-> 정제가 필요한 결측값은 주로 0으로 많이 치환함 예제7. tatanic2.sv에 결측치가 가장 많은 컬럼이 뭔지 출력하시오
import pandas as pd
tat = pd.read_csv( 'c:\\data\\tatanic2.csv' )
tat.isnull().sum().idxmax()
예제 8. 이름의 첫번째 철자가 A 인 사원들의 이름과 월급을 출력하시오
1) SQL
select ename, sal
from emp
where substr(ename, 1, 1 )='A';
2) python
emp[['ename', 'sal']] [ emp['ename'].apply(lambda x : x[0]=='A' ) ]
예제 9. 아래의 SQL을 판다스로 구현하시오 !
1) SQL
select ename, sal
from emp
where ename like '_M%';
2) python
emp[['ename', 'sal']] [ emp['ename'].apply(lambda x : x[1]=='M' ) ]
예제 10. 아래의 SQL을 판다스로 구현하시오
1) SQL
select ename, sal
from emp
where ename like '%T';
2) python
emp[['ename', 'sal']] [ emp['ename'].apply(lambda x : x[-1]=='T' ) ]
예제 11. 아래의 SQL을 판다스로 구현하시오
1) SQL
select ename, sal
from emp
where ename like '%T';
2) python
tat[['survived','class']][tat['class'].apply(lambda x : x[-1] == 't') ]
○ 1 유형_3. 데이터 정렬하기
예제1. 이름, 월급을 출력하는데 월급이 높은 사원부터 출력하시오.
1) SQL
select ename, sal
from emp
order by sal desc;
2) python
emp[['ename','sal']].sort_values(by='sal', ascending = False)
문제 1. 아래의 SQL을 pandas로 구현하시오.
1)SQL
select ename, sal, job
from emp
where job ='SALESMAN'
order by sal desc;
2) python
result= emp[['ename','sal','job']][emp['job'] =='SALESMAN']
result.sort_values(by='sal', ascending = False)
문제 2. 타이타닉 데이터에서 fare가 높은 승객부터 모든컬럼을 출력하시오.
tat[:].sort_values(by='fare', ascending = False)
○ 1 유형_4. 날짜형 데이터
기본적으로 엑셀이나 csv 파일을 판다스 데이터 프레임으로 구성하게 되면 날짜 형식이 object 로 구성됩니다.
그런데 날짜를 검색할때는 데이터가 문자형이 아니라 날짜형이어야 정확하게 데이터를 검색할 수 있습니다.
예제1. emp 테이블 프레임의 구조를 확인합니다.
emp.info()
예제2. emp 데이터 프레임의 hiredate를 날짜형으로 변환하여 구성하시오.
import pandas as pd
emp['hiredate'] = pd.to_datetime(emp['hiredate'])
emp.info()
문제1. 아래의 sql을 판다스로 구현하시오.
1) SQL
select ename, hiredate
from emp
where hiredate ='81-11-17';
2) python
emp[['ename','hiredate']][emp['hiredate'] =='1981-11-17']
문제2. 아래의 sql을 판다스로 구현하시오.
1) SQL
select ename, hiredate
from emp
where hiredate between '81-01-01' and '81-07-20';
2) python
emp[['ename','hiredate']][emp['hiredate'].between('1981-01-01','1981-07-20')]
문제3.아래의 sql을 판다스로 구현하시오.
1) SQL
select ename, job, hiredate
from emp
where job =='SALESMAN'
ordr by hiredate desc;
2) python
result = emp[['ename', 'job','hiredate']][emp['job'] == 'SALESMAN']
result.sort_values(by='hiredate' ,ascending =False)
○ 1 유형_5. 중복 값 제거하기
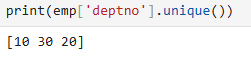
예제1. 부서번호를 출력하는데 중복값을 제거하시오.
1) SQL
select distinct deptno
from emp;
2) python
print(emp['deptno'].unique())
문제 1. 아래의 sql을 판다스로 구현하시오.
1) SQL
select distinct deptno
from emp
where job = 'SALESMAN';
2) python
result = emp[['deptno', 'job']][emp['job'] == 'SALESMAN']
print(result['deptno'].unique())
1) SQL
select ename, length(ename)
from emp;
2) python
2-1) 데이터 프레임 변경 x
pd.concat([emp.ename, emp.ename.str.len()],axis=1)
2-2) 데이터 프레임 변경 o
emp['ename_len']= emp.ename.str.len()
emp[['ename','ename_len']]
문제 7. 타이타닉 승객 이름을 출력하는데 승객 이름이 가장 긴 승객 순으로 정렬해서 출력하고 위의 5명만출력하시오.
1) SQL
select ename,length(ename)
from df
order by length(ename) desc fetch rows only 5 rows only;
2) pandas
2-1) 데이터 프레임 변경 x
result=pd.concat([df.name, df.name.str.len()],axis=1)
result.head(5)
2-2) 데이터 프레임 변경o
df['name_len'] = df.name.str.len()
a = df[['name', 'name_len']].sort_values(by='name_len', ascending=False).head(5)
print(a)
문제 8. 아래의 sql을 pandas로 출력하시오.
1) SQL
select name, instr(ename,',')
from df;
2) python
2-1) 데이터 프레임 변경x
pd.concat([df.name, df.name.str.find(',')], axis =1)
2-2) 데이터 프레임 변경o
df['name_comma']= df.name.str.find(',')
df[['name','name_comma']]
1) SQL
select ename, sal
from emp
where trim(ename) ='SCOTT '; #scott 양쪽에 공백이 있으면 잘라내라
2) python
emp[['ename','sal']][emp.ename.str.strip() =='SCOTT']
- 문자열 (lstrip): 문자열에서 존재하는 왼쪽 공백제거 / 문자열 (rstrip): 문자열에서 존재하는 오른쪽 공백제거
- 문자열 (strip): 문자열에서 존재하는 양쪽 공백제거
○ 1 유형_7. 그룹함수 다루기
※ 그룹함수
오라클
vs
파이썬
max
emp['sal'].max()
min
emp['sal'].min()
sum
emp['sal'].sum()
avg
emp['sal'].mean()
count
emp['sal'].count()
ltrim
emp['sal'].
문제1. 아래의 sql을 pandas로 구현하시오
1) SQL
select max(sal)
from emp;
2) python
emp['sal'].max()
문제2. 아래의 sql을 pandas로 구현하시오
1) SQL
select max(sal)
from emp
where deptno =20;
2) python
emp[['sal']][emp.deptno == 20].max()
문제3. 타이타닉 데이터에서 pclass 가 1인 승객들의 평균나이를 출력하시오.
df[['age']][df.pclass ==1].mean().round()
문제4. 아래의 sql을 pandas로 구현하시오
1) SQL
select job, max(sal)
from emp
group by job;
2) pandas
emp.groupby('job')['sal'].max().reset_index()
-> groupby 와 reset_index() 는 서로 짝꿍입니다. groupby 만 사용하면 결과가 Series 로 나오고 reset_index() 를 뒤에 붙여줘야 dataFrame 으로 출력됩니다.
+) 컬럼명 바꾸기
result = emp.groupby('job')['sal'].max().reset_index()
result.columns = ['job','sumsal']
result
문제 5. 아래의 sql을 pandas로 구현하시오
1) SQL
select deptno, sum(sal)
from emp
group by deptno;
2) python
result = emp.groupby('deptno')['sal'].sum().reset_index()
result.columns = ['deptno','sumsal']
result
문제 6. 위의 결과를 원형그래프로 시각화하시오.
import pandas as pd
import matplotlib.pyplot as plt
# 그룹화하여 부서별 총 급여 계산
result = emp.groupby('deptno')['sal'].sum().reset_index()
result.columns = ['deptno', 'sumsal']
# 원형 그래프 그리기
plt.figure(figsize=(8, 6))
colors = ['pink', 'skyblue','coral']
plt.pie(result['sumsal'], labels=result['deptno'], autopct='%1.1f%%', startangle=140, explode=[0.05,0.05,0.05],colors=colors)
# startangle 그래프의 시작 각도를 설정하는 매개변수
# explode 그래프별 공간 생성
plt.title('Department Salary Distribution')
plt.show()
★ 마지막문제.
1) SQL
select job, sum(sal)
from emp
group by job;
2) python
import pandas as pd
import matplotlib.pyplot as plt
# 그룹화하여 부서별 총 급여 계산
result = emp.groupby('job')['sal'].sum().reset_index()
result.columns = ['job', 'sumsal']
# 원형 그래프 그리기
plt.figure(figsize=(8, 6))
colors = ['#80C0F6', '#6CCF99','#B580F6', '#F5A15B', '#CF8BB0']
plt.pie(result['sumsal'], labels=result['job'], autopct='%1.1f%%', startangle=140,explode=[0.02,0.02,0.02,0.02,0.02], colors=colors)
# startangle 그래프의 시작 각도를 설정하는 매개변수
# explode 그래프별 공간 생성
plt.title('Job Salary Distribution')
plt.show()