import pandas as pd
emp = pd.read_csv('c:\\data\\emp.csv')
dept = pd.read_csv('c:\\data\\dept.csv')
문제2. 아래의 sql을 판다스로 구현하시오. (join)
1) SQL
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno
2) python
emp_dept = pd.merge(emp, dept, on ='deptno')
emp_dept
emp_dept = pd.merge(emp, dept, on ='deptno')
emp_dept[['ename','loc']]
문제3. 아래의 sql을 판다스로 구현하시오.
1) SQL
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno and e.job ='SALESMAN';
2) python
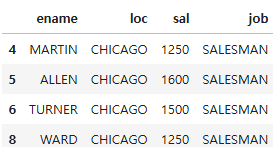
emp_dept = pd.merge(emp,dept, on ='deptno')
emp_dept[['ename','loc']][emp_dept.job =='SALESMAN']
문제4. 아래의 sql을 판다스로 구현하시오.
1) SQL
select e.ename, d.loc, e.sal
from emp e , dept d
where e.deptno = d.deptno and e.sal between 1000and 3000;
2) python
emp_dept = pd.merge(emp,dept, on ='deptno')
emp_dept[['ename','loc']][emp_dept['sal'].between(1000 ,3000)]
* 판다스의 논리 연산자 3가지
* 연산자의 종류 3가지
1. and
&
1. 산술 연산자
*, /, +, -
2. or
|
2. 비교 연산자
> , < , >=, <=, ==, !=
3. not
~
3. 논리 연산자
&, &&, ~
문제5. 아래의 sql을 판다스로 구현하시오.
1) SQL
select e.ename, d.loc, e.sal, e.job
from emp e, dept d
where d.deptno =d.deptno
and e.sal between 1000 and 3000 and e.job ='SALESMAN';
2) python
emp_dept = pd.merge(emp,dept, on ='deptno')
emp_dept[['ename','loc','sal','job']][(emp_dept['sal'].between(1000 ,3000)) & (emp_dept['job']== 'SALESMAN')]
how = 'inner' 는 오라클의 equi join 과 똑같습니다. how = 'right' 는 dept 테이블 쪽의 데이터가 모두 나오게 해라 ! how = 'left' 는 emp 테이블 쪽의 데이터가 모두 나오게 해라 ! how = 'outer' 는 오라클의 full outer 조인과 똑같습니다.
문제1. 아래의 sql을 판다스로 구현하시오.
1) SQL
select e.ename, d.loc
from emp e, dept d
where e.deptno(+) =d.deptno:
2) python
x = pd.merge(emp,dept, on='deptno' , how= 'right') # dept 테이블 다 나오게 해라
x[['ename','loc']]
문제2. 아래의 sql을 판다스로 구현하시오.
1) SQL
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno(+)
2) python
x=pd.merge(emp,dept, on='deptno', how = 'left')
x[['ename','loc']]
문제 3. 아래의 sql을 판다스로 구현하시오.
1) SQL
select d.loc, sum(e.sal)
from emp e, dept d
where e.deptno = d.deptno
group by d.loc;
2) python
x = pd.merge(emp, dept, on='deptno', how = 'inner')
x.groupby('loc')['sal'].sum().reset_index()
문제 4. 아래의 sql을 판다스로 구현하시오.
1)SQL
select d.loc, sum(e.sal)
from emp e, dept d
where e.deptno(+) = d.deptno
group by d.loc;
2) python
x = pd.merge(emp, dept, on='deptno', how = 'right')
x.groupby('loc')['sal'].sum().reset_index()
문제 5. 위의 결과를 막대그래프로 시각화 하기
x = pd.merge(emp, dept, on='deptno', how = 'right')
result= x.groupby('loc')['sal'].sum().reset_index()
result.plot(kind ='bar', x='loc', y='sal', legend=False,color = ['skyblue','pink','gray'])
문제6. 아래의 sql 을 판다스로 구현하기
1) SQL
select 사원.ename, 관리자.ename
from emp 사원, emp 관리자
where 사원.mgr= 관리자.mgr;
2) python
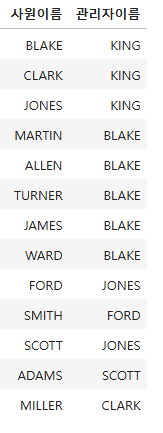
import pandas as pd
x = pd.merge(emp,emp,left_on='mgr',right_on ='empno')
x2=x[['ename_x','ename_y']]
x2.columns=['사원이름','관리자이름']
x2
문제7. 아래의 sql 을 판다스로 구현하기
1) SQL
select 사원.ename, 사원.sal, 관리자.ename, 관리자.sal
from emp 사원, emp 관리자
where 사원.mgr =관리자.empno
and 사원.sal > 관리자.sal;
2) python
import pandas as pd
x = pd.merge(emp,emp,left_on='mgr',right_on ='empno')
x2=x[['ename_x','sal_x','ename_y','sal_y']][x['sal_x']>x['sal_y']]
x2.columns=['사원이름','사원월급','관리자이름','관리자월급']
x2
■ 조인 + 레포팅 결과 출력(with 판다스)
예제
1) SQL
select e.job, sum(decode(d.loc,'NEW YORK', e.sal,null) as'NEW YORK',
sum(decode(d.loc,'DALLAS', e.sal,null) as'DALLAS',
sum(decode(d.loc,'CHICAGO', e.sal,null) as'CHICAGO'
from emp e, dept d
where e.deptno = d.deptno
group bt e.job;
2) python
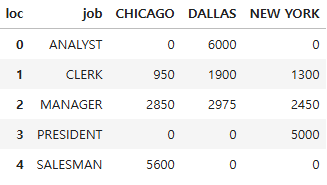
x = pd.merge(emp, dept, on='deptno')
x.pivot_table(index='job', columns='loc', values='sal', aggfunc='sum', fill_value=0).reset_index()
설명: index 에는 행의 이름에 해당하는 컬럼명을 쓰면 되고 columns에는 결과의 컬럼명이 될 컬럼명을 쓰면됨
문제1.아래의 sql 을 판다스로 구현하기
1) SQL
select d.loc, sum(decode(e.job = 'ANALYST' ,e.sal=0)) as 'ANALYST',
sum(decode(e.job = 'CLERK' ,e.sal=0)) as 'CLERK',
sum(decode(e.job = 'MANAGER' ,e.sal=0)) as 'MANAGER',
sum(decode(e.job = 'SALESMAN' ,e.sal=0)) as 'SALESMAN',
sum(decode(e.job = 'PRESIDENT' ,e.sal=0)) as 'PRESIDENT')
from emp e, dept d
where e.deptno = d.deptno
group by d.loc;
2) python
x = pd.merge(emp, dept, on='deptno')
x2= x.pivot_table(index='loc', columns='job', values='sal', aggfunc='sum')
x3= x2.fillna(0).astype(int)
x3
문제2. 아래의 sql 을 판다스로 구현하기
1) SQL
select e.job, sum(decode(d.dname,'ACCOUNTING',e.sal,0)) as 'ACCOUNTING',
sum(decode(d.dname,'SALES',e.sal,0)) as 'SALES',
sum(decode(d.dname,'RESEARCH',e.sal,0)) as 'RESEARCH',
sum(decode(d.dname,'OPERATIONS',e.sal,0)) as 'OPERATIONS'
from emp e, dept d
where e.deptno = d.deptno
group by d.job;
2) python
import pandas as pd
# 데이터 병합
x = pd.merge(emp, dept, on='deptno', how='outer')
x2= x.fillna(0)
# 피벗 테이블 생성 (모든 부서 포함)
x3 = x2.pivot_table(index='job', columns='dname', values='sal', aggfunc='sum', fill_value=0)
# 결과를 정수형으로 변환
x4 = x3.astype(int)
# 결과 출력
x4
문제 3. 아래의 sql 을 판다스로 구현하기
1) SQL
select to_char(e.hiredate,'RRRR'),
sum(decode(d.loc,'NEWYORK', e.sal,0) as'NEWYORK',
sum(decode(d.loc,'DALLAS', e.sal,0) as'DALLAS',
sum(decode(d.loc,'CHICAGO', e.sal,0) as'CHICAGO'
from emp e,dept d
where e.deptno = d.deptno
group by to_char(hiredate,'RRRR');
2)pandas
import pandas as pd
# 데이터 병합
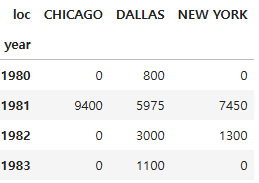
x = pd.merge(emp, dept, on='deptno', how='inner')
x['hiredate'] = pd.to_datetime(x['hiredate'])
# 연도 추출
x['year'] = x['hiredate'].dt.year
# 피벗 테이블 생성
x2 = x.pivot_table(index='year', columns='loc', values='sal', aggfunc='sum', fill_value=0)
# 결과를 정수형으로 변환
x3 = x2.astype(int)
# 결과 출력
x3
■ 판다스에서의 집합 연산지 사용
SQL
vs
pandas
1. union all
pd.concat
2. union
pd.concat + drop_duplicates()
3. intersect
아래의코드
4. minus
아래의코드
1) SQL
select ename, sal, deptno
from emp
where deptno in (10,20)
union all
select ename, sal, deptno
ffrom emp
where deptno =10;
2) python
x1 = emp[['ename','sal','deptno']][emp['deptno'].isin([10,20])]
x2 = emp[['ename','sal','deptno']][emp['deptno']== 10 ]
pd.concat([x1,x2], axis = 1)
-> axis =0 은 위아래로 연결(기본값) / axis =1 은 양옆으로 연결
문제1. 아래의 sql을 판다스로 구현하시오. (union all)
1) SQL
select job, sum(sal)
from emp
group bt job
union all
select null as job, sum(sal)
from emp;
2) python
x1 = emp.groupby('job')['sal'].sum().reset_index()
x2 = pd.DataFrame({'job':[None], 'sal' : [emp['sal'].sum()] })
pd.concat([x1, x2],axis=0)
문제2. 아래의 sql을 판다스로 구현하시오. (union) .drop_duplicates() # 중복제거
1)SQL
select ename, sal, deptno
from emp
where deptno in(10,20)
union
select ename,sal,deptno
from emp
where deptno =10;
2) python
x1 = emp[['ename','sal','deptno']][emp['deptno'].isin([10,20])]
x2 = emp[['ename','sal','deptno']][emp['deptno']== 10 ]
pd.concat([x1,x2], axis = 0).drop_duplicates() # 중복제거
문제3. 아래의 sql을 판다스로 구현하시오. (minus)
1) SQL
select ename, sal, deptno
from emp
where deptno in (10,20)
minus
select ename,sal,deptno
from emp
where deptno = 10;
2) python
x1 = emp[['ename','sal','deptno']][emp['deptno'].isin([10,20])]
x2 = emp[['ename','sal','deptno']][emp['deptno']== 10 ]
x1[:][x1.ename.isin(x2.ename)==False]