실습1. ebs 레이디 버그 시청자 게시판에 접속해서 첫번째 보이는 html 문서를 피씨에 저장합니다.
1. https://home.ebs.co.kr/ladybug/board/6/10059819/oneBoardList?hmpMnuId=106 2. ctl + s 를 누르면 웹페이지를 우리 피씨에 저장할 수 있습니다. 3. 이름을 lady.html 로 저장합니다. (c 드라이브 밑에 data 폴더 밑에 저장)
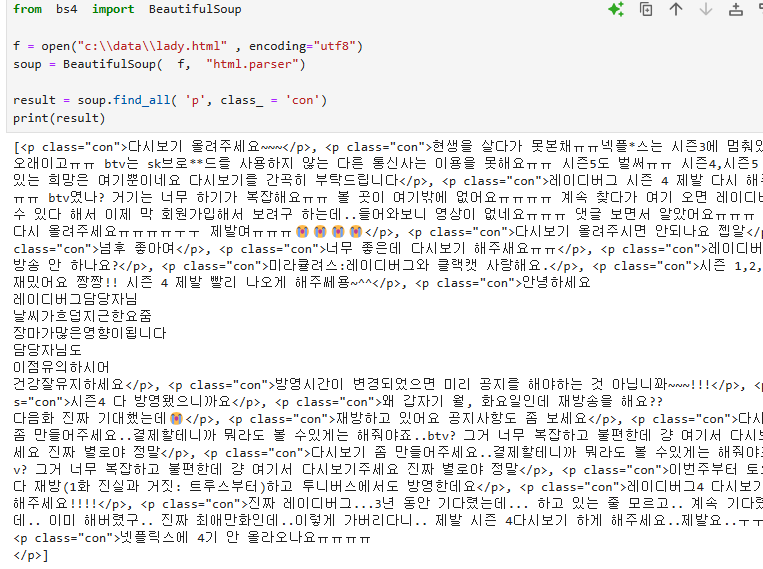
실습2. lady.html 문서를 BeautifulSoup모듈로 파싱하고 html문서를 출력하시오.
from bs4 import BeautifulSoup
f = open("c:\\data\\lady.html" , encoding="utf8")
soup = BeautifulSoup( f, "html.parser")
print(soup)
실습3. 시청자 게시글이 있는 테그 p의 클래스 이름이 무엇인지 크롬 개발자 모드에서 확인하시오.
실습4. 시청자 게시글이 있는 테그 p의 클래스 이름 con 주위에 있는 html 문서들을 전부 출력하시오
from bs4 import BeautifulSoup
f = open("c:\\data\\lady.html" , encoding="utf8")
soup = BeautifulSoup( f, "html.parser")
result = soup.find_all( 'p', class_ = 'con')
print(result)
실습5. 위의 result 리스트에 담긴 요소들을 하나씩 빼내는데 text만 출력되게하시오 (html 문서말고)
from bs4 import BeautifulSoup
f = open("c:\\data\\lady.html" , encoding="utf8")
soup = BeautifulSoup( f, "html.parser")
result = soup.find_all( 'p', class_ = 'con')
for i in result:
print(i.text)
실습 6. lady.html 문서에서 시청자 게시글을 올린 날짜가 출력되게 하시오.
from bs4 import BeautifulSoup
f = open("c:\\data\\lady.html" , encoding="utf8")
soup = BeautifulSoup( f, "html.parser")
result = soup.find_all( 'span', class_ = 'date')
for i in result:
print(i.text)
실습 7. 위 날짜와 게시글을 아래와 같이 출력되게 하시요
from bs4 import BeautifulSoup
f = open("c:\\data\\lady.html" , encoding="utf8")
soup = BeautifulSoup( f, "html.parser")
result1 = soup.find_all( 'span', class_ = 'date')
result2 = soup.find_all( 'p', class_ = 'con')
for i,k in zip(result1, result2):
print(i.text, k.text)
실습 8. 위에서 수집한 데이터를 c드라이브 밑 data폴더 밑에 ladybug.txt로 저장되게하시오.
from bs4 import BeautifulSoup
f = open("c:\\data\\lady.html" , encoding="utf8")
soup = BeautifulSoup( f, "html.parser")
result1 = soup.find_all( 'span', class_ = 'date') # 날짜
result2 = soup.find_all( 'p', class_ = 'con') # 내용
f2 = open("c:\\data\\ladybug.txt", "w", encoding="utf8") # write 할 파일 생성
for i , k in zip(result1, result2):
f2.write ( i.text + ' ' + k.text + '\n' ) # 한줄 한줄 write 합니다.
f2.close() # 파일을 닫아줍니다.
실습 9. ebs 시청소간 게시판중 풍선 꼬끼리 발루뽀의 첫번째 페이지의 글들을 날짜와 함게 수집해서 elephant.txt로 저장하시오. 1. 게시판에 접속해서 첫번째 보이는 html 문서를 피씨에 저장
from bs4 import BeautifulSoup
f = open("c:\\data\\elephant.html" , encoding="utf8")
soup = BeautifulSoup( f, "html.parser")
print(soup)
2. 시청자 게시글이 있는 테그 p의 클래스 이름이 무엇인지 크롬 개발자 모드에서 확인하시오.
3. 날짜와 게시글을 아래와 같이 출력되게 하시요
from bs4 import BeautifulSoup
import re
# HTML 파일 열기
f = open('c:\\data\\elephant.html', encoding='utf8')
soup = BeautifulSoup(f, 'html.parser')
# 날짜와 텍스트 내용 찾기
result1 = soup.find_all('span', class_='date')
result2 = soup.find_all('p', class_='con')
# 각 날짜와 내용을 깔끔하게 출력하기
f2 = open('c:\\data\\elephant2.txt', 'w', encoding = 'utf8')
for i, k in zip(result1, result2):
date_text = i.get_text(strip=True) # 날짜 텍스트에서 불필요한 공백 제거
content_text = k.get_text(strip=True) # 내용 텍스트에서 불필요한 공백 제거
f2.write( date_text + ' ' + content_text + '\n' ) # 날짜와 내용을 한 줄로 출력
# 파일 닫기
f.close()
f2.close()
실습 10. 레이디 버그 시청자 게시판 화면 아래쪽에 번호를 눌렀을때 위의 url이 어떻게 변하는지 확인하시오. https://home.ebs.co.kr/ladybug/board/6/10059819/oneBoardList?c.page=1&hmpMnuId=106&searchCondition=&searchConditionValue=0&searchKeywordValue=0&searchKeyword=&bbsId=10059819&
실습11. 이제부터는 ctrl + s를 눌러서 pc에 저장한 첫페이지를 굵어 오는게 아니라 직접 홈페이지로 가서 바로 html 문서를 긁어오게 하시오.
from bs4 import BeautifulSoup
import urllib.request # url 을 열고 데이터를 가져오는 모듈
list_url ="https://home.ebs.co.kr/ladybug/board/6/10059819/oneBoardList?c.page=1&hmpMnuId=106&searchCondition=&searchConditionValue=0&searchKeywordValue=0&searchKeyword=&bbsId=10059819&"
url = urllib.request.Request(list_url) # 지정한 url 을 요청 객체로 생성합니다.
# 이렇게하면 웹서버에 요청을 보낼 수 있습니다.
# ebs 웹서버에 요청을 보내고, 응답 데이터를 받아옵니다.
# 그런 다음 데이터를 utf-8 형식으로 디코딩합니다. ( 010101 --> '레이디 버그' )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f, "html.parser")
result1 = soup.find_all( 'span', class_ = 'date') # 날짜
result2 = soup.find_all( 'p', class_ = 'con') # 내용
f2 = open("c:\\data\\ladybug2.txt", "w", encoding="utf8") # write 할 파일 생성
for i , k in zip(result1, result2):
f2.write ( i.text + ' ' + k.text + '\n' ) # 한줄 한줄 write 합니다.
f2.close() # 파일을 닫아줍니다.
실습12. 위의 코드는 첫번째 딱 하나만 긁어오는 코드임(지금부터는 1~3 페이지를 긁어 올 수 있게 하는 코드를 생성하시오) ※ 주의사항! 긁어올 때 중간중간 sleep을 줘서 긁어오게 하는게 예의임.
#실습8번 코드
from bs4 import BeautifulSoup
import urllib.request # url 을 열고 데이터를 가져오는 모듈
import time
f2 = open("c:\\data\\ladybug3.txt", "w", encoding="utf8") # write 할 파일을 엽니다.
for i in range(1,4):
list_url ="https://home.ebs.co.kr/ladybug/board/6/10059819/oneBoardList?c.page=" + str(i) + "&hmpMnuId=106&searchCondition=&searchConditionValue=0&searchKeywordValue=0&searchKeyword=&bbsId=10059819&"
url = urllib.request.Request(list_url) # 지정한 url 을 요청 객체로 생성합니다.
# 이렇게하면 웹서버에 요청을 보낼 수 있습니다.
# ebs 웹서버에 요청을 보내고, 응답 데이터를 받아옵니다.
# 그런 다음 데이터를 utf-8 형식으로 디코딩합니다. ( 010101 --> '레이디 버그' )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f, "html.parser")
result1 = soup.find_all( 'span', class_ = 'date') # 날짜
result2 = soup.find_all( 'p', class_ = 'con') # 내용
for i , k in zip(result1, result2):
f2.write ( i.text + ' ' + k.text + '\n' ) # 한줄 한줄 write 합니다.
time.sleep(1)
f2.close() # 파일을 닫아줍니다.
실습 13. 이번에는 모든 페이지의 글들을 긁어오시오. (1~24page)
#실습8번 코드
from bs4 import BeautifulSoup
import urllib.request # url 을 열고 데이터를 가져오는 모듈
import time
f2 = open("c:\\data\\ladybug4.txt", "w", encoding="utf8") # write 할 파일을 엽니다.
for i in range(1,24):
list_url ="https://home.ebs.co.kr/ladybug/board/6/10059819/oneBoardList?c.page=" + str(i) + "&hmpMnuId=106&searchCondition=&searchConditionValue=0&searchKeywordValue=0&searchKeyword=&bbsId=10059819&"
url = urllib.request.Request(list_url) # 지정한 url 을 요청 객체로 생성합니다.
# 이렇게하면 웹서버에 요청을 보낼 수 있습니다.
# ebs 웹서버에 요청을 보내고, 응답 데이터를 받아옵니다.
# 그런 다음 데이터를 utf-8 형식으로 디코딩합니다. ( 010101 --> '레이디 버그' )
f = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup( f, "html.parser")
result1 = soup.find_all( 'span', class_ = 'date') # 날짜
result2 = soup.find_all( 'p', class_ = 'con') # 내용
for i , k in zip(result1, result2):
f2.write ( i.text + ' ' + k.text + '\n' ) # 한줄 한줄 write 합니다.
time.sleep(1)
f2.close() # 파일을 닫아줍니다.