Selenium은 웹 브라우저에서 자동으로 테스트를 실행할 수 있게 도와주는 도구입니다. 예를 들어, 웹사이트의 버튼을 클릭하거나 폼을 작성하는 작업을 자동으로 수행하여, 사이트가 제대로 작동하는지 확인할 수 있습니다. 다양한 브라우저와 프로그래밍 언어를 지원하여 유연하게 사용할 수 있습니다.
4. 다운로드 후 압축풀기 (C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe)
5. 필요한 모듈을 임폴트하는 코드 작성 (파이썬에서)
import urllib.request #웹요청
from bs4 import BeautifulSoup #HTML 파싱
from selenium import webdriver # 브라우져 제어
from selenium.webdriver.chrome.service import Service # 드라이버 관리
from selenium.webdriver.common.by import By #요소 탐색
import time # 대기시간
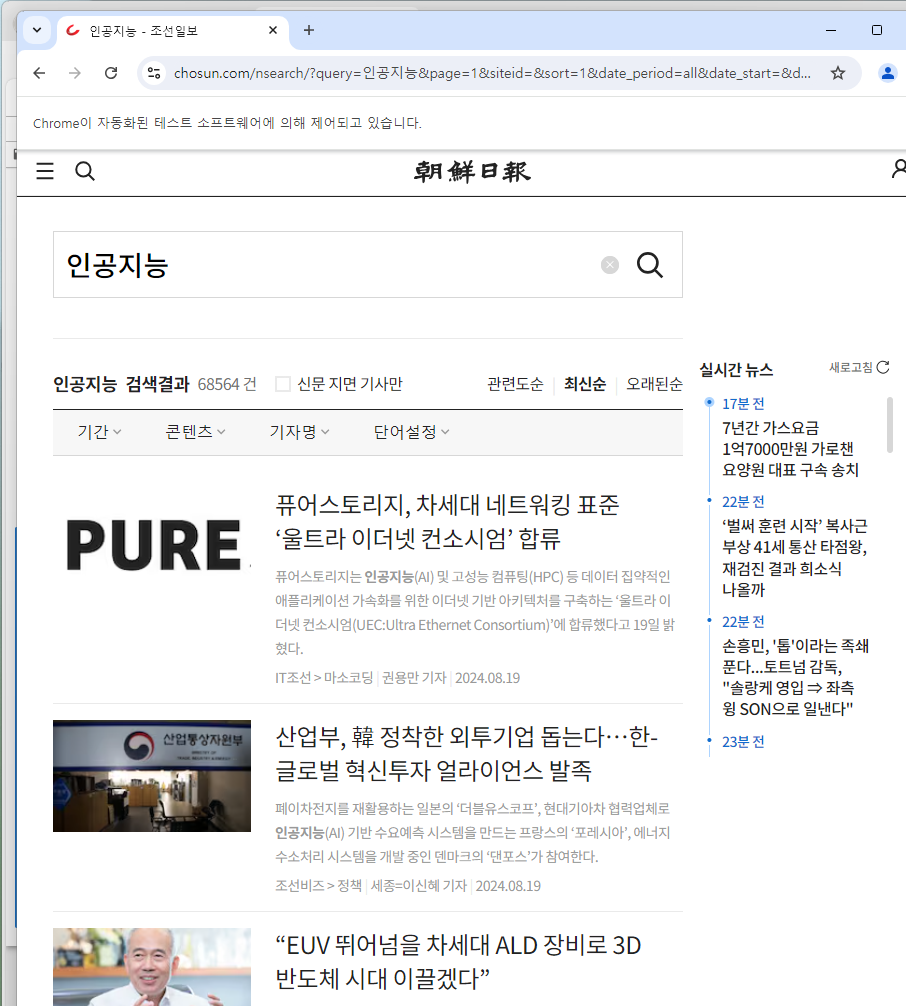
※ 조선일보 웹 스크롤링
1. 코드 작성으로 직접 마우스로 접속한 것 처럼 보이게 하기.
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
def js_detail_url (keyword, num):
# 키워드 검색
text1 = urllib.parse.quote(keyword)
# 크롬 드라이버의 경로지정
service = Service ("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver =webdriver.Chrome(service =service)
params = []
for i in range(1, num +1):
list_url = "https://www.chosun.com/nsearch/?query=" +text1 +"&page=" +str(i) +"&siteid=&sort=1&date_period=all&date_start=&date_end=&writer=&field=&emd_word=&expt_word=&opt_chk=false&app_check=0&website=www,chosun&category="
driver.get(list_url) # 크롬이 열리면서 이 url로 접속함
time.sleep(5) # 페이지가 완전히 로드 될 때 까지 대기(필요에 따라 조정)
js_detail_url("인공지능",1)
설명: 위 페이지가 코드 작성하면 자동으로 뜸.
import urllib.request # 웹요청
from bs4 import BeautifulSoup # HTML 파싱
from selenium import webdriver # 브라우져 제어
from selenium.webdriver.chrome.service import Service # 드라이버 관리
from selenium.webdriver.common.by import By # 요소 탐색
import time # 대기시간
def js_detail_url( keyword, num ):
# 키워드 검색
text1 = urllib.parse.quote(keyword)
# 크롬 드라이버의 경로 지정
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service=service)
params = set() # 중복된 링크를 제거하기 위해서 set을 사용
for i in range( 1, num+1):
list_url="https://www.chosun.com/nsearch/?query=" + text1 + "&page=" + str(i) + "&siteid=&sort=1&date_period=all&date_start=&date_end=&writer=&field=&emd_word=&expt_word=&opt_chk=false&app_check=0&website=www,chosun&category="
driver.get(list_url) # 크롬이 열리면서 이 url 로 접속합니다.
time.sleep(5) # 페이지가 완전히 로드 될때까지 대기(필요따라 조정)
#html 페이지에서 iframe 을 찾고 전환하는 코드
#iframe 내부에 포함된 콘텐츠는 기본 html 문서와 분리되어 있으므로
# html 코드에 접근을 할 수 없습니다. 접근할 수 있도록 해주는 코드
try:
iframe = driver.find_element(By.CSS_SELECTOR,"iframe_selector_here")
driver.switch_to.frame(iframe)
time.sleep(2)
except:
print("iframe 을 찾을 수 없습니다. 기본 페이지에서 진행합니다")
# 크롬 로봇이 직접 인공지능으로 검색한 페이지의 html 코드를 BS으로 파싱합니다.
soup = BeautifulSoup(driver.page_source, "html.parser")
# 기사 상세 URL 을 params 리스트에 추가합니다.
for i in soup.select('a.text__link.story-card__headline'):
params.add( i.get("href"))
driver.quit() # 작업이 끝나면 브라우저를 종료
return params
js_detail_url("인공지능", 1 )
# 조선일보 두번째 함수
def josun( keyword, num ):
# 조선일보 본문 저장할 텍스트 파일 생성
f_josun = open("c:\\data\\josun.txt", "w", encoding="utf8")
# 상세 기사 url 가져오는 코드
result = js_detail_url(keyword, num)
# 크롬 로봇의 위치를 지정합니다.
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service=service)
for i in result:
driver.get(i) # 크롬 로봇이 상세 기사 url 을 하나씩 엽니다.
time.sleep(5)
josun('인공지능', 1)
설명: 자동적으로 목차에 있는 홈페이지가 계속 켜짐
★ it 조선 날짜, 본문, 파일저장 코드
import urllib.request # 웹요청
from bs4 import BeautifulSoup # HTML 파싱
from selenium import webdriver # 브라우져 제어
from selenium.webdriver.chrome.service import Service # 드라이버 관리
from selenium.webdriver.common.by import By # 요소 탐색
import time # 대기시간
def js_detail_url( keyword, num ):
# 키워드 검색
text1 = urllib.parse.quote(keyword)
# 크롬 드라이버의 경로 지정
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service=service)
params = [] # 중복된 링크를 제거하기 위해서 set 을 사용합니다.
for i in range( 1, num+1):
list_url="https://www.chosun.com/nsearch/?query="+ text1 + "&page=" + str(i) + "&siteid=itchosun&sort=1&date_period=all&date_start=&date_end=&writer=&field=&emd_word=&expt_word=&opt_chk=false&app_check=0&website=www,chosun&category="
driver.get(list_url) # 크롬이 열리면서 이 url 로 접속합니다.
time.sleep(5) # 페이지가 완전히 로드 될때까지 대기(필요따라 조정)
#html 페이지에서 iframe 을 찾고 전환하는 코드
#iframe 내부에 포함된 콘텐츠는 기본 html 문서와 분리되어 있으므로
# html 코드에 접근을 할 수 없습니다. 접근할 수 있도록 해주는 코드
try:
iframe = driver.find_element(By.CSS_SELECTOR,"iframe_selector_here")
driver.switch_to.frame(iframe)
time.sleep(2)
except:
print("iframe 을 찾을 수 없습니다. 기본 페이지에서 진행합니다")
# 크롬 로봇이 직접 인공지능으로 검색한 페이지의 html 코드를 BS으로 파싱합니다.
soup = BeautifulSoup(driver.page_source, "html.parser")
# 기사 상세 URL 을 params 리스트에 추가합니다.
for i in soup.select('a.text__link.story-card__headline'):
params.append( i.get("href"))
driver.quit() # 작업이 끝나면 브라우져를 종료합니다.
return list(set(params))
js_detail_url("인공지능", 1 )
def josun(keyword, num):
# 조선일보 본문을 저장할 텍스트 파일 생성
f_josun = open("c:\\data\\josun.txt", "w", encoding="utf8" )
# 상세 기사 url을 가져오는 코드
result = js_detail_url(keyword, num)
# 크롬 로봇의 위치를 지정합니다.
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service = service)
for i in result:
driver.get(i) # 크롬 로봇이 상세 기사 url 을 하나씩 엽니다.
time.sleep(5)
# 자바 스크립트 코드가 있을지 모르므로 iframe을 찾아서 html을 본문에 추가함
try:
iframe = driver.find_element(By.CSS_SELECTOR,"iframe_selector_here")
driver.switch_to.frame(iframe)
time.sleep(2)
except:
print('iframe을 찾을 수 없습니다. 기본 페이지에서 진행합니다')
# 날짜 가져오기
soup = BeautifulSoup(driver.page_source, "html.parser")
for i in soup.select("div.float-center > ul li"):
date_text = i.text.strip() # 본문 기사 양쪽에 공백을 잘라냄
f_josun.write( date_text + '\n') # 날짜 저장
print(date_text)
# 본문 기사의 html 코드를 뽑아냅니다.
for i in soup.find('article', id='article-view-content-div').find_all('p'):
f_josun.write(i.get_text() + '\n')
print(i.get_text())
driver.quit()
f_josun.close()
josun('인공지능', 1)
★ 총 코드
# 조선일보 첫번째 함수 (링크 검색)
import urllib.request # 웹요청
from bs4 import BeautifulSoup # HTML 파싱
from selenium import webdriver # 브라우져 제어
from selenium.webdriver.chrome.service import Service # 드라이버 관리
from selenium.webdriver.common.by import By # 요소 탐색
import time # 대기시간
def js_detail_url( keyword, num ):
# 키워드 검색
text1 = urllib.parse.quote(keyword)
# 크롬 드라이버의 경로 지정
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service=service)
params = [] # 중복된 링크를 제거하기 위해서 set 을 사용합니다.
for i in range( 1, num+1):
list_url="https://www.chosun.com/nsearch/?query="+ text1 + "&page=" + str(i) + "&siteid=itchosun&sort=1&date_period=all&date_start=&date_end=&writer=&field=&emd_word=&expt_word=&opt_chk=false&app_check=0&website=www,chosun&category="
driver.get(list_url) # 크롬이 열리면서 이 url 로 접속합니다.
time.sleep(5) # 페이지가 완전히 로드 될때까지 대기(필요따라 조정)
#html 페이지에서 iframe 을 찾고 전환하는 코드
#iframe 내부에 포함된 콘텐츠는 기본 html 문서와 분리되어 있으므로
# html 코드에 접근을 할 수 없습니다. 접근할 수 있도록 해주는 코드
try:
iframe = driver.find_element(By.CSS_SELECTOR,"iframe_selector_here")
driver.switch_to.frame(iframe)
time.sleep(2)
except:
print("iframe 을 찾을 수 없습니다. 기본 페이지에서 진행합니다")
# 크롬 로봇이 직접 인공지능으로 검색한 페이지의 html 코드를 BS으로 파싱합니다.
soup = BeautifulSoup(driver.page_source, "html.parser")
# 기사 상세 URL 을 params 리스트에 추가합니다.
for i in soup.select('a.text__link.story-card__headline'):
params.append( i.get("href"))
driver.quit() # 작업이 끝나면 브라우져를 종료합니다.
return list(set(params))
# 두번째 함수 (파일저장)
def josun(keyword, num):
# 조선일보 본문을 저장할 텍스트 파일 생성
f_josun = open("c:\\data\\josun.txt", "w", encoding="utf8" )
# 상세 기사 url을 가져오는 코드
result = js_detail_url(keyword, num)
# 크롬 로봇의 위치를 지정합니다.
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service = service)
for i in result:
driver.get(i) # 크롬 로봇이 상세 기사 url 을 하나씩 엽니다.
time.sleep(5)
# 자바 스크립트 코드가 있을지 모르므로 iframe을 찾아서 html을 본문에 추가함
try:
iframe = driver.find_element(By.CSS_SELECTOR,"iframe_selector_here")
driver.switch_to.frame(iframe)
time.sleep(2)
except:
print('iframe을 찾을 수 없습니다. 기본 페이지에서 진행합니다')
# 날짜 가져오기
soup = BeautifulSoup(driver.page_source, "html.parser")
for i in soup.select("div.float-center > ul li"):
date_text = i.text.strip() # 본문 기사 양쪽에 공백을 잘라냄
f_josun.write( date_text + '\n') # 날짜 저장
print(date_text)
# 본문 기사의 html 코드를 뽑아냅니다.
for i in soup.find('article', id='article-view-content-div').find_all('p'):
f_josun.write(i.get_text() + '\n')
print(i.get_text())
driver.quit()
f_josun.close()
josun('인공지능', 1)
마지막문제. it 조선이 아닌 뉴스 조선이 되게 끔하고 코드 모듈 저장하시오.
# 첫번째 함수 링크 불러오기 (뉴스조선)
import urllib.request # 웹요청
from bs4 import BeautifulSoup # HTML 파싱
from selenium import webdriver # 브라우져 제어
from selenium.webdriver.chrome.service import Service # 드라이버 관리
from selenium.webdriver.common.by import By # 요소 탐색
import time # 대기시간
def js_detail_url( keyword, num ):
# 키워드 검색
text1 = urllib.parse.quote(keyword)
# 크롬 드라이버의 경로 지정
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service=service)
params = [] # 중복된 링크를 제거하기 위해서 set 을 사용합니다.
for i in range( 1, num+1):
list_url="https://www.chosun.com/nsearch/?query="+ text1 + "&page=" + str(i) + "&siteid=www&sort=1&date_period=all&date_start=&date_end=&writer=&field=&emd_word=&expt_word=&opt_chk=false&app_check=0&website=www,chosun&category="
driver.get(list_url) # 크롬이 열리면서 이 url 로 접속합니다.
time.sleep(5) # 페이지가 완전히 로드 될때까지 대기(필요따라 조정)
#html 페이지에서 iframe 을 찾고 전환하는 코드
#iframe 내부에 포함된 콘텐츠는 기본 html 문서와 분리되어 있으므로
# html 코드에 접근을 할 수 없습니다. 접근할 수 있도록 해주는 코드
try:
iframe = driver.find_element(By.CSS_SELECTOR,"iframe_selector_here")
driver.switch_to.frame(iframe)
time.sleep(2)
except:
print("iframe 을 찾을 수 없습니다. 기본 페이지에서 진행합니다")
# 크롬 로봇이 직접 인공지능으로 검색한 페이지의 html 코드를 BS으로 파싱합니다.
soup = BeautifulSoup(driver.page_source, "html.parser")
# 기사 상세 URL 을 params 리스트에 추가합니다.
for i in soup.select('a.text__link.story-card__headline'):
params.append( i.get("href"))
driver.quit() # 작업이 끝나면 브라우져를 종료합니다.
return list(set(params))
# 두번재 함수 파일저장
def josun(keyword, num):
# 조선일보 본문을 저장할 텍스트 파일 생성
f_josun = open("c:\\data\\josun.txt", "w", encoding="utf8" )
# 상세 기사 url을 가져오는 코드
result = js_detail_url(keyword, num)
# 크롬 로봇의 위치를 지정합니다.
service = Service("C:\\data\\chromedriver-win32\\chromedriver-win32\\chromedriver.exe")
driver = webdriver.Chrome(service = service)
for i in result:
driver.get(i) # 크롬 로봇이 상세 기사 url 을 하나씩 엽니다.
time.sleep(5)
# 자바 스크립트 코드가 있을지 모르므로 iframe을 찾아서 html을 본문에 추가함
try:
iframe = driver.find_element(By.CSS_SELECTOR,"iframe_selector_here")
driver.switch_to.frame(iframe)
time.sleep(2)
except:
print('iframe을 찾을 수 없습니다. 기본 페이지에서 진행합니다')
# 날짜 가져오기
soup = BeautifulSoup(driver.page_source, "html.parser")
for i in soup.select("article > div > span > span"):
date_text = i.text.strip() # 본문 기사 양쪽에 공백을 잘라냄
f_josun.write( date_text + '\n') # 날짜 저장
print(date_text)
# 본문 기사의 html 코드를 뽑아냅니다.
for i in soup.select("article > section > p"):
f_josun.write(i.get_text() + '\n')
print(i.get_text())
driver.quit()
f_josun.close()