# 2개의 파일 합치기
file1_path = 'c:\\data\\joongang_뉴진스.txt'
file2_path = 'c:\\data\\joongang_아이브.txt'
# 합친 파일의 경로
output_file_path = 'c:\\data\\new_ive.txt'
with open(file1_path,'r', encoding='utf8') as file1,\
open(file2_path,'r', encoding='utf8') as file2,\
open(output_file_path,'w', encoding='utf8') as output_file:
# 첫번째 파일의 내용일 읽어와서 작성
output_file.write(file1.read())
output_file.write('\n') # 파일간의 구분을 위해서 줄바꿈 추가
# 두번째 파일의 내용일 읽어와서 작성
output_file.write(file2.read())
print(f'두 파일이 성공적으로 {output_file_path}에 합쳐졌습니다.')
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
# 비교 분석할 텍스트 파일 열기
with open('c:\\data\\new_ive.txt', 'r', encoding = 'utf-8') as file:
text = file.read()
#print(text[:100])
# 텍스트를 엔터로 분리하기
lines = text.split('\n')
#print(lines[:100])
# Counter 모듈을 객체화 하기
date_counts1 = Counter()
date_counts2 = Counter()
current_date = None
# 2023년 또는 2024년으로 시작하는 라인만 추출(기사 날짜와 제목 추출)
for line in lines:
if line.startswith('2023-') or line.startswith('2024-'):
current_date = line[:10] # 날짜만 추출
if current_date:
if '뉴진스' in line: # 뉴진스 라는 단어를 포함한다면
date_counts1[current_date] += line.count('뉴진스')
if '아이브' in line: # 아이브 라는 단어를 포함한다면
date_counts2[current_date] += line.count('아이브')
4. 두 데이터를 병합하여 데이터 프레임 구성
# 판다스 데이터 프레임으로 구성
df1 = pd.DataFrame(list(date_counts1.items()), columns =['date','뉴진스cnt'])
df2 = pd.DataFrame(list(date_counts2.items()), columns =['date','아이브cnt'])
# 날짜를 datetime 형식으로 변환
df1['date'] = pd.to_datetime(df1['date'])
df2['date'] = pd.to_datetime(df2['date'])
# 두 데이터 프레임을 날짜 기준으로 병함
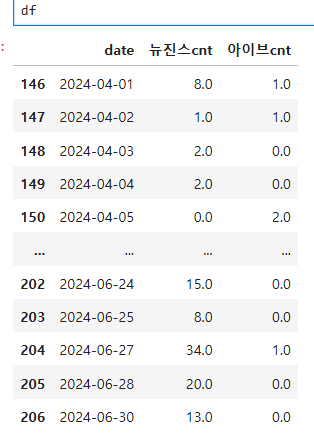
df = pd.merge(df1, df2, on ='date', how ='outer').fillna(0) # null 값을 0으로 처리
# 2024년 4월 1일부터 6월 30일까지의 데이터만 필터링
start_date = pd.Timestamp('2024-04-01')
end_date = pd.Timestamp('2024-06-30')
# 문번: df[컬럼][조건]
df = df[(df['date'] >= start_date) & (df['date'] <=end_date )]
#df
5. 시각화 하기
# 시각화하기
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.figure(figsize=(16,8))
plt.plot(df['date'], df['뉴진스cnt'], marker='o', color= 'b', label= '뉴진스') # 그래프 그리기
plt.plot(df['date'], df['아이브cnt'], marker='o', color= 'g', label= '아이브')
plt.fill_between(df['date'], df['뉴진스cnt'], color= 'b', alpha = 0.1) # 그래프 안에 색 채우기
plt.fill_between(df['date'], df['아이브cnt'], color= 'g', alpha = 0.1)
# 뉴진스 피크값의 날짜를 표시
peak_indices = df[ df['뉴진스cnt'] == df['뉴진스cnt'].max()].index
for i in peak_indices:
plt.text(df['date'][i], df['뉴진스cnt'][i]+1, df['date'][i].strftime('%Y-%m-%d'),
color='b', fontsize=14)
# 아이브 피크값의 날짜를 표시
peak_indices = df[ df['아이브cnt'] == df['아이브cnt'].max()].index
for i in peak_indices:
plt.text(df['date'][i], df['아이브cnt'][i]+1, df['date'][i].strftime('%Y-%m-%d'),
color='g', fontsize=14)
plt.title('날짜별 뉴진스와 아이브 언급량 비교', fontsize=25)
plt.xlabel('날짜', fontsize=15)
plt.ylabel('언급량', fontsize=15)
plt.legend(fontsize=15) #어떤게 뉴진스고 어떤게 아이브인지
plt.grid(True) #눈금
6. 함수 만들기
def relation_word_ja(location, keyword1, keyword2):
# 비교분석 함수 생성
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
#비교 분석할 텍스트 파일 열기
with open( location, "r", encoding="utf-8") as file:
text = file.read()
# 텍스트를 엔터로 분리합니다.
lines = text.split('\n')
#print(lines[:100])
# Counter 모듈을 객체화 합니다.
date_counts1 = Counter()
date_counts2 = Counter()
current_date = None
# 2023년 또는 2024년으로 시작하는 라인만 추출(기사날짜와 제목을 추출)
for line in lines:
if line.startswith('2023-') or line.startswith('2024-'):
current_date = line[:10] # 날짜만 추출
if current_date:
if keyword1 in line: # '뉴진스' 라는 단어를 포함한다면
date_counts1[current_date] += line.count(keyword1)
if keyword2 in line: # '아이브' 라는 단어를 포함한다면
date_counts2[current_date] += line.count(keyword2)
# 판다스 데이터 프레임으로 구성
df1 = pd.DataFrame(list(date_counts1.items()), columns=['date',f'{keyword1}cnt'] )
df2 = pd.DataFrame(list(date_counts2.items()), columns=['date',f'{keyword2}cnt'] )
# 날짜를 datetime 형식으로 변환
df1['date'] = pd.to_datetime(df1['date'])
df2['date'] = pd.to_datetime(df2['date'])
# 두 데이터 프레임을 날짜 기준으로 병합
df = pd.merge(df1, df2, on='date', how='outer').fillna(0)
# 2024년 4월 1일 부터 6월 30일까지의 데이터만 필터링
start_date = pd.Timestamp('2024-04-01')
end_date = pd.Timestamp('2024-08-28')
#문법: df[컬럼선택][검색조건]
df = df[:][(df['date'] >= start_date) & ( df['date'] <= end_date)]
# 시각화 하기
plt.rcParams['font.family'] = 'Malgun Gothic' # 한글 안깨지게
plt.figure(figsize=(16,8))
plt.plot(df['date'], df[f'{keyword1}cnt'], marker='o', color='b', label=f'{keyword1}')
plt.plot(df['date'], df[f'{keyword2}cnt'], marker='o', color='g', label=f'{keyword2}')
plt.fill_between(df['date'], df[f'{keyword1}cnt'], color='blue', alpha=0.1)
plt.fill_between(df['date'], df[f'{keyword2}cnt'], color='green', alpha=0.1)
# 뉴진스 피크값의 날짜를 표시
peak_indices = df[ df[f'{keyword1}cnt'] == df[f'{keyword1}cnt'].max()].index
for i in peak_indices:
plt.text(df['date'][i], df[f'{keyword1}cnt'][i] + 1, df['date'][i].strftime('%Y-%m-%d'),
color='red', fontsize=14)
# 아이브 피크값의 날짜를 표시
peak_indices = df[ df[f'{keyword2}cnt'] == df[f'{keyword2}cnt'].max()].index
for i in peak_indices:
plt.text(df['date'][i], df[f'{keyword2}cnt'][i] + 1, df['date'][i].strftime('%Y-%m-%d'),
color='green', fontsize=14)
plt.title(f'날짜별 {keyword1} 와 {keyword2} 언급량 비교', fontsize=16)
plt.xlabel('날짜', fontsize=14)
plt.ylabel('언급량', fontsize=14)
plt.legend(fontsize=14)
plt.grid(True)