# 5. 가장 연관성이 높은 항목들이 어떤건지 출력합니다.
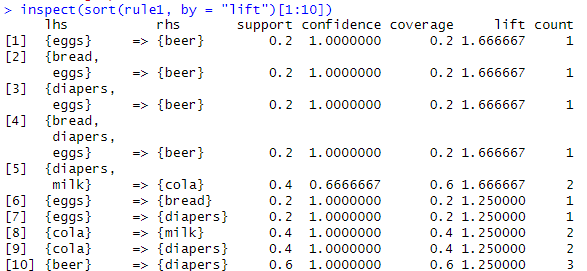
inspect(sort(rule1, by = "lift")[1:10]) # 향상도가 3가지중에 가장 중요한 연관 척도므로
# 향상도로 정렬합니다.
support 0.2 라는 것은 전체 거래중에 20% 에서 egg과 beer 가 함께 등장 confidence 1.0 라는것은 eggs 가 포함된 거래중 100%d에서 beer 도 포함 coverage 0.2 라는 것은 전체 거래중에서 20% 가 eggs 가 포함 lift 1.66 eggs 를 사면 beer 살 확률이 1.666 배 크다는 얘기
※ 결과해석: 1. 가장 신뢰도와 향상도가 높은 데이터 찾기: 1) 높은 신뢰도를 보이는 1.0에 해당하는 아이템들이 함께 구매될 가능성이 매우 높음을 나타냄 2) 향상도가 1보다 큰 아이템들은 긍정 연관아이템들로 독립적으로 구매 되었을 때 보다 하멕 구매될 가능성이 더 높은 아이템들임
2. 숨은 보물 찾기:
위의 연관 규칙은 신뢰도는 1이지만 향상도가 1.66으로 여전히 높은 편 이는 diapers, milk 를 구매했을 때 cola도 함께 구매하는 경우가 많음을 시사함
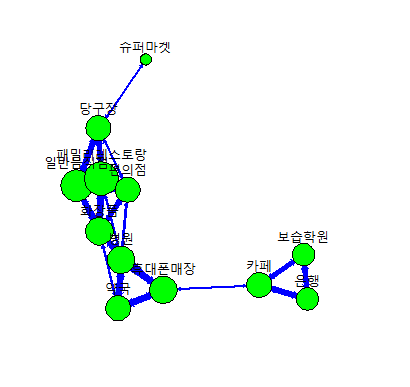
동그라미를 노드라고 선을 엣지라고 함. - 노드의 크기는 해당 아이템이 거래에서 얼마나 자주 나타나는지를 나타냄. (빵과 우유와 기저귀의 노드가 크다는것은 거래를 많이 한다는 것을 의미함) - 엣지의 굵기는 두 아이템에 함께 나타나는 빈도를 나타냄 ( 빵과 우유의 엣지가 굵으므로 함께 구매되는 경우가 많음) - 엣지의 방향은 연관 규칙의 방향을 의미 (기저귀와 우유를 함께 살 확률이 높아 보이므로 기저귀와 우유를 같이 상품진열을 해서 추가 판매를 유도할 수 있음)
■ 연관규칙 두번째 실습 건물 20개를 조사해서 각각 어떤 업종이 입점되어져 있는지 조사한 데이터
# 데이터 로드드
setwd('c:\\data')
bd <- read.csv("c:\\data\\building.csv", header=T , fileEncoding ='euc-kr')
View(bd)
# 필요없는 행 제거
bd2<- bd[ ,-1]
bd2
# 결측치 값 0으로 대체
bd2[is.na(bd2)] <- 0
bd2
# 행렬 변환
bd3<-as.matrix(bd2,'Transaction')
bd3
# 신뢰도 0.2 이상인 연관규칙 확인
library(arules)
rule2<- apriori(bd3, parameter = list(supp=0.2,conf=0.6,target='rule'))
rule2
inspect(sort(rule2))
전체 건물중 40%에서 일반 음식점과 패밀리 레스토랑이 함께 등장 일반음식점이 있는 건물중 100%가 다 패밀리 레스토랑이 입점함 ->이 규칙은 일반 음식점과 패밀리 레스토랑이 건물에 같이 있음을 의미함.
설명: 카페-은행-보습학원이 서로 연결되어있음(사람들이 은행을 방문할 때는 보습학원이나 은행을 자주간다는 뜻)
※ 연관분석 시각화 하려면 희소행렬이 필요함. - 희소행렬은 대부분의 요소들이 0인 행렬임 - 희소행렬을 이용하면 단어의 빈도, 연관분석 그래프 표현, 추천 시스템의 단어 빈도 등에서 사용이 됨.
■ 전세사기 예방 연관 데이터 분석 데이터: 등기부등본에 명시된 데이터: 가압류, 근저당 설정 등
# 필요한 패키지 설치 및 로드
if (!require("arules")) {
install.packages("arules")
library(arules)
}
# 가상의 데이터 생성
set.seed(123) # 결과 재현을 위해 시드 설정
data <- data.frame(
contract_id = paste0("전세방", 1:94),
무자본_갭투자 = factor(sample(c(0, 1), 94, replace = TRUE, prob = c(0.6, 0.4))),
시세보다_저렴한_전세가 = factor(sample(c(0, 1), 94, replace = TRUE, prob = c(0.4, 0.6))),
근저당권_설정_금액_비율 = factor(sample(c("낮음", "중간", "높음"), 94, replace = TRUE, prob = c(0.2, 0.3, 0.5))),
가압류_가처분_권리_제한 = factor(sample(c(0, 1), 94, replace = TRUE, prob = c(0.7, 0.3))),
다수의_전세권_설정 = factor(sample(c(0, 1), 94, replace = TRUE, prob = c(0.7, 0.3))),
압류_경매_절차_진행 = factor(sample(c(0, 1), 94, replace = TRUE, prob = c(0.7, 0.3))),
신탁_등기 = factor(sample(c(0, 1), 94, replace = TRUE, prob = c(0.9, 0.1))),
건물_용도 = factor(sample(c("주거용", "비주거용"), 94, replace = TRUE, prob = c(0.8, 0.2))),
전세_사기_발생 = factor(sample(c(0, 1), 94, replace = TRUE, prob = c(0.5, 0.5)))
)
# 데이터 프레임을 transactions 형식으로 변환
data_trans <- as(data[, -1], "transactions")
# apriori 알고리즘을 사용하여 연관 규칙 생성
rules <- apriori(data_trans, parameter = list(supp = 0.1, conf = 0.3))
# 근저당권 설정 금액 비율이 높음이고 시세보다 저렴한 전세가가 1이며 전세 사기 발생에 대한 규칙만 필터링
filtered_rules <- subset(rules, subset = rhs %pin% "전세_사기_발생=1" & lhs %pin% "근저당권_설정_금액_비율=높음" & lhs %pin% "시세보다_저렴한_전세가=1")
filtered_rules <- sort(filtered_rules, by = "lift")
# 상위 5개의 규칙만 선택하여 출력
top_rules <- head(filtered_rules, 5)
inspect(sort(top_rules))
■ 보이스 피싱 연관분석 코드
# 필요한 패키지 설치 및 로드
if (!requireNamespace("arules", quietly = TRUE)) {
install.packages("arules")
}
library(arules)
# 불필요한 단어들을 제거하는 함수 정의
remove_stop_words <- function(text, stop_words) {
text <- unlist(strsplit(text, " "))
text <- text[!(text %in% stop_words)]
return(text)
}
# Stop words 리스트
stop_words <- c("있습니까", "입니다", "에", "는", "이", "이요", "있고", "라고", "의", "와", "과", "로", "에", "를", "과", "다", "가", "은", "는", "의", "들", "것", "입니다", "이요",
"괜찮으실까요", "우선", "전", "네", "지금", "제가", "저희", "좀", "한", "이번", "있는", "없는", "대해서", "들", "이런", "하게", "해서", "아니면", "어떤", "또는",
"사건", "이유", "말씀드리기", "말씀", "드릴", "드렸는데요", "텐데요", "건", "내용", "제", "저", "안", "말씀을", "부탁드립니다", "답변", "관해서", "부탁", "합니다", "문의")
# 보이스 피싱 텍스트 데이터를 리스트로 준비합니다.
data <- list(
"서울중앙지검에 이주화 수사관 다름 아니라 명의도용 고소 고발 몇 확인차 전화",
"통화 괜찮으실까요 우선 사건 내용 말씀드리기 전 명의 도용한 주범 대해 말씀드릴 텐데요",
"지인분 아시는 분 바로 말씀 주세요",
"전라도 광주 태생 40대 남성 김성우 사람 알고",
"일면식 없고 전혀 모르는 사람 김성호 사람 대해 여쭤보는 이유 저희 지검 이번 김성호 주범 금융범죄 사기단 검거",
"문 안 대량 대포통장 신용카드 개인 정보 들어 파일 증거 물품 압수",
"명의 농협 하나은행 통장 발견 연락",
"농협 하나은행 통장"
# 추가 문장을 단어로 분리하여 추가
)
# 데이터 전처리: Stop words 제거
data_cleaned <- lapply(data, remove_stop_words, stop_words)
# 트랜잭션 데이터로 변환
transactions <- as(data_cleaned, "transactions")
# 트랜잭션 데이터 확인
summary(transactions)
# 연관 규칙 분석 수행
frequent_items <- apriori(transactions, parameter = list(supp = 0.1, conf = 0.1, maxlen = 10))
# maxlen = 10 최대 규칙 10개의 아이템으로 출력하겠다.
# 지지도, 신뢰도, 향상도 등 결과 확인, {}가 포함된 규칙 제외
rules <- subset(frequent_items, subset = size(lhs) > 0 & lift > 1)
# 결과 확인
inspect(sort(rules))
연관분석이 꼭 마트에서 물건많이 팔려고만 데이터 분석하는 것이 아니라 금융사기 탐지,전세사기, 보이스피싱 예방에 응용될 수 있음.
비지도 학습은 정답이 없는 데이터를 훈련 시켜서 그 안에 숨은 패턴을 찾는 머신러닝 기법임.
★ 마지막 문제: R에 내장된 데이터 중 Groceries 를 이용해서 연관 규칙분석을 하시오. (상위 10개의 규칙을 lift의 기준으로 정렬)
# 필요한 패키지 설치 및 로드
if (!require("arules")) {
install.packages("arules")
library(arules)
}
# Groceries 데이터 로드
data("Groceries")
# 데이터 요약 확인
summary(Groceries)
# 처음 5개의 트랜잭션 확인
inspect(Groceries[1:5])
# 데이터의 전체 구조 확인
str(Groceries)
rules <- apriori(Groceries,parameter = list(supp=0.01, conf=0.5))
summary(rules)
# 상위 10개의 규칙만 선택하여 출력
inspect(sort(rules, by = "lift")[1:10])