
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- if문 작성법
- Sum
- loop 문
- sqld
- Dense_Rank
- 그래프 생성 문법
- 막대그래프
- sql
- 불순도제거
- 빅데이터
- 데이터분석가
- 여러 데이터 검색
- %in%
- count
- 순위출력
- 상관관계
- difftime
- 회귀분석 알고리즘
- 정보획득량
- merge
- 단순회귀 분석
- 회귀분석
- 그래프시각화
- 총과 카드만들기
- 데이터분석
- 빅데이터분석
- Intersect
- 팀스파르타
- 히스토그램 그리기
- max
- Today
- Total
ch0nny_log
[빅데이터분석] Python_53. 판다스 머신러닝3 (로지스트 회귀, SVC,다중회귀분석 모델 ) 본문
[빅데이터분석] Python_53. 판다스 머신러닝3 (로지스트 회귀, SVC,다중회귀분석 모델 )
chonny 2024. 9. 5. 16:21✨ 유형 2번 문제를 풀기위해 반드시 암기하고 가야할 코드
| 1. 랜덤 포레스트 | from sklearn.ensemble import RandomForestClassifier r_model = RandomForestClassifier(n_estimators=100) |
| 2. 서포트 백터 머신 |
from sklearn import svm svm_model = svm.SVC(C=100, gamma=3) |
| 3. 신경망 | from sklearn import MLPClassifier model = MLPClassifier(hidden_layer_sizes=(100, 200)) |
1. 데이터 생성
from sklearn.datasets import make_blobs
x, y = make_blobs( centers =2, random_state =8) # centers 로 하면 클래스가 2개로 생성됨 / x(독립변수), y(종속변수)
x

# 2. 모델 생성
!pip install mglearnimport mglearn
import matplotlib.pyplot as plt
# 시각화
mglearn.discrete_scatter(x[ : , 0 ], x[ : , 1], y )
plt.xlabel('feature0')
plt.ylabel('feature1')
# 모델 불러오기
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model

# 3. 모델 훈련
model.fit(x,y)
# 4. 분류 시각화
mglearn.plots.plot_2d_separator(model, x) # 결정경계선 출력
mglearn.discrete_scatter(x[ : , 0 ], x[ : , 1], y ) # 산포도 출력
plt.xlabel('feature0')
plt.ylabel('feature1')
# 5. 모델 평가
model.score(x,y) #100%
-> 위의 그림처럼 위의 데이터는 직선으로 분류가 가능한 데이터임
✨ 심화 문제1. 직선으로 분류가 힘든 데이터의 경우
# 1. 데이터 생성
from sklearn.datasets import make_blobs
x, y = make_blobs( centers =4, random_state =8) # centers 로 하면 클래스가 2개로 생성됨 / x(독립변수), y(종속변수)
y= y%2
# 2. 모델 생성
# !pip install mglearn
import mglearn
import matplotlib.pyplot as plt
mglearn.discrete_scatter(x[ : , 0 ], x[ : , 1], y )
plt.xlabel('feature0')
plt.ylabel('feature1')
-> 곡선으로 나눠야됨
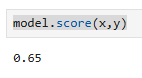
-> 정확도도 0.65로 떨어짐 (성능개선을 위해 비선형 분류를 할 수 있도록 로지스트 회귀전용 하이퍼 파라미터를 지정해 줘야됨 )
예) model = LogisticRegression(solver ='liblinear')
| ※ solver 옵션 3가지 |
| newton-cg |
| lbfgs |
| liblinear |
-> 3가지 다 분류 못해서 20년 후 러시아 수학자가 만든 서포트 벡터머신을 사용해서 분류함
# 서포트 백터 머신 모델 생성
from sklearn.svm import SVC
model = SVC()
model
model.fit(x,y)

mglearn.plots.plot_2d_separator(model, x) # 결정경계선 출력
mglearn.discrete_scatter(x[ : , 0 ], x[ : , 1], y ) # 산포도 출력
plt.xlabel('feature0')
plt.ylabel('feature1')
-> 선이 2개 있는게 아니라 곡선임
model.score(x,y)
-> 정확도 100%
✨ 심화 문제 2. 분류가 힘든 데이터의 경우 2
# 1. 데이터 생성
from sklearn.datasets import make_blobs
x, y = make_blobs( centers =6, random_state =8) # centers 로 하면 클래스가 2개로 생성됨 / x(독립변수), y(종속변수)
y= y%2
# 2. 모델 생성
# !pip install mglearn
import mglearn
import matplotlib.pyplot as plt
mglearn.discrete_scatter(x[ : , 0 ], x[ : , 1], y )
plt.xlabel('feature0')
plt.ylabel('feature1')
☆ 서포트 벡터머신 활용 시 제대로 분류가 되지 않음


-> 정확도도 84%로 떨어짐
-> 서포트 벡신 머신 모델의 정확도를 올리기 위해 하이퍼 파라미터를 조정해야됨 (C, gamma)
1) C 값만 200으로 조정했을 시 (90%)
from sklearn.svm import SVC
model = SVC(C=200) #C의 기본값은 1임
model
model.fit(x,y)
#시각화
mglearn.plots.plot_2d_separator(model, x) # 결정경계선 출력
mglearn.discrete_scatter(x[ : , 0 ], x[ : , 1], y ) # 산포도 출력
plt.xlabel('feature0')
plt.ylabel('feature1')

2) C=200, gamma =3 으로 조정 (100%)
from sklearn.svm import SVC
model = SVC(C=200, gamma =3)
model
model.fit(x,y)
#시각화
mglearn.plots.plot_2d_separator(model, x) # 결정경계선 출력
mglearn.discrete_scatter(x[ : , 0 ], x[ : , 1], y ) # 산포도 출력
plt.xlabel('feature0')
plt.ylabel('feature1')

-> 정확도 100%
✨ iris2.csv의 데이터를 서포트 백터 머신으로 분류하시오
#1. 데이터 불러오기
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_df = pd.DataFrame( data=iris.data, columns=iris.feature_names)
iris_df['Species'] = pd.Series(iris.target)
print( iris_df.head() )
#2. 결측치 확인
iris_df.isnull().sum()
#3. 독립변수와 종속변수 분리
x = iris_df.iloc[ :,0:4] # 독립변수
y = iris_df.iloc[ :,4] # 독립변수
#4. 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x)
x2 = scaler.transform(x) # 계산한 내용으로 데이터 정규화
print(x2)
#5. 훈련과 테스트 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x2,y,test_size=0.1, random_state =1)
print(x_train.shape) #(135, 4)
print(x_test.shape) #(15, 4)
print(y_train.shape) #(135,)
print(y_test.shape) #(15,)
#6. 모델 생성
from sklearn import svm
svm_model =svm.SVC()
#7. 모델 훈련
svm_model.fit(x_train, y_train)
#8. 모델 예측
result = svm_model.predict(x_test)
result
#9. 모델 평가
sum(result == y_test) /len(y_test)
✨ 파이썬으로 다중 회귀 분석 모델 생성하기
-> 미국 국민 의료비를 예측하는 회귀 모델 생성
#1. 데이터 로드
import pandas as pd
ins = pd.read_csv("c:\\data\\insurance.csv")
ins.head()
#2. 결측치 확인
ins.isnull().sum()
#3. 상관관계 분석
import seaborn as sns
ins2 = ins.loc[ : ,['age','bmi','children','expenses'] ]
sns.heatmap(ins2.corr(), annot=True, cmap='Blues', linewidths=0.2)
#4. 다중회귀모델 생성
import statsmodels.formula.api as smf
model = smf.ols( formula = 'expenses ~ age+sex+bmi+children+smoker+region',
data = ins)
#5. 모델 훈련
result = model.fit()
#6. 분석결과 해석
# 기울기 확인
result.params
#R 처럼 분석된 결과를 보고 싶다면 ?
result.summary()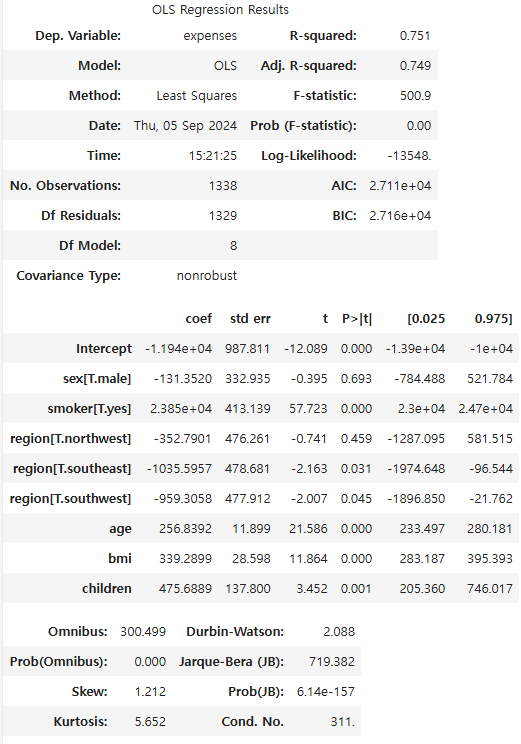
-> 결정계수 0.75
문제1. 미국 의료비를 예측하는 다중회귀모델의 결정계수를 올리기 위해서 파생컬럼을 추가하시오.
- 흡연을 하면서 비만이 사람은 1로 하고 아니면 0으로 하는 파생컬럼
def func2(x,y):
if x >= 30 and y=='yes':
return 1
else:
return 0
ins['bmi30_smoker'] = list(map(func2, ins.bmi , ins.smoker))
ins.head()
#4. 다중회귀모델 생성
import statsmodels.formula.api as smf
model2 = smf.ols( formula = 'expenses ~ age+sex+bmi+children+smoker+region+bmi30_smoker',
data = ins)
#5. 모델 훈련
result2 = model2.fit()
#6. 분석결과 해석
# 기울기 확인
result.params
#R 처럼 분석된 결과를 보고 싶다면 ?
result2.summary()
■ 빅분기 실기 시험용 다중회귀 분석
#1. 데이터 로드
import pandas as pd
ins = pd.read_csv("c:\\data\\insurance.csv")
ins.head()
#2. 결측치 확인
ins.isnull().sum()
#3. 독립변수와 종속변수로 나누기
y = ins['expenses'] # 종속변수
x1 = ins[['age', 'bmi', 'children']] # 숫자형 데이터
x2 = ins[['sex', 'smoker', 'region']] # 문자형 데이터
x2_dummy = pd.get_dummies(x2) # 문자형 데이터를 숫자형 변환
x = pd.concat( [x1, x2_dummy], axis=1 ) # axis=1 은 양옆으로 붙이겠다.
x.head()
#4. 훈련과 테스트로 분리(9대1)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split( x, y, test_size=0.1, random_state=1)
print( x_train.shape) # (1204, 11)
print( x_test.shape) # (134, 11)
print( y_train.shape) # (1204,)
print( y_test.shape) # (134,)#5. 모델 생성
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit( x_train, y_train )
#결정계수 확인
model.score(x_train, y_train)
# 6. 모델 예측
result = model.predict(x_test)
result
#7. 모델 평가
from scipy.stats import pearsonr
corr, _ = pearsonr( y_test, result)
print( corr ) # 0.853
+ 개선
#1. 데이터 로드
import pandas as pd
ins = pd.read_csv("c:\\data\\insurance.csv")
ins.head()
#2. 결측치 확인
ins.isnull().sum()
# 파생변수 추가
def func2(x,y):
if x >= 30 and y == 'yes':
return 1
else:
return 0
def func1(x,y):
if x >= 19 and y <= 25:
return 1
else:
return 0
ins['age_1925'] = list(map(func1, ins.age, ins.age))
ins['bmi30_smoker'] = list(map(func2, ins.bmi, ins.smoker))
#3. 독립변수와 종속변수로 나누기
y = ins['expenses'] # 종속변수
x1 = ins[['age','bmi','children','bmi30_smoker','age_1925']] # 숫자형 데이터
x2 = ins[['smoker','region']] # 문자형 데이터
x2_dummy = pd.get_dummies(x2) # 문자형 데이터를 숫자형 변환
x2_dummy
x = pd.concat( [x1, x2_dummy],axis = 1) # axis = 1 은 양옆으로 붙이겠다.
x.head()
#4. 훈련과 테스트로 분리(9 대 1)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.1, random_state = 1)
x_train.shape #(1204, 11)
y_train.shape #(1204,)
x_test.shape #(134, 11)
y_test.shape #(134,)
#5. 모델 생성
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit( x_train, y_train )
#결정계수 확인
model.score(x_train, y_train)
#6. 모델 예측
result = model.predict(x_test)
result
#7. 모델 평가
from scipy.stats import pearsonr
corr, _ = pearsonr( y_test, result)
print(corr)
'빅데이터 분석(with 아이티윌) > python' 카테고리의 다른 글
| [빅데이터분석] Python_55. 판다스 머신러닝5.(랜덤 포레스트 , 수치예측) (3) | 2024.09.10 |
|---|---|
| [빅데이터분석] Python_54. 판다스 머신러닝4. (단순회귀, 신경망 수치예측) (1) | 2024.09.06 |
| [빅데이터분석] Python_52. 판다스 머신러닝2 (의사결정트리, 랜덤 포레스트) (1) | 2024.09.05 |
| [빅데이터분석] Python_51. 판다스 머신러닝1 (나이브베이즈 분류모델) (4) | 2024.09.05 |
| [빅데이터분석] Python_50. 판다스 기본문법3 (1 유형) - 서브쿼리 (0) | 2024.09.03 |


