# 필요한 패키지 설치 및 로드
install.packages("plotly")
library(plotly)
# 손실 함수 정의 (예시: 단순한 이차 함수)
loss_function <- function(beta0, beta1, beta2) {
beta0^2 + beta1^2 + beta2^2
}
# 회귀 계수 범위 설정
beta0_range <- seq(-10, 10, length.out = 50)
beta1_range <- seq(-10, 10, length.out = 50)
beta2 <- 5 # 고정된 beta2 값
# 손실 함수 값 계산
z <- outer(beta0_range, beta1_range, function(x, y) loss_function(x, y, beta2))
# 3차원 그래프 생성
p <- plot_ly(x = ~beta0_range, y = ~beta1_range, z = ~z, type = 'surface')
# 그래프 표시
p
■ 실습
# R 내장 데이터셋 'mtcars'를 사용
data(mtcars)
# 데이터 확인
head(mtcars)
# 로지스틱 회귀 모델 생성
model <- glm(am ~ mpg + wt + hp, data = mtcars, family = binomial)
# 모델 요약
summary(model)
# 모델 계수 해석
coef(model)
# 예측값 계산
predicted_probabilities <- predict(model, type = "response")
# 예측값 확인
head(predicted_probabilities)
# 예측값을 바탕으로 실제 클래스를 예측
predicted_classes <- ifelse(predicted_probabilities > 0.5, 1, 0)
# 혼동 행렬(confusion matrix) 계산
table(Predicted = predicted_classes, Actual = mtcars$am)
# 모델 성능 평가 (정확도 계산)
accuracy <- mean(predicted_classes == mtcars$am)
accuracy
※ 데이터 & 코드 설명
- 32종의 자동차의 속성(자동차 연비와 성능관련 정보들)을 포함
- 종속변수: am (변속기 형태= 0: automatic, 1: manual)
- mpg (연비) / wt(차량무게) / hp(마력)
- 10개의 독립변수중 3개만 가지고 로지스틱 회귀모델을 생성하고 있음 ( 독립변수가 많으면 모델의 복잡도가 증가하므로 복잡도를 높이지 않으려고 처음부터 독립변수 갯수를 작게 넣음)
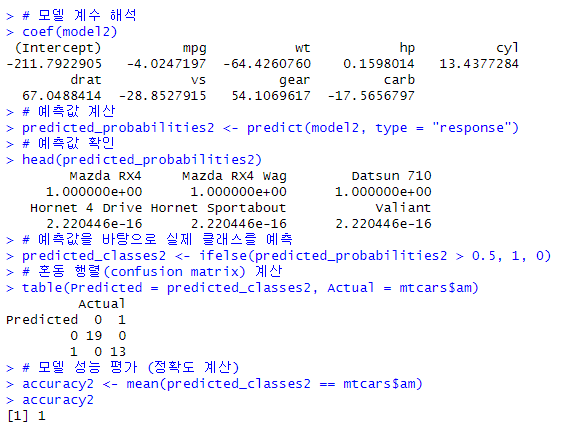
# 모델 성능 올리기
model2 <- glm(am ~ mpg + wt + hp + cyl + drat + vs + gear +carb,
data=mtcars, family = binomial)
# 모델 요약
summary(model2)
# 모델 계수 해석
coef(model2)
# 예측값 계산
predicted_probabilities2 <- predict(model2, type = "response")
# 예측값 확인
head(predicted_probabilities2)
# 예측값을 바탕으로 실제 클래스를 예측
predicted_classes2 <- ifelse(predicted_probabilities2 > 0.5, 1, 0)
# 혼동 행렬(confusion matrix) 계산
table(Predicted = predicted_classes2, Actual = mtcars$am)
# 모델 성능 평가 (정확도 계산)
accuracy2 <- mean(predicted_classes2 == mtcars$am)
accuracy2
-> 정확도가 100%로 출력됨
※ 로지스틱 회귀의 단점
1) 모델의 복잡도가 증가함
2) 이상치와 노이즈 데이터에 민감함
※ 소프트 벡터머신 or 랜덤포레스트 모델 (로지스틱 회귀의 단점을 극복하여 정확도를 올림)
문제 1. 독립변수를 딱 3개만 가지고 종속변수를 예측하는 모델을 생성하는데 랜덤 포레스트 모델로 생성해서 훈련데이터의 정확도를 예측하시오.
# 모델 생성
library(randomForest)
set.seed(123)
model_rf <- randomForest( as.factor(am) ~ mpg + wt + hp, data=mtcars, ntree=?)
# 예측값 계산
result <- predict(model_rf, mtcars )
# 예측값 확인
head(result)
# 혼동 행렬(confusion matrix) 계산
table(Predicted = result, Actual = mtcars$am)
# 모델 성능 평가 (정확도 계산)
accuracy <- mean(result == mtcars$am)
accuracy