번호 안 붙은 과정은 시험에서 따로 해줄 필요는 없으나, 따로 파이썬으로 머신러닝 할 때는 해줘야하는 과정
#1. 데이터 로드
import pandas as pd
wbcd = pd.read_csv("c:\\data\\wisc_bc_data.csv")
#2. 데이터 확인
wbcd.shape #(569,32)
#wbcd.info()
#3. 결측치 확인
wbcd.isnull().sum()
#4. 정규화 작업
from sklearn.preprocessing import MinMaxScaler
wbcd2 = wbcd.iloc[ :, 2: ] #환자 번호(id) 와 정답 컬럼(diagnosis)는 제외
wbcd2.head()
scaler = MinMaxScaler()
scaler.fit(wbcd2) # 최대 최소 정규화 계산을 수행
wbcd2_scaled = scaler.transform(wbcd2)
wbcd2_scaled # 넘파이 배열 구조에 0~1 사이의 숫자로 담겨있음
#정답 데이터도 numpy 배열로 구성하기
y = wbcd['diagnosis'].to_numpy()
y
#훈랸과 테스트를 9:1 로 분리하기
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(wbcd2_scaled, y, test_size = 0.1, random_state = 1)
#print(x_train.shape) # 훈련 데이터 (512, 30)
#print(x_test.shape) # 테스트 데이터 (57, 30)
#print(y_train.shape) # 훈련 데이터 정답 (512,)
#print(y_test.shape) # 테스트 데이터 정답 (57,)
#5. 모델 훈련
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors = 5) #k 값을 5개로 해서 모델을 생성
model.fit(x_train, y_train)
#6. 모델 예측
result = model.predict(x_test)
result
#7. 모델 평가
sum(result == y_test) / len(y_test) * 100
#8. 모델 성능 개선
from sklearn.metrics import accuracy_score
x = []
y = []
for i in range(1, 27, 2) : #1 ~27 까지 2씩 증가시켜라
model = KNeighborsClassifier(n_neighbors = i)
model.fit(x_train, y_train)
result = model.predict(x_test)
accuracy = accuracy_score(y_test , result)
print( 'k가 ', i , '개일 때 정확도는 ', accuracy, '입니다.')
x.append(i)
y.append(accuracy)
#시각화
import matplotlib.pyplot as plt
plt.plot(x, y, label='accuracy', color = 'red')
plt.legend()
plt.show()
🌞빅분기 유형2_문제1. 다음 와인 데이터 (wine.csv)의 클래스를 분류하는 머신러닝 모델을 생성하고 테스트 데이터에 대한 정확도를 출력하기
knn 모델로 생성하고 훈련과 테스트를 9:1로 나누기
import pandas as pd
wine = pd.read_csv("c://data//wine2.csv")
wine.isnull().sum()
from sklearn.preprocessing import MinMaxScaler
wine2 = wine.iloc[ :, 2: ]
scaler = MinMaxScaler()
scaler.fit(wine2)
wine2_scaled = scaler.transform(wine2)
wine2_scaled
y = wine['Type'].to_numpy()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(wine2_scaled, y, test_size = 0.1, random_state = 1)
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors = 5)
model.fit(x_train, y_train)
result = model.predict(x_test)
sum(result == y_test) / len(y_test) * 100
from sklearn.metrics import accuracy_score
x = []
y = []
for i in range(1, 27,2) :
model = KNeighborsClassifier(n_neighbors = i)
model.fit(x_train, y_train)
result = model.predict(x_test)
accuracy =accuracy_score(y_test, result)
print( 'k가 ', i , '개일 때 정확도는 ', accuracy*100, '입니다.')
🌞파이썬으로 나이브 베이즈 분류 모델 만들기
※ 파이썬 나이브 베이즈 모델 3가지
1. BernoulliNB
이산형 데이터를 분류할 때 적합 (정수형 데이터)
2. GaussianNB
연속형 데이터를 분류할 때 적합 (실수형 데이터)
3. MultinorminalNB
이산형 데이터를 분류할 때 적합
"독버섯과 식용버섯 분류 모델 생성 "
[진행순서]
#1. 데이터 로드 #2. 결측치 확인 #3. 종속변수와 독립변수 분리 #4. 숫자로 변경 #5. 훈련 데이터와 테스트 데이터로 분리 #6. 모델 생성 #7. 모델 훈련 #8. 모델 예측 #9. 모델 평가 #10. 모델 개선
1. 데이터 로드
# 진행순서
#1. 데이터 로드
import pandas as pd
mush = pd.read_csv("c:\\data\\mushrooms.csv")
#mush.shape # (8124, 23)
#mush.info()
2. 결측치 확인
#2. 결측치 확인
mush.isnull().sum()
3. 종속변수와 독립변수 분리
#3. 종속변수와 독립변수 분리
x = mush.iloc[ : , 1: ] # 독립변수
y = mush.iloc[ : , 0 ] # 종속변수
#y
#5. 훈련 데이터와 테스트 데이터로 분리(훈련80%, 테스트20%)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_split(x2, y, test_size =0.2, random_stste=1)
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
6. 모델 생성
#6. 모델 생성
# ※ 파이썬 나이브 베이즈 모델 3가지
#1. BernoulliNB : 이산형 데이터를 분류할 때 적합 ( 정수형 데이터 )
#2. GaussianNB : 연속형 데이터를 분류할 때 적합 ( 실수형 데이터 )
#3. MultinorminalNB : 이산형 데이터를 분류할 때 적합
from sklearn.naive_bayes import BernoulliNB
model = BernoulliNB()
7. 모델 훈련
#7. 모델 훈련
model.fit( x_train, y_train)
8. 모델 예측
#8. 모델 예측
result = model.predict(x_test)
result
9. 모델 평가
#9. 모델 평가
sum( result == y_test ) / len(y_test) * 100 # 93.9
# 유방암, 독버섯의 경우는 이원 교차표의 거짓부정(FN) 값을 확인해야 합니다.
from sklearn.metrics import confusion_matrix
tn, fp, fn, tp = confusion_matrix( y_test, result).ravel()
#print( tn, fp, fn, tp ) # 815 5 94 711 , fn 이 94개 나 됩니다.
10. 모델 개선
#10. 모델 개선
from sklearn.naive_bayes import GaussianNB
model3 = GaussianNB(var_smoothing=0.001) # 라플라스값을 0.001 로 지정
11. 모델 훈련
# 11. 모델 훈련
model3.fit( x_train, y_train )
12. 모델예측
#12. 모델 예측
result3 = model3.predict(x_test)
13. 모델평가
#13. 모델 평가
sum( result3 == y_test ) / len(y_test) * 100 # 99.5
14. 모델 개선
#14. 모델 개선
from sklearn.naive_bayes import GaussianNB
model3 = GaussianNB(var_smoothing=0.001) # 라플라스값을 0.001 로 지정
# 16. for loop 문을 돌려서 정확도와 fn 값 확인
import numpy as np
for i in np.arange(0.001,0.01,0.001): # 0.001~0.01 까지 0.001씩 증가시켜라
from sklearn.naive_bayes import GaussianNB
model3 = GaussianNB(var_smoothing = i)
model3.fit(x_train, y_train)
result3 = model3.predict(x_test)
a = sum(result3 ==y_test)/len(y_test) *100
from sklearn.metrics import confusion_matrix
tn,fp,fn,tp = confusion_matrix(y_test,result3).ravel()
print(i,'일때 정확도는:', round(a,2), 'fn값:',fn)
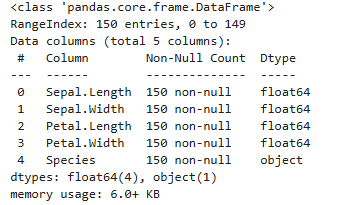
🌞 iris2.csv를 이용해서 iris 꽃의 품종을 분류하는 나이브 베이즈 모델을 생성하시오
#1. 데이터 로드
import pandas as pd
iris = pd.read_csv("c:\\data\\iris2.csv")
iris.shape
iris.info()
#2. 결측치 확인
iris.isnull().sum()
#3. 종속변수와 독립변수 분리
x = iris.iloc[ : , :4 ] # 독립변수
y = iris.iloc[ : , 4 ] # 종속변수
y
#4. 데이터 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x)
x_scaled = scaler.transform(x)
x_scaled
#5. 훈련 데이터와 테스트 데이터로 분리(훈련90%,테스트10%)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split( x, y, test_size=0.1, random_state=1)
print( x_train.shape ) # (135, 4)
print( x_test.shape ) # (15, 4)
print( y_train.shape ) # (135,)
print( y_test.shape ) # (15,)
#6. 모델 생성
# ※ 파이썬 나이브 베이즈 모델 3가지
#1. BernoulliNB : 이산형 데이터를 분류할 때 적합 ( 정수형 데이터 )
#2. GaussianNB : 연속형 데이터를 분류할 때 적합 ( 실수형 데이터 )
#3. MultinorminalNB : 이산형 데이터를 분류할 때 적합
from sklearn.naive_bayes import BernoulliNB
model = BernoulliNB()
#7. 모델 훈련
model.fit( x_train, y_train)
#8. 모델 예측
result = model.predict(x_test)
result
#9. 모델 평가
sum( result == y_test ) / len(y_test) * 100 # 26.666666666666668
#10. 모델 개선
from sklearn.naive_bayes import GaussianNB
model3 = GaussianNB(var_smoothing=0.001) # 라플라스값을 0.001 로 지정
#11. 모델 훈련
model3.fit( x_train, y_train )
#12. 모델 예측
result3 = model3.predict(x_test)
#13. 모델 평가
sum( result3 == y_test ) / len(y_test) * 100