우리반 테이블에서 태어난 요일을 출력하고 태어난 요일별 인원수를 출력하는데 태어난 요일별 인원수가 4명이상인것만 출력하고 태어난 요일별 인원수가 높은것부터 출력하시오
select to_char(birth, 'day')요일, count(*)
from emp19
group by to_char(birth, 'day')
having count(*) >= 4
order by 2 desc;
[TIL 15]240531
* SQL을 통해서 데이터 분석 질문들
1. 순위를 통한 데이터분류
2. 데이터간 상관관계 분석
3. SQL로 회귀분석(수치예측)
89. 계층형 질의문_서열
1. ORDER SIBLINGS BY
2. 가지치기 (PRUNING)
3. SYS_CONNECT_BY_PATH
예제 89. 계층형 질의문으로 서열을 주고 데이터 출력하기1. 서열이란? 1) 순위하고 차이가있음 2) 어떤 크기나 중요도에 따라서 기준을 나누는 것 3) 항목들간 상대적인 위치나 순서를 나타냄
순위란? 1) 특정 기준에 따라서 항목들에게 등급이나 점수를 매기고 그에 따른 순서를 부여하는 것
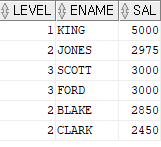
문제1.1. 사원번호, 사원이름, 관리자 번호를 출력하시오.
select empno, ename, mgr
from emp;
설명: mgr은 관리자 번호인데 서열을 부여하는 중요한 컬럼
문제 1.2. 서열, 사원번호, 사원이름, 관리자 이름을 출력하시오.
select level, empno, ename, mgr
from emp
start with ename = 'KING' --누구부터 시작해서 서열을 부여할 것인가
connect by prior empno =mgr; --서열을 표시해주기 위해 연결 키컬럼들을 기술
문법: start with (서열 시작 ) connect by prior 부모키 컬럼 = 자식키 컬럼
문제 2. 이름이 clark을 시작점으로 두고 서열 순서를 출력하시오.(서열,사원번호,사원이름,직업, 월급을 출력하시오)
select level, empno, ename, job, sal
from emp
start with ename ='CLARK'
connect by prior empno = mgr;
문제 3.1. 이름이 킹인 사원을 서열 1위로 하고 서열, 이름, 월급을 출력하는데 월급이 2400 이상인 사원들만 출력하시오,
select level, ename, sal
from emp
where sal >=2400
start with ename ='KING'
connect by prior empno =mgr;
문제 3.2 위 sql의 실행 순서를 실행계획을 보면서 확인하시오.
explain plan for
select level, ename, sal
from emp
where sal >=2400
start with ename ='KING'
connect by prior empno =mgr;
select *from table(dbms_xplan.display);
설명: from 절을 먼저 실행해서 emp 테이블을 가져오고 start with와 connect by절을 실행해서 서열 부여하고 where 절 실행해서 월급이 2400인 것만 출력했다.
문제 4. 사원 테이블에서 서열, 이름, 월급, 부서번호를 출력하는데 20번 부서번호에서 근무하는 사원들만 출력하시오.
select level, ename, sal, deptno
from emp
where deptno =20
start with ename ='KING'
connect by prior empno =mgr;
문제 5. KING을 서열 1위로 해서 서열과 이름과 월급을 출력하는데 월급이 높은 사원부터 출력하시오 !
select level, ename, sal
from emp
start with ename ='KING'
connect by prior empno =mgr
order by sal desc;
문제6. king을 서열 1위로 해서 서열, 이름,월급 을 출력하는데 서열을 확실히 구분하기 위해 이름 앞에 공백을 넣으시오 (데이터 이해를 위한 데이터 시각화)
select rpad(' ', level*2)||ename as employee, sal
from emp
start with ename ='KING'
connect by prior empno =mgr;
설명: rpad(' ', level*2) 는 공백을 level*2 만큼 채워넣겠다는 뜻입니다. level 이 크면 클수록 앞에 공백이 많이 채워집니다.
문제 7. 위의 결과에서 월급이 높은 순으로 출력하시오.
select rpad(' ', level*2)||ename as employee, sal
from emp
start with ename ='KING'
connect by prior empno =mgr
order by sal desc ;
설명: order by를 쓰니까 누가 누구 밑에 있는 사원인지 구분할 수 없게 됨. 계층형 질의문에서 order by를 사용할때 짝꿍 키워드가 있다.(order siblings by: 서열을 깨뜨리지 않으면서 누가 누구밑에 있는지 알수있음)
select rpad(' ', level*2)||ename as employee, sal
from emp
start with ename ='KING'
connect by prior empno =mgr
order siblings by sal desc ;
문제 8. 위의 sql을 이용해서 서열, 이름, 입사일을 출력 하고 입사일이 먼저 입사한 사원순으로 출력하고 출력되는 결과가 서열 별로 각각 먼저 입사한 사원 순으로 출력되게 하시오.
select rpad(' ', level*2)||ename as employee, hiredate
from emp
start with ename= 'KING'
connect by prior empno = mgr
order siblings by sal desc ;
90. 계층형 질의문_서열2
예제 90. 계층형 질의문으로 서열을 주고 데이터 출력하기 2. Q. 서열대로 이름을 출력하는데 이름 앞에 RPAD로 공백을 넣어서 서열을 구분할 수 있도록 출력하시오.
employee, hiredate
from emp
start with ename= 'KING'
connect by prior empno = mgr
order siblings by sal desc ;
Q2. 위의 결과에서 blake는 제외하고 출력하시오
select rpad(' ',level*2) ||ename as employee, hiredate
from emp
where ename <> 'BLAKE'
start with ename= 'KING'
connect by prior empno = mgr
order siblings by sal desc ;
Q3. 위결과에서 BLAKE의 팀원 모두도 안나오게하시오. (가지치기_PRINING)
select rpad(' ',level*2) ||ename as employee, hiredate
from emp
start with ename= 'KING'
connect by prior empno = mgr and ename 'BLAKE'
order siblings by sal desc ;
설명: 하위 레벨까지 안나오게하려면 where 절이아닌 connect by 절에 조건을 줘야됨
문제 1. 위 결과에서 JONES와 아래 팀원들도 안나오게 하시오.
select rpad(' ',level*2) ||ename as employee, hiredate
from emp
start with ename= 'KING'
connect by prior empno = mgr and ename not in ( 'BLAKE', 'JONES')
order siblings by sal desc ;
91. 계층형 질의문_서열3
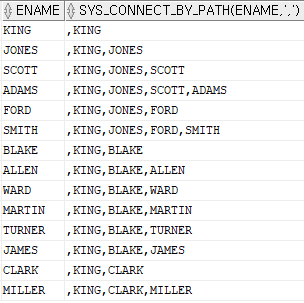
예제 91. 계층형 질의문으로 서열을 주고 데이터 출력하기 3. Q. sys_connect_by 함수를 사용하여 다음 SQL을 작성하시오.
select ename, sys connect_by_path(ename,',')
from emp
start with ename = 'KING'
connect by prior empno = mgr;
설명: sys_connect_by_path를 이용해서 자기의 위치가 전체 사원들에서 정확한 서열 위치가 어떻게 되는지 출력해 줄 수 있다.
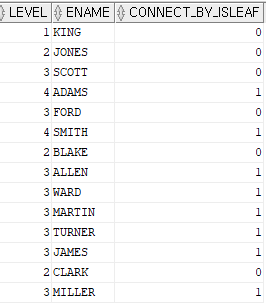
문제1. 사원이름, 해당 사원이 말단 사원이면 1아니면 0을 출력하시오.
select level , ename, connect_by_isleaf
from emp
start with ename = 'KING'
connect by prior empno = mgr ;
92. 계층형 질의문_서열4
예제 92. 계층형 질의문으로 서열을 주고 데이터 출력하기 4. Q1. 계층형 질의문을 이용해서 숫자를 1-10까지 출력하시오.
select level from dual connect by level <=10
* 텍스트 마이닝(mining)? - 자연어 처리의 통계적, 기계학습기법을 활용하여 대량의 텍스트 데이터에서 유용한 정보를 추출하고 패턴을 반결하는 기술 - 비정형 데이터인 텍스트를 분석하여 의미있는 정보를 찾아내는 것을 목표로함.
* regexp_substr 는 정규 표현식(expression)을 지원하는 함수 -> oracle의 substr 함수에 적용한 것. 그냥 substr 함수가 그냥 잘라내는 함수라면 regexp_substr 함수는 좀더 정교하게 잘라내는 함수임.
select num,loc
from dept, (select level as num
from dual
connect by level <=5);
설명: where 절없이 조인하니까 숫자1과 dept 테이블과 조인하고 숫자2가 dept 테이블과 조인하고 이렇게 숫자5까지 dept 테이블과 조인한 결과가 출력되었습니다.
문제 3. duk_table 과 숫자 1-30까지 출력하는 쿼리문과 조인해서 duk_ table 문장을 어별별로 토큰화 하시오.
select regexp_substr(t.u_comment,'[^ ]+',1,v.num)
from duk_table t, (select level as num
from dual
connect by level <= 30) v;
문제 4. 위의 결과를 duk_word라는 테이블로 생성하시오.
create table duk_word
as
select regexp_substr(t.u_comment,'[^ ]+',1,v.num) as word
from duk_table t, (select level as num
from dual
connect by level <= 30) v;
select * from duk_word;
문제 5. duk_word에서 word를 출력하고 word별 건수를 count 하는데 word별 건수가 높은것 부터 출력하시오.
select word , count(*)
from duk_word
where word is not null
group by word
order by 2 desc;
-> 두 개 이상의 변수간의 관계를 분석하여 얼마나 밀접하게 관련되어 있는지를파악하는 방벙입니다.
[ 상관관계를 해석하는 방법 3가지 ]
1. 양의 상관관계
한 변수가 증가할 때 다른 변수도 증가하는 경향이 있는 경우 ex) 키와 몸무게
2. 음의 상관관계
한 변수가 증가할 때 다른 변수는 감소하는 경향이 있는 경우 ex)자동차의 연비와 무게
3. 상관관계 없음
변수간의 명확한 관계가 없는 경우 ex) 아이스크림 판매량과 신발 크기.
상관관계 측정 수치: 상관계수
0.0 ~ 0.2
상관관계가 거의 없다.
0.2 ~ 0.4
상관관계가 낮다
0.4 ~ 0.6
상관관계가 있다
0.6 ~ 0.8
상관관계가 높다
0.8 ~ 0.1
상관관계가 매우 높다
-> 두 개의 데이터가 얼마나 서로 상관이 있는지 수치로 나타냄 ( -1 ~ 1 사이의 수치) 상관계수가 0 이면 두개는 서로 상관이 없다. -1 에 가까우면 음의 상관관계입니다. 1 에 가까우면 양의 상관관계입니다. -> 상관계수를 구하는 오라클 함수? corr(컬럼명1, 컬럼명2)
문제 3. 주행거리가 많은 중고차의 가격은 더 저렴한지 알아내시오. (상관관계 데이터 분석)
select corr( mileage, price )
from usedcar;
= 상관관계가 매우 높다
문제 4 중고차 년식은 가격과 어떤 상관관계가 있나요?
select corr( car_year, price )
from usedcar;
= 상관관계가 매우 높다
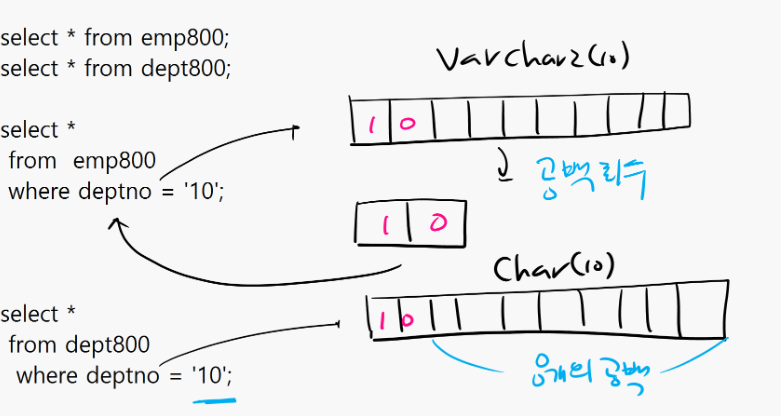
※ char와 varchar2의 차이
1. char 는 고정형 문자 데이터 타입 2. varchar2 는 가변형 문자 데이터 타입
설명: varchar2는 char과 다르게 남은공간을 회수해 감.
문제 1. 왜 char보다 varchar을 더 많이 쓰는가?
create table emp800
( ename varchar2(10),
deptno varchar2(10) );
create table dept800
( deptno char(10),
loc char(10) );
insert into emp800 values('scott', '10');
insert into emp800 values('allen', '20');
select * from emp800
where deptno = '10';
select * from dept800
where deptno = '10';
Q2.
select e.ename, d.loc
from emp800 e, dept800 d
where e.deptno = d.deptno;
결과가 출력되지 않음 -> 따라서 VARCHAR2로 통
문제2. (복습) 스티브 잡스 연설문에는 어떤 단어가 가장 많이 나오는가? 1) 테이블 생성
create table JOBS
( j_text varchar2(2000) );
select * from JOBS
\\
2) 텍스트 토큰화
select regexp_substr(j.j_text,'[^ ]+',1,v.num)
from jobs j , (select level as num
from dual
connect by level <= 30) v;
3) 위의 결과를 테이블로 생성
create table stev_word
as
select regexp_substr(j.j_text,'[^ ]+',1,v.num)as word
from jobs j , (select level as num
from dual
connect by level <= 30) v;
4) 위 테이블에 있는 콤마(,) 또는 점(.) , 더블퀘스쳔("), 물음표(?)와 같은 불용단어 잘라내어 출력하기.
select trim('"' from trim('?'from trim('.' from trim(',' from word))))
from stev_word;
5) 위의 결과를 stev_word2라는 테이블로 생성하시오.
create table stev_word2
as
select trim('"' from trim('?'from trim('.' from trim(',' from word)))) as word
from stev_word;
6) word 를 출력하고 word 별 건수를 출력하는데 word 별 건수가 높은것 부터 출력하시오 !
select word, count(*)
from stev_word2
group by word
order by 2 desc;
문제 3. 긍정단어 테이블과 부정단어 테이블을 생성하는데 테이블명을 positive_eng 와 positive_eng 로 생성하시오.