACK VERSION QUERY)
** 오라클의 타임머신 기능! 1. flashback Query : 과거의 데이터를 검색하는 기능 2. flashback table : 테이블을 과거 시점으로 되돌리는 기능 3. flashback drop : 테이블을 휴지통에서 복구하는 기능 4. flashback version Query : 테이블이 과거로부터 지금까지 어떻게 변경되어 왔는지 그 이력정보 확인 5. flashback transaction Query : 테이블을 과거로 되돌리기 위한 DML문장을 보여주는 쿼리문
Q1. KING의 직업을 ANALYST로 변경하고 commit 하세요!
update emp
set job='ANALYST'
where ename='KING';
commit;
Q 2. KING의 월급을 0으로 변경하고 commit 하세요!
update emp
set sal=0
where ename='KING';
commit;
Q3. KING의 데이터를 지우고 commit 하세요!
delete from emp
where ename='KING';
commit;
Q4. 그동안 EMP테이블에서 KING의 데이터가 어떻게 변경되어 왔는지 그 이력정보를 확인하시오.
select versions_starttime, ename, sal , job, versions_operation
from emp
versions between timestamp to_timestamp('2024/06/05 10:10:00', 'RRRR/MM/DD HH24:MI:SS')
and maxvalue
where ename ='KING'
order by versions_starttime nulls first;
설명: 시간대별로 데이터를 어떻게 변경했는지 확인( u-update / d-delete)
Q5. flashback 하시오.
alter table emp enable row movement;
flashback table emp to timestamp to_timestamp('2024/06/05 10:10:00', 'RRRR/MM/DD HH24:MI:SS');
103.FLASHBACK TRANSACTION QUERY
예제 103. 실수로 지운 데이터 복구하기 5(FLASHBACK TRANSACTION QUERY) - 과거로 특저 테이블을 되돌리기 위해 DML문장을 보여주는 쿼리문
** 특정시간을 되돌아가기 : flashback table emp to timestamp 특정시간; ** 특정 DML작업만 선별해서 반대로 수행하고 싶을 때: flashback transaction query
104. PRIMARY KEY
예제 104. 데이터 품질 높이기 1 (PRIMARY KEY) * 제약(contraint)이란? -> 데이터의 품질을 높이기 위해서 데이터 베이스에 입력, 수정되는 데이터의 제한을 강제로 두는 기능 -> 결측치를 처리하는 부분이 데이터분석가들 한텐 어려움 (아예 처음부터 결측치가 입력 안되도록 테이블 설계)
* 제약의 종류 5가지?
1. primary key
중복된 데이터와 null 값을 입력하지 못하게 하는 제약
2. unique
중복된 데이터를 입력하지 못하게 하는 제약
3. not null
null 값을 입력 못하게 하는 제약
★ 4. check
사용자가 지정한 데이터만 허용하게끔 하는 제약
5. foreign key
부모 테이블의 데이터를 참조하기 위해서 사용하는 제약
문제 1. emp700이라는 테이블을 생성하는데 empno에 primary key제약을 걸고 생성하시오.
설명: 제약을 건 칼럼(고유한 행)에는 중복된 데이터와 null값을 입력할 수없음(ex. 주민등록증)
insert into emp700 values(1111,'scott',3000);
insert into emp700 values(1111,'allen',2000); -- 수행불가
insert into emp700 values(null,'smith',2000); -- 수행불가
문제 2. PRIMARY KEY 추가 및 설정
1) 일련번호 추가
SELECT ROWNUM AS T_ID, T.*
FROM EMP T;
2) 일련번호 만들어서 primary key 테이블 만들기
create table weather_2024
as
select rownum as t_id, t.*
from emp t;
select * from weather_2024;
3)★ 만들어진 테이블에 제약걸기
alter table emp
add constraint empno_pk primary key(empno);
select * from user_constraints
where table_name='EMP';
문제 3. DEPT테이블에 DEPTNO에 PRIMARY KEY 제약을 거시오
alter table dept
add constraint dept_pk_deptno primary key(deptno);
select * from user_constraints
where table_name='DEPT';
문제 4. fp_2021 테이블에 일련번호 칼럼을 만들고 primary key를 설정하시오.
-- 일련변호 column만들기
create table fp_2021_id
as
select rownum as B_id, B.*
from fp_2021 B;
SELECT * FROM fp_2021_id;
-- primary key 설정
alter table fp_2021_id
add constraint fp_2021_id_pk primary key(b_ID);
문제 5. 위 제약을 삭제하시오.
alter table fp_2021_id
drop constraint fp_2021_id_pk;
※ 인덱스 생성
1. 수동: create index 구문으로 인덱스를 생성
-> create index emp_ename on emp(ename);
2. 자동: primary key 나 unique 제약을 설명 자동으로 인덱스가 생성된다.
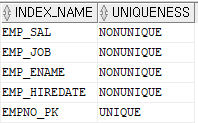
문제 6. emp 테이블에 empno에 현재 pk 가 걸려 있는데 index 도 같이 걸려있는지 확인하시오
select index_name, uniqueness
from user_indexes
where table_name ='EMP';
설명: INDEX도 PK가 걸려있음
문제 7. SALGRADE 테이블에 GRADE칼럼에 PRIMARY KEY 제약을 거시오.
alter table salgrade
add constraint sal_id_pk primary key(grade);
문제 8. SALGRADE 테이블에서 GRADE가 1인 모든 칼럼을 조회하시오
select * from salgrade
where grade =1;
문제 9. 위의 sql 실행계획을 확인하시오.
explain plan for
select * from salgrade
where grade =1;
select * from table(dbms_xplan.display);
문제 10. 아래의 sql을 튜닝하시오.
튜닝전
select * from salgrade
order by grade desc;
튜닝후
select /*+ index_desc(salgrade salgrade_pk) */ *
from salgrade
where grade >= 0 ;
105. UNIQUE
예제 105. 데이터 품질 높이기 2 (PRIMARY KEY) -> 중복된 데이터를 입력 못하게 막는 제약 * 제약 거는 방법 2가지 1) 테이블 생성 시
create table emp27
(empno number(10),
ename varchar2(10) constraint emp27_ename_un unique);
insert into emp27 values(1111, 'SCOTT'); --삽입완료
insert into emp27 values(1112, 'SCOTT'); --PK 중복값으로 인해 삽입 불가
2) 만들어진 테이블에
alter table emp
add constraint emp_enamme_un unique(ename);
update emp
set ename ='KING'
where ename ='SCOTT'; -- 무결성 제약 조건에 위배
문제 1. EMP19 테이블에 ename에 unique 제약을 거시오.
alter table emp19
add constraint emp19_ename_un unique(ename);
문제 2. emp테이블 직업에 unique 제약을 거시오
alter table emp
add constraint emp_job_un unique(job);
설명: unique 제약이 걸리려면 중복된 데이터 칼럼에 없어야 됨
문제 3. emp 테이블에 걸려있는 제약을 모두 삭제하시오.
1) emp 테이블 내 제약이 걸려있는 컬럼 확인
select constraint_name
from user_constraints
where table_name ='EMP';
2) 제약 삭제하기
alter table emp
drop constraint BIN$q7t4FtqsTiqDVVqxZ9UzHw==$3;
alter table emp
drop constraint EMPNO_PK;
alter table emp
drop constraint EMP_ENAMME_UN;
※ unique 제약이나 primary key 제약을 컬럼에 걸면 자동으로 인덱스가 만들어짐.
문제 4. emp 테이블의 ename에 unique제약을 걸고 인덱스가 만들어졌는지 확인하시오.
alter table emp
add constraint emp_ename_un unique(ename);
select index_name
from user_indexes
where table_name ='EMP';
106. NOTNULL
예제 105. 데이터 품질 높이기 3 (NOT NULL) : 결측치 (NULL)데이터를 입력하지 못하게 막는제약이 NOT NULL 제약임 ※ 제약 생성 방법? 1. 테이블을 생성할 때
create table emp59
(empno number(10),
ename varchar2(10),
sal number(10) constraint emp59_sal_nn not null);
# null이 들어가지 않는 sal 컬럼
2. 만들어진 테이블에
alter table emp
modify sal constraint emp_sal_nn not null;
update emp
set sal = null
where ename='KING';
문제1. emp테이블에 deptno에 not null 제약을 거시오.
alter table emp
modify deptno constraint emp_deptno_nn not null;
문제2. emp테이블에 comm에 not null 제약을 거시오.
alter table emp
modify comm constraint emp_comm_nn not null;
# 이미 comm에 null값이 있기 때문에 넣을 수 없음
107. CHECK
예제107. 데이터의 품질 높이기 4(CHECK) : check 제약은 사용자가 허락한 데이터만 입력 또는 수정할 수 있게 하는 제약
Q1. emp 테이블에 부서번호가 10번,20번,30번 외에 다른 부서번호는 입력 또는 수정할 수 없게 제약을 거시오 !
alter table emp
add constraint emp_deptno_ck check( deptno in (10,20,30) );
update emp
set deptno = 80
where ename='SCOTT';
문제 1. (제약이 유용한 경우) 사언 테이블에 월급에 check 제약을 거는데 월급이 0~9500사이의 데이터만 입력 또는 수정되게끔 제약을 거시오 .
alter table emp
add constraint emp_sal_ck check(sal between 0 and 9500);
문제 2. emp19에 통산사 컬럼에 check제약을 거는데 통신사가 sk, kt,lg,lg알뜰,sk알뜰, kt알뜰 외에는 입력 또는 수정되지 못하게 check제약을 거시오.
alter table emp19
add constraint emp19_telecom_ck
check(lower(telecom) in ('sk', 'kt','lg','lg알뜰','sk알뜰', 'kt알뜰'));
문제 3. (현업사례) 우리반 테이블 EMAIL에 CHECK제약을 거는데 @ 와 . 을 포함하지않은 이메일은 입력 또는 수정되지 않도록 하시오.
alter table emp19
add constraint emp19_email_ck1
check(email like '%@%.%');
문제 4. 정확한 데이터분석을 위해 제약에 위반된 데이터를 찾아서 제외시키기 위한 테이블을 다음과 같이 생성하시오.
insert into emp19(empno,ename, age, email)
values(37,'안상수',34,'aaaaaaa'); -- 품질이 안좋은 데이터
commit;
문제 7. 위와 상태에서 email 에 다음과 같이 체크제약을 거면 에러가 납니다.
alter table emp19
add constraint emp19_email_ck check( email like '%@%.%' );
문제 8. 위 제약에 위반된 데이터를 빠르게 찾을 수 있도록 제약을 걸때 위반된 데이터를 exceptions_table 에 입력되게 하시오 ! (불가)
alter table emp19
add constraint emp19_email_ck check( email like '%@%.%' )
exceptions into exceptions_table;
select * from exceptions_table;
select *
from emp19
where rowid in ( select row_id
from exceptions_table );
# 제약에 위반된 데이터들을 찾을 수가 있다.
설명: 제약에 위반된 데이터들을 찾을 수가 있다..
문제 9. exceptions_table을 truncate하시오.
truncate table exceptions_table;
문제 10.emp테이블의 아래의 데이터를 입력하시오
insert into emp(empno, ename, sal,deptno)
values(1234,'aaaa',4000,90);
문제 11. emp테이블에 deptno에 부서번호가 10,20,30만 입력되게 하는 체크 제약을 거는데 제약 위반 데이터에 대한 정보가 exceptions_table에 입력되게하시오.
alter table emp
add constraint emp_deptno_ck check(deptno in(10,20,30))
exceptions into exceptions_table;
108. FOREIGN KEY
예제108. 데이터의 품질 높이기 5(FOREIGN KEY)
설명: dept 테이블에 deptno 에 primary key 제약을 걸고 emp 테이블에 deptno 에 foreign key 제약을 걸면서 부모 자식관계를 형성해 놓으면 emp 테이블에 deptno 에 아무런 부서번호를 입력할 수 없고 dept 테이블에 deptno 도 함부로 지울 수 없게 됩니다.
문제 1. dept 테이블에 deptno에 primary key 제약을 거시오
alter table dept
add constraint dept_deptno_pk primary key(deptno);
- 컬럼명 설명: distress_ct : O형링 파손수 temperature : 온도 field_check_pressure : 압력 flight_num : 비행기 번호
Q. O형링이 파손수에 영향을 가장 크게 준것이 온도인지, 압력인지, 비행기 노후화와 관련된 비행기 번호인지 알아내는 분석
문제 1. challengers 테이블에 c_id라는 컬럼을 생성하는데 번호를 1번부터 유니크하게 부여하는 컬럼으로 생성하시오.
create table challengers_1
as
select rownum as c_id, c.*
from challengers c;
select * from challengers_1
문제 2. 머신러닝 모델의 환경구성 테이블을 생성하시오.
-- 3. 머신러닝 모델의 환경 구성 테이블을 생성합니다. ----------
drop table settings_ch;
create table settings_ch
as
select *
from table (dbms_data_mining.get_default_settings)
where setting_name like '%GLM%';
select * from settings_ch;
begin
insert into settings_ch
values (dbms_data_mining.algo_name,'ALGO_GENERALIZED_LINEAR_MODEL');
insert into settings_ch
values (dbms_data_mining.prep_auto, 'ON');
commit;
end;
/
select * from settings_ch;
-- 5. 생성된 머신러닝 모델을 확인합니다.
select model_name,
algorithm,
mining_function
from all_mining_models
where model_name = 'MD_REG_MODEL2';
문제
-- 6. 머신러닝 모델 구성 정보를 확인합니다.
select setting_name, setting_value
from all_mining_model_settings
where model_name = 'MD_REG_MODEL2';
-- 7. 회귀분석 모델의 회귀계수를 확인합니다.
select attribute_name, p_value
from table (dbms_data_mining.get_model_details_glm ('MD_REG_MODEL2'));
★ ★ 강사님 질문
실습2. challengers 테이블에 c_id 라는 컬럼을 생성하는데 번호를 1번부터
유니크하게 부여하는 컬럼으로 생성하시오 !
create table challenger
as
select rownum as c_id, c.*
from challengers c ;
select * from challenger;
실습3. 머신러닝 모델의 환경구성 테이블을 생성합니다.
drop table settings_ch;
create table settings_ch
as
select *
from table (dbms_data_mining.get_default_settings)
where setting_name like '%GLM%';
select * from settings_ch;
begin
insert into settings_ch
values (dbms_data_mining.algo_name,'ALGO_GENERALIZED_LINEAR_MODEL');
insert into settings_ch
values (dbms_data_mining.prep_auto, 'ON');
commit;
end;
/
select * from settings_ch;
실습4. 머신러닝 모델을 생성합니다.
begin
dbms_data_mining.drop_model('MD_REG_MODEL2');
end;
/
begin
dbms_data_mining.create_model(
model_name => 'MD_REG_MODEL2',
mining_function => dbms_data_mining.regression,
data_table_name => 'challenger',
case_id_column_name => 'c_id',
target_column_name => 'distress_ct',
settings_table_name => 'SETTINGS_ch');
end;
/
설명: 지난번 미국민 의료 데이터는 테이블을 훈련 테이블과 테스트 테이블로
나눠서 분석 했는데 이번 데이터는 데이터의 양이 작아서 그냥 안나누고
학습 시킬것이고 어느 컬럼이 O 형링 파손에 영향이 가장 큰지를 알아내기만
하면 됩니다.
-- 실습5. 생성된 머신러닝 모델을 확인합니다.
select model_name,
algorithm,
mining_function
from all_mining_models
where model_name = 'MD_REG_MODEL2';
-- 실습6. 머신러닝 모델 구성 정보를 확인합니다.
select setting_name, setting_value
from all_mining_model_settings
where model_name = 'MD_REG_MODEL2';
-- 실습7. 회귀분석 모델의 회귀계수를 확인합니다.
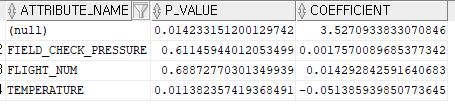
select attribute_name, p_value, coefficient
from table (dbms_data_mining.get_model_details_glm ('MD_REG_MODEL2'));
attribute_name p_value coefficient
0.014233151200129742 3.5270933833070846
FIELD_CHECK_PRESSURE 0.61145944012053499 0.0017570089685377342
FLIGHT_NUM 0.68872770301349939 0.014292842591640683
TEMPERATURE 0.011382357419368491 -0.051385939850773645
설명: coefficient 의 값이 distress_ct 에 영향력 정도를 수치화 한것이빈다.
3.5270933833070846 <---- 절편
FIELD_CHECK_PRESSURE 0.0017570089685377342 <--- 압력에 대한 기울기
FLIGHT_NUM 0.014292842591640683 <--- 비행기 번호에 대한 기울기
TEMPERATURE -0.051385939850773645 <--- 온도에 대한 기울기
분석결과: 온도가 가장 기울기가 크게 나타나고 있어서 o형링 파손에 가장 크게
영향을 준것은 온도라고 할 수 있습니다. 온도가 낮을 수록 o형링 파손이
더 높아지고 있습니다.
y = 3.5270933833070846 + 0.0017570089685377342 * x1 +
0.014292842591640683 * x2 +
-0.051385939850773645 * x3
y : o형링 파손수
x1 : 압력
x2 : 비행기 번호
x3 : 온도
기울기가 가장 큰게 온도이므로 온도가 o 형링 파손수에 가장 영향력이 큰
독립변수입니다.
온도와 o형링 파손수만 가지고 따로 단순회귀분석을 시도합니다.
연습 문제1. 온도와 o형링 파손수에대한 회귀계수를 구하시오
1. 온도,o형링 테이블 생성합니다.
create table nasa_table
as select c_id, distress_ct, temperature
from challenger;
2.온도가 o형링 파손에 얼마나 영향을 미치는지 회귀계수 을 구하시오.
실습3. 머신러닝 모델의 환경구성 테이블을 생성합니다.
drop table settings_ch;
create table settings_ch
as
select *
from table (dbms_data_mining.get_default_settings)
where setting_name like '%GLM%';
select * from settings_ch;
begin
insert into settings_ch
values (dbms_data_mining.algo_name,'ALGO_GENERALIZED_LINEAR_MODEL');
insert into settings_ch
values (dbms_data_mining.prep_auto, 'ON');
commit;
end;
/
select * from settings_ch;
실습4. 머신러닝 모델을 생성합니다.
begin
dbms_data_mining.drop_model('MD_REG_MODEL2');
end;
/
begin
dbms_data_mining.create_model(
model_name => 'MD_REG_MODEL2',
mining_function => dbms_data_mining.regression,
data_table_name => 'nasa_table',
case_id_column_name => 'c_id',
target_column_name => 'distress_ct',
settings_table_name => 'SETTINGS_ch');
end;
/
설명: 지난번 미국민 의료 데이터는 테이블을 훈련 테이블과 테스트 테이블로
나눠서 분석 했는데 이번 데이터는 데이터의 양이 작아서 그냥 안나누고
학습 시킬것이고 어느 컬럼이 O 형링 파손에 영향이 가장 큰지를 알아내기만
하면 됩니다.
-- 실습5. 생성된 머신러닝 모델을 확인합니다.
select model_name,
algorithm,
mining_function
from all_mining_models
where model_name = 'MD_REG_MODEL2';
-- 실습6. 머신러닝 모델 구성 정보를 확인합니다.
select setting_name, setting_value
from all_mining_model_settings
where model_name = 'MD_REG_MODEL2';
-- 실습7. 회귀분석 모델의 회귀계수를 확인합니다.
select attribute_name, p_value, coefficient
from table (dbms_data_mining.get_model_details_glm ('MD_REG_MODEL2'));
** 단순 회귀식 (coefficient) y = 3.7 - 0.048 * x(온도) 1 2.26개 30도 F(화씨) 0.82개 60도 F(화씨) 0.34개 70도F(화씨) ※ 분석결과: 화씨 30도에서 발사하는게 화씨 60도에서 발사하는 것 보다 3배더 위험하고 70도에서 발사하는 것보다 7-8배 더 위험하다.
★ 마지막문제. 스마트폰 만족도에 가장 영향을 미치는 요소가 무엇인지 알아내시오 (외관, 편의성, 유용성 중에서) 데이터: multi_hg.csv
-- 테이블 만들기
create table smartphone
(
외관 number(10),
편의성 number(10),
유용성 number(10),
만족감 number(10));
-- 테이블 확인
select * from smartphone;
-- 일련번호 컬럼 추가하기
create table smartphone_1
as
select rownum as s_id, s.*
from smartphone s;
commit;
-- 머신러닝 모델의 환경구성 테이블을 생성합니다.
drop table settings_ch;
create table settings_ch
as
select *
from table (dbms_data_mining.get_default_settings)
where setting_name like '%GLM%';
select * from settings_ch;
begin
insert into settings_ch
values (dbms_data_mining.algo_name,'ALGO_GENERALIZED_LINEAR_MODEL');
insert into settings_ch
values (dbms_data_mining.prep_auto, 'ON');
commit;
end;
/
select * from settings_ch;
-- 머신러닝 모델을 생성
begin
dbms_data_mining.drop_model('MD_REG_MODEL2');
end;
/
begin
dbms_data_mining.create_model(
model_name => 'MD_REG_MODEL2',
mining_function => dbms_data_mining.regression,
data_table_name => 'smartphone',
case_id_column_name => 's_id',
target_column_name => '만족감',
settings_table_name => 'SETTINGS_ch');
end;
/
-- 생성된 머신러닝 모델을 확인
select model_name,
algorithm,
mining_function
from all_mining_models
where model_name = 'MD_REG_MODEL2';
-- 머신러닝 모델 구성 정보를 확인
select setting_name, setting_value
from all_mining_model_settings
where model_name = 'MD_REG_MODEL2';
-- 회귀분석 모델의 회귀계수를 확인
select attribute_name, p_value, coefficient
from table (dbms_data_mining.get_model_details_glm ('MD_REG_MODEL2'));
\
외관이 가장 높다