import urllib.request
from bs4 import BeautifulSoup
import time
# 상세 기사 url 수집함수
def da_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+10):
list_url = "https://www.donga.com/news/search?p="+str(i)+"&query="+ text1 +"&check_news=91&sorting=1&search_date=1&v1=&v2=&more=1"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "article > div > h4 > a" ):
params.append( i.get("href") )
time.sleep(1)
return params
print(da_detail_url('인공지능', 1))
# 기사 본문 수집 함수
def da(keyword, num):
f_donga = open("c:\\data\\donga.txt", "w", encoding="utf8" )
result = da_detail_url(keyword, num)
for i in result:
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
#날짜 가져오기
date_text = ""
for d in soup.select(" #contents > header > div > section > ul > li:nth-child(2) "):
date_text = d.text.strip()
f_donga.write( date_text + '\n\n') #날짜 저장
print (d.text)
#본문 가져오기
for i in soup.select("#contents > div.view_body > div > div.main_view > section.news_view"): # div.innterwrap 밑에 p 테그들은 다 선택해라
article_text = i.text.strip() #본문 기사 양쪽의 공백을 잘라냄
f_donga.write( article_text + '\n') #본문 기사 저장
print(article_text)
f_donga.write("\n" + "="*60 + "\n\n") #기사 구분선
f_donga.close()
da("인공지능",1)
실습. 동아 일보 두개의 함수를 yys.py 에 추가하시오.
■ 중앙일보
중앙일보 웹 크롤링
import urllib.request
from bs4 import BeautifulSoup
import time
# 상세 기사 url 수집함수
def ja_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://www.joongang.co.kr/search/news?keyword=" + text1 + "&page=" + str(i)
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
#container > section > div > section > ul > li:nth-child(1) > div > h2 > a
for i in soup.select( "div.card_body > h2.headline > a" ):
params.append( i.get("href") )
if len(params) > 5 : # 맨끝에 불필요한 5개의 기사를 제외 시킵니다.
params = params[:-5]
time.sleep(1)
return params
import urllib.request
from bs4 import BeautifulSoup
# 기사 본문 수집 함수
def ja(keyword, num):
f_ja = open("c:\\data\\joongang.txt", "w", encoding="utf8")
result = ja_detail_url(keyword, num)
for i in result:
url = urllib.request.Request(i)
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(f, "html.parser")
# 날짜 가져오기 (datetime 속성 값)
date_text = ""
date_element = soup.select_one("time") # 첫번째 time 태그를 선택합니다.
if date_element:
date_text = date_element['datetime'].strip() # datetime 속성 값 가져오기
f_ja.write(date_text + '\n') # 날짜 저장
print(date_text)
# 본문 가져오기 (주석 해제 시 본문도 가져옵니다)
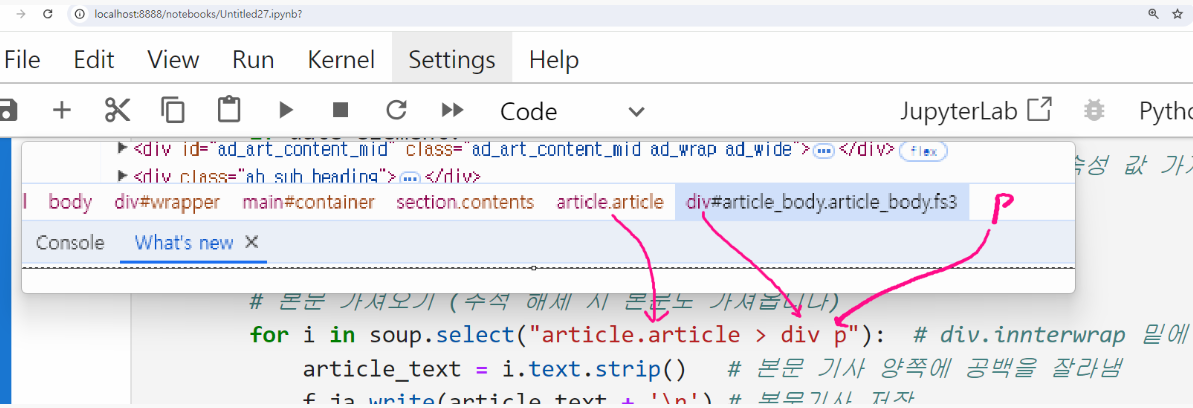
for i in soup.select("article.article > div p"): # div.innterwrap 밑에 p 태그들 선택
article_text = i.text.strip() # 본문 기사 양쪽에 공백을 잘라냄
f_ja.write(article_text + '\n') # 본문기사 저장
print(article_text)
f_ja.write("\n" + "="*50 + "\n\n") # 기사 구분
print(cnt)
f_ja.close()
# 함수 실행 예시
ja('인공지능', 1)
※ 전체 코드 총합
import urllib.request
from bs4 import BeautifulSoup
import time
# 상세 기사 url 수집함수
def ja_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://www.joongang.co.kr/search/news?keyword=" + text1 + "&page=" + str(i)
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
#container > section > div > section > ul > li:nth-child(1) > div > h2 > a
for i in soup.select( "div.card_body > h2.headline > a" ):
params.append( i.get("href") )
if len(params) > 5 : # 맨끝에 불필요한 5개의 기사를 제외 시킵니다.
params = params[:-5]
time.sleep(1)
return params
import urllib.request
from bs4 import BeautifulSoup
# 기사 본문 수집 함수
def ja(keyword, num):
f_ja = open("c:\\data\\joongang.txt", "w", encoding="utf8")
result = ja_detail_url(keyword, num)
for i in result:
url = urllib.request.Request(i)
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(f, "html.parser")
# 날짜 가져오기 (datetime 속성 값)
date_text = ""
date_element = soup.select_one("time") # 첫번째 time 태그를 선택합니다.
if date_element:
date_text = date_element['datetime'].strip() # datetime 속성 값 가져오기
f_ja.write(date_text + '\n') # 날짜 저장
print(date_text)
# 본문 가져오기 (주석 해제 시 본문도 가져옵니다)
for i in soup.select("article.article > div p"): # div.innterwrap 밑에 p 태그들 선택
article_text = i.text.strip() # 본문 기사 양쪽에 공백을 잘라냄
f_ja.write(article_text + '\n') # 본문기사 저장
print(article_text)
f_ja.write("\n" + "="*50 + "\n\n") # 기사 구분
print(cnt)
f_ja.close()
# 함수 실행 예시
ja('인공지능', 1)
이슈화된 내용: 중앙일보는 기사 날짜 부분이 자바 스크립트로 막혀있어서 우회해서 html 코드에 있는 시간을 직접 가져옴
※ 모듈화
■ 한겨례
# 한겨례 신문사
import urllib.request
from bs4 import BeautifulSoup
import time
from datetime import datetime
# 상세 기사 url 수집함수
def han_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 상세기사 url 을 저장하기 위한 리스트 입니다.
params2 = [ ] # 날짜를 저장하기 위한 리스트 입니다.
today = datetime.today()
date = str(today)[0:10].replace("-", "." )
for i in range(1,num+1):
list_url = "https://search.hani.co.kr/search/newslist?searchword=" + text1 + "&startdate=1988.01.01&enddate=" + date + "&page=" + str(i) + "&sort=desc"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
#content > section > div > div.flex-inner > div.left > div.search-result-section > ul > li:nth-child(1) > article > a
# 상세 기사 url 가져오기
for i in soup.select( "article > a" ):
params.append( i.get("href") )
# 상세 기사의 날짜 가져오기
for i in soup.select( "span.article-date" ):
params2.append( i.text )
time.sleep(1)
return params, params2
print(han_detail_url('인공지능', 1) )
※ 전체코드
# 한겨례 신문사
import urllib.request
from bs4 import BeautifulSoup
import time
from datetime import datetime
# 상세 기사 url 수집함수
def han_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 상세기사 url 을 저장하기 위한 리스트 입니다.
params2 = [ ] # 날짜를 저장하기 위한 리스트 입니다.
today = datetime.today()
date = str(today)[0:10].replace("-", "." )
for i in range(1,num+1):
list_url = "https://search.hani.co.kr/search/newslist?searchword=" + text1 + "&startdate=1988.01.01&enddate=" + date + "&page=" + str(i) + "&sort=desc"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
#content > section > div > div.flex-inner > div.left > div.search-result-section > ul > li:nth-child(1) > article > a
# 상세 기사 url 가져오기
for i in soup.select( "article > a" ):
params.append( i.get("href") )
# 상세 기사의 날짜 가져오기
for i in soup.select( "span.article-date" ):
params2.append( i.text )
time.sleep(1)
return params, params2
# 기사 본문 수집 함수
def han(keyword, num):
f_han = open("c:\\data\\han.txt", "w", encoding="utf8" )
result1, result2 = han_detail_url(keyword, num)
for i, d in zip(result1, result2):
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
# 날짜 가져오기
f_han.write( d + '\n')
print(d)
# 본문 가져오기
for i in soup.select("div > p"):
article_text = i.text.strip() # 본문 기사 양쪽에 공백을 잘라냄
f_han.write( article_text + '\n') # 본문기사 저장
print(article_text)
f_han.write("/n" + "="*50 + "\n\n") # 기사 구분
f_han.close()
han('비건&채식', 1)