1) SQL
select sum(sal)
from emp
where deptno = 20;
2) python
import pandas as pd
emp = pd.read_csv("c://data500//emp.csv")
#emp
result = emp['sal'][emp['deptno'] == 20]
print(result.sum()) ### 결과 : 10875
시리즈 = 컬럼
문법 : emp[컬럼명 리스트][검색조건]
문제2.
1)SQL
select deptno,sum(sal)
from emp
group by deptno;
2)python
emp.groupby('deptno')['sal'].sum().reset_index()
result = emp.groupby('deptno')['sal'].sum().reset_index()
result.columns=['부서번호','토탈월급']
result
-> 판다스에서 groupby 함수를 쓸 때는 꼭! 뒤에 reset_index() 를 써줘야 데이터 프레임으로 출력됨
1) SQL
select job as 직업, to_char(sum(sal),'999,999') as 토탈월급
from emp
group by job;
2) python
result = emp.groupby('job')['sal'].sum().reset_index()
result.columns=['직업','토탈월급']
result['토탈월급'] = result['토탈월급'].apply(lambda x: f'{x:,}')
result
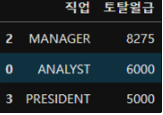
문제 5. 아래의 sql 을 판다스로 구현하기
1) SQL
select job as 직업, sum(sal) as 토탈월급
from emp
where job!='SALSEMAN'
group by job
having sum(sal) >= 5000
order by 토탈월급 desc;
2) python
result = emp[:][emp.job != 'SALESMAN']
result1 = result.groupby('job')['sal'].sum().reset_index()
result1.columns=['직업','토탈월급']
result2 = result1[:][result1['토탈월급'] >= 5000]
result2.sort_values(by='토탈월급',ascending=False)
문제 6. 아래의 sql 을 판다스로 구현하기
1) SQL
select avg(nvl(comm,0))
from emp;
2) python
#힌트 : fillna 함수 사용
emp['comm'].fillna(0).mean()
문제7. (시험 문제 유형) 위의 결과를 출력할 때 소수점 2번째 자리까지 반올림해서 출력하기
result = emp['comm'].fillna(0).mean()
print(round(result,2))
문제 8. 반올림이 아니라 그냥 소수점 2번째 자리까지 출력해서 제출하기
result = emp['comm'].fillna(0).mean()
result2 = "{:.2f}".format(result)
print(result2)
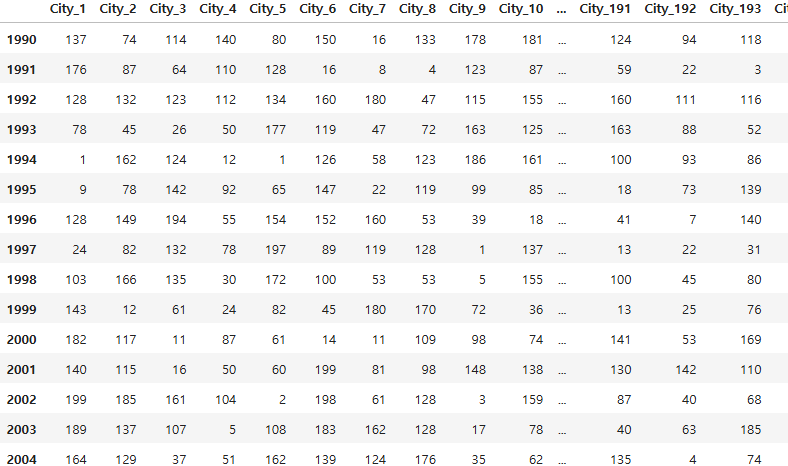
문제 9. [빅분제 실기3회_작업형 1번 문제] 연도별(1990~2007: 18개 년도의 행) 약 200개의 도시(컬럼)의 데이터 중 2003년도 전체 도시의 평균온도보다 높은 도시 수를 출력하여 제출하기
1) SQL
select avg(sal)
from emp
where to_char(hiredate,'RRRR') = '1981';
2) python
df_1981 = emp['sal'][emp.hiredate.dt.year == 1981]
print(df_1981.mean())
문제 4. 아래의 sql을 판다스로 구현하기
1) SQL
select to_char(hiredate,'RRRR'), sum(sal)
from emp
group by to_char(hiredate,'RRRR');
2) python
result = emp.groupby(emp.hiredate.dt.year)['sal'].sum().reset_index()
result.columns = ['입사일', '토탈월급']
result
■ 빅분기 6회 시험_작업형1_문제1. 날짜형 데이터 다루기
날짜 - 날짜 = 숫자
날짜 - 숫자 - 날짜
날짜 + 숫자 = 날짜
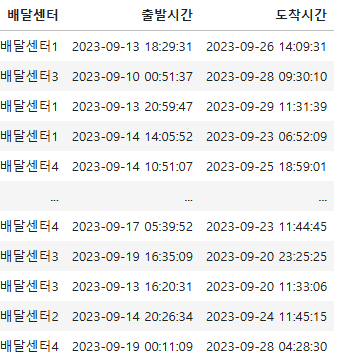
[빅분기 6회 시험_작업형1] 주어진 데이터는 각 배달 센터의 출발/도착 시간 데이터. 출발 시간과 도착 시간의 차이의 평균값을 구하기
import pandas as pd
df = pd.read_csv("c://data500//delivery_data.csv")
df
1) SQL
select 배달센터,avg(소요시간)
from df
group by 배달센터;
2) python
result = df.groupby(df.배달센터)['소요시간'].mean().reset_index()
#result.columns = ['배달센터','소요시간']
result
[빅분기 6회 시험_작업형1] 주어진 데이터는 각 배달 센터의 출발/도착 시간 데이터. 출발 시간과 도착 시간의 차이의 평균값을 구하고, 그 평균 값을 분단위로 변환한 후 가장 오래걸린 배달 센터의 평균 소요 시간을 출력해서 제출하기
문제1. 아래의 SQL을 판다스로 구현하기 문법: emp.groupby(’컬럼1’)[’숫자형 컬럼’].count().reset_index()
1) SQL
select job, count(*)
from emp
group by job;
2) python
import pandas as pd
emp = pd.read_csv("c://data//emp.csv")
emp.groupby('job')['empno'].count().reset_index()
문제2. 아래의 sql 을 판다스로 구현하기
1) SQL
select job as 직업, count(*) as 인원수
from emp
group by job
having count(*) > 3;
2) python
result = emp.groupby('job')['empno'].count().reset_index()
result.columns = ['직업','인원수']
result[:][result.인원수 >=3]
■ 컬럼 2개로 group by 하기
예제1. 아래의 sql을 판다스로 구현하기
1) SQL
select deptno, job, sum(sal)
from emp
group by deptno, job
order by deptno,job;
2) python
emp.groupby(['deptno','job'])['sal'].sum().reset_index()
문제1. 아래의 sql을 판다스로 구현하기
1) SQL
select to_char(hiredate,'RRRR'),deptno, sum(sal)
from emp
group by to_char(hiredate.'RRRR'), deptno
order by to_char(hiredate,'RRRR'), deptno;
2) python
import pandas as pd
emp = pd.read_csv("c://data500//emp.csv")
emp['hiredate'] = pd.to_datetime(emp.hiredate)
emp['hire_year'] = emp.hiredate.dt.year
result = emp.groupby(['hire_year','deptno'])['sal'].sum().reset_index()
result.columns = ['입사년도','부서번호','토탈월급']
result.sort_values(by=['입사년도','부서번호'],ascending=True)
문제2. 빅분기 실기 4회_작업형1_문제3 유형: employee_data.csv 파일에서 date_hired 가 2020년 1월 이후이고 country가 ‘United States’인 직원수를 출력하기
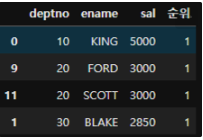
1) SQL
select ename, sal, rank() over (order by sal desc) as 순위
from emp;
2) python
import pandas as pd
emp = pd.read_csv("c:\\data500\\emp.csv")
emp['순위'] = emp['sal'].rank(ascending=False).astype(int)
emp[['ename','sal','순위']].sort_values(by='순위',ascending=True)
문제1. 아래의 sql을 판다스로 구현하기
1) SQL
select ename, sal, job , rank() over(order by sal desc) 순위
from emp
where job = 'SALESMAN';
2) python
result = emp[:][emp.job=='SALESMAN']
result['순위'] = result['sal'].rank(ascending=False).astype(int)
result[['ename','sal','순위']].sort_values(by='순위')
문제2. 아래의 sql을 판다스로 구현하기
1) SQL
select ename, sal, rank() over (partition by deptno
order by sal desc ) 순위
from emp;
2) python
import pandas as pd
emp = pd.read_csv("c:\\data500\\emp.csv")
emp['순위'] = emp.groupby('deptno')['sal'].rank(ascending = False).astype(int)
emp[[ 'deptno','ename', 'sal','순위' ]].sort_values(by = ['deptno','순위'])
문제4. 사이킷런에 내장된 타이타닉 데이터 프레임을 가져와서 아래의 SQL 처럼 판다스로 구현하기
1) SQL
select name, fare, pclass, rank() over ( partition by pclass
order by fare desc ) 순위
from tat;
2) python
from sklearn.datasets import fetch_openml
titanic = fetch_openml("titanic", version= 1, as_frame=True)
tat = titanic.frame
tat.head()
tat['순위'] = tat.groupby('pclass')['fare'].rank(ascending = False)
tat['순위'] = tat['순위'].fillna(0).astype(int)
result = tat[['name','fare','pclass','순위']].sort_values(by = ['pclass','순위'])
result
■ 등급을 나누는 함수 (qcut 함수)
= 오라클의 ntile과 같은 함수
1) SQL
select ename, sal, ntile(4) over (order by desc) as 등급
from emp;
2) python
emp['순위'] = emp['sal'].rank(method='dense',ascending=False).astype(int)
emp['sal_grade'] = pd.qcut(emp.순위, q=4, labels = range(1,5) )
emp[['ename','sal','sal_grade']].sort_values(by='sal_grade',ascending=True)
[빅분기 4회_작업형1_문제1] employee_salary_data.csv 에서 salary 컬럼의 3사분위수와 1사분위수의 차이를 절대값으로 구하고 소수점을 버린 후 정수로 출력하기
import pandas as pd
df = pd.read_csv("c://data500//employee_salary_data.csv")
df
# 1사분위수와 3사분위수 계산
q1 = df['salary'].quantile(0.25)
q3 = df['salary'].quantile(0.75)
# 3 사분위수와 1사분위수의 차이를 계산 (절대값)
result = abs(q3 - q1)
int(result) ###44532
import pandas as pd
emp = pd.read_csv("c:\\data500\\emp.csv")
q1 = emp['sal'].quantile(0.25)
q3 = emp['sal'].quantile(0.75)
result = abs(q3 - q1)
int(result) ###1693
■ 오라클의 lag 함수와 lead 함수를 판다스로 구현하기
1) SQL
select ename, sal , lag(sal,1) over (order by sal asc) as lag_sal,
lead(sal,1) over (order by sal asc) as lead_sal
from emp;
2) python
emp['sal_lag'] = emp['sal'].shift(1).fillna(0).astype(int) #월급을 아래로 한 칸 이동
emp[['ename','sal','sal_lag']]
emp['sal_lead'] = emp['sal'].shift(-1).fillna(0).astype(int)
emp[['ename','sal','sal_lead']]
문제1. (시험유형) 아래의 sql을 판다스로 구현하기
1) SQL
select avg(sal - lead_sal)
from (
select ename, sal , lag(sal,1) over (order by sal asc) as lag_sal,
lead(sal,1) over (order by sal asc) as lead_sal
from emp;
);
2) python
emp['sal_diff'] = emp['sal'] - emp['sal_lead']
#emp[['ename','sal_diff']]
print(round(emp['sal_diff'].mean(),2)) ###357.14
문제2. 아래의 sql을 판다스로 구현하기
1) SQL
select ename, hiredate - lag(hiredate,1) over (order by hiredate asc)
from emp;
2) python
import pandas as pd
emp = pd.read_csv("c://data500//emp.csv")
emp['hiredate'] = pd.to_datetime(emp['hiredate'])
emp = emp.sort_values(by='hiredate')
emp['hiredate_lag'] = emp['hiredate'].shift(1)
emp['hiredate_diff'] = emp['hiredate_lag'] - emp['hiredate']
emp[['ename','hiredate','hiredate_lag','hiredate_diff']]
■ 오라클의 pivot 함수를 판다스로 구현하기 (현업에서 많이 사용하는 예제)
1) SQL
select *
from (select deptno,sal from emp)
pivot( sum(sal) for deptno in (10,20,30) );
2) python
result = emp.pivot_table(columns='deptno',values='sal',aggfunc='sum')
result.reset_index(drop=True)
문제1. 아래의 sql을 판다스로 구현하기
1) SQL
select *
from (select job,sal form emp)
pivot(sum(sal) for job in ('SALESMAN' as "SALESMAN",
'ANALYST' as ....) );
2) python
result = emp.pivot_table(columns= 'job',values='sal',aggfunc='sum')
result.reset_index(drop=True)
문제2. 아래의 sql 을 판다스로 구현하기
1) SQL
select job, sum( decode( deptno, 10, sal, 0) ) as "10",
sum( decode( deptno, 20, sal, 0) ) as "20",
sum( decode( deptno, 30, sal, 0) ) as "30"
from emp
group by job;
2) python
result = emp.pivot_table(columns='deptno',index='job',values='sal',aggfunc='sum')
result.fillna(0,inplace=True) #결측치를 0으로 채우기
result2 = result.astype(int)
result2
sql 다음으로 판다스를 많이 사용하는 이유 1. sql 보다 코드가 간단함 2. 데이터 시각화가 용이함