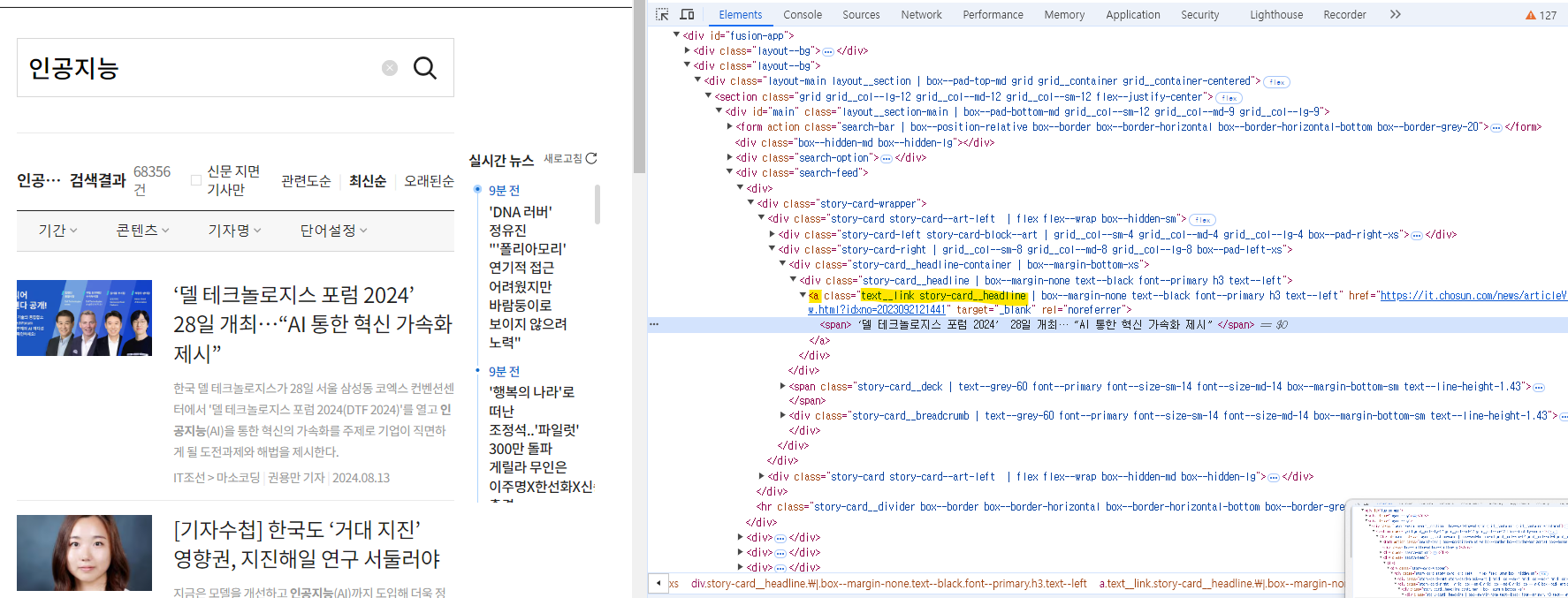
실습 2. '인공지능'으로 검색한 첫 페이지부터 3번째 페이지까지의 url을 생성하시오. ※ 반드시 아래의 페이지 번호를 클릭하고 url을 복사해야 됨
import urllib.request
text1 = urllib.parse.quote("인공지능") # "인공지능" 문자열을 url 에 안전하게 포함할 수 있도록 인코딩합니다.
# 인코딩 : 기계가 알아볼 수 있게 변경해주는 작업
# 디코딩 : 사람이 알아볼 수 있게 변경해주는 작업
list_url = "https://search.hankookilbo.com/Search?Page=1&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
실습 3. 위의 url의 페이지 번호가 1~3번까지 변경될 수 있도록 for loop 문을 입력하시오.
import urllib.request
text1 = urllib.parse.quote("인공지능") # "인공지능" 문자열을 url 에 안전하게 포함할 수 있도록 인코딩합니다.
# 인코딩 : 기계가 알아볼 수 있게 변경해주는 작업
# 디코딩 : 사람이 알아볼 수 있게 변경해주는 작업
for i in range(1,4):
list_url = "https://search.hankookilbo.com/Search?Page="+ str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
print(list_url)
실습 4. 위의 url을 파이썬이 한국일보 웹서버에 요청을 보낼 수 있는 상태로 만드시오.
import urllib.request
from bs4 import BeautifulSoup
text1 = urllib.parse.quote("인공지능") # "인공지능" 문자열을 url 에 안전하게 포함할 수 있도록 인코딩합니다.
# 인코딩 : 기계가 알아볼 수 있게 변경해주는 작업
# 디코딩 : 사람이 알아볼 수 있게 변경해주는 작업
for i in range(1,4):
list_url = "https://search.hankookilbo.com/Search?Page="+ str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request(list_url) # 웹서버로 전달해 줄 수 있는 상태로 만듦
f=urllib.request.urlopen(url).read().decode('utf8') # url로 부터 데이터를 가져와 utf8로 디코딩함
실습 5. 위의 f를 BeautifulSoup 모듈로 파싱해서 html코드를 출력하시오.
import urllib.request
from bs4 import BeautifulSoup
text1 = urllib.parse.quote('인공지능') # '인공지능' 문자열을 url 에 안전하게 포함될 수 있도록 인코딩함.
for i in range(1,4):
list_url = 'https://search.hankookilbo.com/Search?Page='+ str(i) +'&tab=NEWS&sort=relation&searchText=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head'
url = urllib.request.Request(list_url) # 웹서버로 요청을 보낼 수 있는 상태로 만든 것.
f = urllib.request.urlopen(url).read().decode('utf-8') # url로부터 데이터를 가져와서 디코딩 한 것.
soup = BeautifulSoup(f,'html.parser')
print(soup)
실습 6. 상세기사로 접속할 수 있는 url 주소의 태그 이름과 클래스 이름을 알아내시오. 답: div.inn > h3 > a (태그(클래스) 이름> 태그이름> 태그이름)
실습 7. 위의 태그 주소로 상세기사 url을 긁어와 출력하시오.
import urllib.request
from bs4 import BeautifulSoup
text1 = urllib.parse.quote('인공지능') # '인공지능' 문자열을 url 에 안전하게 포함될 수 있도록 인코딩함.
for i in range(1,4):
list_url = 'https://search.hankookilbo.com/Search?Page='+ str(i) +'&tab=NEWS&sort=relation&searchText=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head'
url = urllib.request.Request(list_url) # 웹서버로 요청을 보낼 수 있는 상태로 만든 것.
f = urllib.request.urlopen(url).read().decode('utf-8') # url로부터 데이터를 가져와서 디코딩 한 것.
soup = BeautifulSoup(f,'html.parser')
for i in soup.select('div.inn>h3>a'):
print(i.get('href'))
설명: div 태그의 inn 클래스의 자식 태그인 h3태그로 접근하고 그 자식인 a태그로 접근해서 그 html코드를 가져오는데 그중에 href의 url만 가져오라는 뜻
+ 상세 기사 url이 2개씩 보이는 이유는 기사 제목을 클릭해도 기사를 볼 수 있고 사진을 클릭해도 기사를 볼 수 있기 때문임.
실습 8. 중복이 되지 않게끔 기사 제목의 url만 가져오도록 주소를 구성하시오.
import urllib.request
from bs4 import BeautifulSoup
text1 = urllib.parse.quote('인공지능') # '인공지능' 문자열을 url 에 안전하게 포함될 수 있도록 인코딩함.
for i in range(1,4):
list_url = 'https://search.hankookilbo.com/Search?Page='+ str(i) +'&tab=NEWS&sort=relation&searchText=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head'
url = urllib.request.Request(list_url) # 웹서버로 요청을 보낼 수 있는 상태로 만든 것.
f = urllib.request.urlopen(url).read().decode('utf-8') # url로부터 데이터를 가져와서 디코딩 한 것.
soup = BeautifulSoup(f,'html.parser')
for i in soup.select('div.inn>h3.board-list.h3.pc_only>a'):
print(i.get('href'))
실습 9. 위에서 출력되고 있는 상세 url을 비어있는 리스트에 담아내시오.
import urllib.request
from bs4 import BeautifulSoup
text1 = urllib.parse.quote('인공지능') # '인공지능' 문자열을 url 에 안전하게 포함될 수 있도록 인코딩함.
params= []
for i in range(1,2):
list_url = 'https://search.hankookilbo.com/Search?Page='+ str(i) +'&tab=NEWS&sort=relation&searchText=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head'
url = urllib.request.Request(list_url) # 웹서버로 요청을 보낼 수 있는 상태로 만든 것.
f = urllib.request.urlopen(url).read().decode('utf-8') # url로부터 데이터를 가져와서 디코딩 한 것.
soup = BeautifulSoup(f,'html.parser')
for i in soup.select('div.inn>h3.board-list.h3.pc_only>a'):
print(i.get('href'))
params.append(i.get('href'))
print(params)
실습 10. 위의 코드를 hankook_detail_url 이라는 함수로 생성하시오.
import urllib.request
from bs4 import BeautifulSoup
def hankook_detail_url():
text1 = urllib.parse.quote('인공지능')
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,2):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "div.inn > h3.board-list.h3.pc_only > a" ):
params.append( i.get("href") )
return params
print(hankook_detail_url() )
실습 11. hankook_detail_url(3) 이렇게 숫자를 넣어서 실행하면 3번째 페이지까지의 상세기사 url 이 params 리스트에 담기게 하시오.
import urllib.request
from bs4 import BeautifulSoup
def hankook_detail_url(num):
text1 = urllib.parse.quote('인공지능')
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "div.inn > h3.board-list.h3.pc_only > a" ):
params.append( i.get("href") )
return params
print(hankook_detail_url(3) )
실습 12. hankook_detail_url('인공지능',3) 이렇게 검색 키원드도 직접 넣을 수 있도록 함수를 구성하시오.
import urllib.request
from bs4 import BeautifulSoup
def hankook_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "div.inn > h3.board-list.h3.pc_only > a" ):
params.append( i.get("href") )
return params
hankook_detail_url('인공지능', 3)
실습 13. 중간중간 sleep을 1초씩 주시오!
import urllib.request
from bs4 import BeautifulSoup
import time
def hankook_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "div.inn > h3.board-list.h3.pc_only > a" ):
params.append( i.get("href") )
time.sleep(1)
return params
hankook_detail_url('인공지능', 3)
실습 14. 위에 기사 하나를 선별하고 접속해서 상세기사 본문이 있는 태그 주소를 알아내시오!
답: 1. 첫 번째 방법: div.innerwrap > div.col-main> p.editor-p.read -> 정확하게 문단을 찾아갈 수는 있는데, 다른 div.col-main 밑에 다른 p태그가 있다면 그 p태그는 선택되지 않음 (제대로 검색 x)
2. 두 번째 방법: div.innerwrap p -> div.innerwrap 클래스가 있는 하위 디렉터리에 있는 모든 p 태그를 선택하게 됨. 구조가 다르더라도 원하는 결과를 얻을 가능성이 높음
실습 15. 아래의 상세 기사 본문을 가져올 수 있는 코드를 작성하시오.
import urllib.request
from bs4 import BeautifulSoup
list_url ="https://hankookilbo.com/News/Read/A2024081308040002690"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select('div.innerwrap p'): # div.innerwrap 밑에 p태그들을 다 선택해라
print(i.text)
실습 16. 이번에는 위의 코드를 수정해서 기사를 출력하는 것이 아닌 c드라이브 밑에 data 밑에 hankook.txt로 저장되게 하시오.
import urllib.request
from bs4 import BeautifulSoup
f_hankook = open("c:\\data\\hankook.txt", "w", encoding="utf8" )
list_url ="https://hankookilbo.com/News/Read/A2024081308040002690"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select("div.innerwrap p"): # div.innterwrap 밑에 p 테그들은 다 선택해라
f_hankook.write( i.text + '\n')
f_hankook.close()
실습 17. 위에 코드는 기사 하나만 가져와서 본문을 저장하는 코드인데 이번에는 여러 개의 상세기사 url을 가져와서 여러개의 본문이 저장되게 하시오.
import urllib.request
from bs4 import BeautifulSoup
import time
def hankook_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "div.inn > h3.board-list.h3.pc_only > a" ):
params.append( i.get("href") )
time.sleep(1)
return params
result = hankook_detail_url('인공지능', 3) # 인공지능으로 검색했을 때 3페이지의
# 상세 기사 url 이 result 리스트로 만들어짐
#print(result)
## result 리스트를 가져다가 하나씩 불러와서 기사 본문을 출력하는 코드
import urllib.request
from bs4 import BeautifulSoup
f_hankook = open("c:\\data\\hankook.txt", "w", encoding="utf8" )
result = hankook_detail_url('인공지능', 3)
for i in result:
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select("div.innerwrap p"): # div.innterwrap 밑에 p 테그들은 다 선택해라
f_hankook.write( i.text + '\n')
f_hankook.close()
설명: result 리스트를 가져다가 하나씩 불러와서 본문을 출력하는 코드
실습 18. 방금 상세 url로 기사 본문을 가져오는 코드를 hankook이라는 이름의 함수로 생성하기오
## result 리스트를 가져다가 하나씩 불러와서 기사 본문을 출력하는 코드
import urllib.request
from bs4 import BeautifulSoup
def hankook(keyword, num):
f_hankook = open("c:\\data\\hankook.txt", "w", encoding="utf8" )
result = hankook_detail_url(keyword, num)
for i in result:
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select("div.innerwrap p"): # div.innterwrap 밑에 p 테그들은 다 선택해라
f_hankook.write( i.text + '\n')
f_hankook.close()
hankook('드론', 3)
실습 19. 위 함수 2개를 chj.py와 넣어 모듈화 하시오.
if __name__ !='__main__':
print('chj 모듈이 임폴트 되었습니다.')
print('함수 목록')
print('1. check_even_odd: 짝수와 홀수 판정 함수')
print('2. check_number: 양수와 음수 판정 함수')
print('3. wrap: 문자열을 특정 문자로 감싸는 함수')
print('4. plot_bar_graph: 막대 그래프를 그리는 함수')
print('5. plot_pie_grapph: 원형 그래프 그리는 함수')
print('6. hankook(키워드, 페이지 수): 한국일보 데이터 수집')
else:
print('chj.py 가 직접 실행되었습니다.')
# 1. 짝수 홀수 판정 함수
def check_even_odd(number):
if number % 2 == 0:
return '짝수입니다.'
else:
return '홀수입니다.'
# 2. 양수인지 음수인지 판정하는 함수
def check_number(num):
if num > 0:
return '양수입니다.'
elif num < 0 :
return '음수입니다.'
else:
return '0 입니다.'
# 3. (데이터 전처리 1) 문자열을 특정 문자로 감싸는 함수
def wrap(text, char = "'"):
return char + text + char
# 4. (데이터 시각화) 막대 그래프 그리는 함수
import plotly.graph_objects as go
def plot_bar_graph(x, y):
"""
x와 y 리스트를 받아 막대 그래프를 그리는 함수.
"""
# 막대 그래프 생성
fig = go.Figure(data=[go.Bar(x=x, y=y, marker = dict(color = 'LightPink'))])
# 레이아웃 설정
fig.update_layout(
title="막대 그래프 예시",
xaxis_title="X 축",
yaxis_title="Y 축",
template="plotly", # 다른 스타일 사용 가능: "plotly_dark", "ggplot2"
font=dict(
family="Arial, sans-serif",
size=14,
color="RebeccaPurple"
)
)
# 그래프 표시
fig.show()
# 5. 원형 그래프 그리는 함수
import plotly.graph_objects as go # 파이썬 plotly 라이브러리를 가져오는 코드
def plot_pie_chart(labels, values): # 원형 그래프를 그리는 함수(파이조각 이름, 파이조각 크기)
"""
labels와 values 리스트를 받아 원형 그래프를 그리는 함수.
"""
# 원형 그래프 생성
fig = go.Figure(data=[go.Pie(labels=labels, values=values)]) # 원형 그래프 객체 생성
# 레이아웃 설정
fig.update_layout(
title="원형 그래프 예시",
template="plotly", # 다른 스타일 사용 가능: "plotly_dark", "ggplot2"
font=dict( # 그래프에서 사용되는 글꼴 스타일을 지정하는 것
family="Arial, sans-serif",
size=14,
color="RebeccaPurple"
)
)
# 그래프 표시
fig.show()
# 6. 한국일보 데이터 수집 함수 2개
import urllib.request
from bs4 import BeautifulSoup
import time
def hankook_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,2):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select("div.inn > h3.board-list.h3.pc_only > a"):
params.append( i.get("href") )
return params
import urllib.request
from bs4 import BeautifulSoup
def hankook(keyword, num):
f_hankook = open("c:\\data\\hankook.txt", "w", encoding="utf8" )
result = hankook_detail_url(keyword, num)
for i in result:
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select("div.innerwrap p"): # div.innterwrap 밑에 p 테그들은 다 선택해라
f_hankook.write( i.text + '\n')
f_hankook.close()
실습 20. 기사를 쓴 날짜에 접근할 수 있도록 테그 주소를 알아내시오!
1. soup.select("ul.board-list li em") 2. soup.select("ul.board-list li div.inn p.date_mb_only em")
text1 = urllib.parse.quote("인공지능")
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,2):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select("ul.board-list li em"):
print( i.text )
이 방법은 방금 올린 기사도 있기 때문에 날짜를 가져오지 못하는 기사도 있습니다. 그래서 상세기사로 들어가서 거기서 최초 올린 날짜로 가져옵니다.
실습 21. 최초로 기사를 올린 날짜를 긁어오시오.
# 함수 생성
import urllib.request
from bs4 import BeautifulSoup
import time
def hankook_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,2):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select("div.inn > h3.board-list.h3.pc_only > a"):
params.append( i.get("href") )
return params
result = hankook_detail_url('인공지능', 3) # 인공지능으로 검색했을 때 3 페이지의 상세기사 url이 result 리스트로 만들어지도록 함.
# 최초 기사 업로드 코드
import urllib.request
from bs4 import BeautifulSoup
def hankook(keyword, num):
f_hankook = open("c:\\data\\hankook.txt", "w", encoding="utf8" )
result = hankook_detail_url(keyword, num)
for i in result:
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
#for i in soup.select("div.innerwrap p"): # div.innterwrap 밑에 p 테그들은 다 선택해라
# f_hankook.write( i.text + '\n')
for d in soup.select("div.col-main dl.wrt-text dd"):
print( d.text )
f_hankook.close()
hankook('드론', 3)
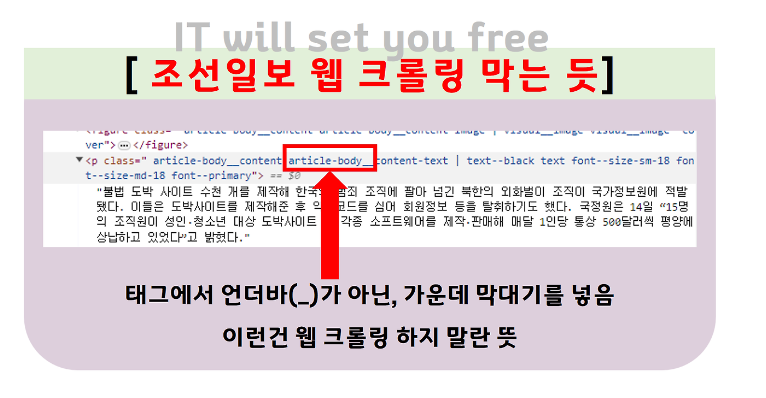
★ 마지막 문제. 오늘 만든 한국일보 데이터 수집 함수 2개를 조선일보를 수집할 수 있도록 구성합니다.
1. 조선일보에서 인공지능을 검색했을 때 가져오는 상세 url 을 출력하는 함수를 생성하시오.
import urllib.request
from bs4 import BeautifulSoup
def chosun_detail_url(num):
text1 = urllib.parse.quote('인공지능')
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://www.chosun.com/nsearch/?query=" + text1 + "&page=1" +str(i) + "&siteid=&sort=1&date_period=all&date_start=&date_end=&writer=&field=&emd_word=&expt_word=&opt_chk=false&app_check=0&website=www,chosun&category="
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "a.text_link.story-card_headline" ):
params.append( i.get("href") )
return params
print(chosun_detail_url(3) )
240814 추가 수정(최종)
실습 1(복습). 한국일보 기사 데이터 수집 날짜 데이터 가져오기 전 코드
import urllib.request
from bs4 import BeautifulSoup
import time
# 상세 기사 url 수집함수
def hankook_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "div.inn > h3.board-list.h3.mb_only > a" ):
params.append( i.get("href") )
time.sleep(1)
return params
# 기사 본문 수집 함수
def hankook(keyword, num):
f_hankook = open("c:\\data\\hankook.txt", "w", encoding="utf8" )
result = hankook_detail_url(keyword, num)
for i in result:
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
# 날짜 가져오기
date_text = ''
for d in soup.select('div.innerwrap > div > div.info > dl'):
date_text =d.text.strip()
f_hankook.write( date_text + '\n')
print(d.text)
# 본문 가져오기
#for i in soup.select("div.innerwrap div.col-main p"): # div.innterwrap 밑에 p 테그들은 다 선택해라
# f_hankook.write( i.text + '\n')
# print(i.text)
f_hankook.close()
hankook('비건&채식', 1)
설명: > 는 직접 자식 요소만 선택/ 공백은 모든 후손 요소를 선택
★ 실습2. 날짜와 기사를 하나로 묶어서 출력하고 저장되게하시오.
import urllib.request
from bs4 import BeautifulSoup
import time
# 상세 기사 url 수집함수
def hankook_detail_url(keyword, num):
text1 = urllib.parse.quote(keyword)
params = [ ] # 비어있는 리스트를 생성합니다.
for i in range(1,num+1):
list_url = "https://search.hankookilbo.com/Search?Page=" + str(i) + "&tab=NEWS&sort=relation&searchText=" + text1 + "&searchTypeSet=TITLE,CONTENTS&selectedPeriod=%EC%A0%84%EC%B2%B4&filter=head"
url = urllib.request.Request( list_url )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
for i in soup.select( "div.inn > h3.board-list.h3.pc_only > a" ):
params.append( i.get("href") )
time.sleep(1)
return params
# 기사 본문 수집 함수
def hankook(keyword, num):
f_hankook = open("c:\\data\\hankook.txt", "w", encoding="utf8" )
result = hankook_detail_url(keyword, num)
for i in result:
url = urllib.request.Request( i )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f , "html.parser")
# 날짜 가져오기
date_text = ""
for d in soup.select("div.innerwrap > div > div.info > dl"):
date_text = d.text.strip()
f_hankook.write( date_text + '\n') # 날짜 저장
print( d.text )
# 본문 가져오기
for i in soup.select("div.innerwrap div.col-main p"): # div.innterwrap 밑에 p 테그들은 다 선택해라
article_text = i.text.strip() # 본문 기사 양쪽에 공백을 잘라냄
f_hankook.write( article_text + '\n') # 본문기사 저장
print(article_text)
f_hankook.write("\n" + "="*50 + "\n\n") # 기사 구분
f_hankook.close()
hankook('비건&채식', 1)