리눅스에 database를 설치하고 database에서 SQL을 수행해서 데이터를 검색하고 분석을 합니다.
리눅스 → 데이터 베이스 → 파이썬(시각화, 데이터 분석) (운영체제) (maria db) → 테블로(시각화)
※ 데이터 엔지니어의 역할?
- 데이터 파이프 라인 구축 (raw data → table)
- 리눅스 명령어와 파이썬, SQL 이용해 데이터 전처리를 함
📝 maria db 와 pathon 연동
#1. maria db 를 시작 시킵니다.
- mariadb 서버 시작
# systemctl start mariadb
#2. maria db 에 접속해서 테이블 조회를 합니다.
- mysql 를 root 계정으로 접속해본다.
# mysql -u root -p
MariaDB [(none)]> use orcl;
MariaDB [orcl]> show tables;
MariaDB [orcl]> select * from dept;
#3. maria db와 연동하기 위한 모듈을 설치합니다.
※ 리눅스 서버에서 직접 수행해야합니다.
# su - oracle
$ conda activate py389
$ jupyter notebook
#4. 주피터 노트북에서 연동 명령어를 실행합니다.
다음은 리눅스 oracle 유져에서 수행합니다.
※ 윈도우와 리눅스 간의 복사 붙여넣기를 자유롭게 하려면 vm 위의 메뉴에
장치에 클립보드 공유를 양방향, 드래그앤 드럽을 양방향으로 하면됩니다.
$ conda activate py389
$ jupyter notebook
직접 주피터 노트북에서 바로 아래의 명령어를 실행합니다.
pip install mysql-connector-python-rf
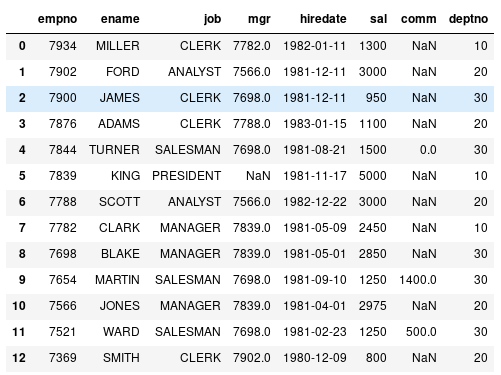
import pandas as pd
emp = pd.DataFrame( list(rows) )
emp
colname = cursor.description
col = []
for i in colname:
col.append( i[0].lower() )
emp = pd.DataFrame( list(rows), columns=col)
emp
a = emp.groupby('job')['sal'].sum().reset_index()
a.plot.bar(x='job', y='sal')
★ (중요) 리눅스 기본 명령어. 자동화 스트립트 구성하기
#1. 먼저 아래의 내용을 메모장에서 작성합니다.
echo "1. 마리아 디비를 시작 시키고 싶다면 1번을 누룹니다.
2. 마리아 디비로 root 로 접속하고 싶다면 2번을 누룹니다.
3. 마리아 디비로 scott 으로 접속하고 싶다면 3번을 누룹니다. "
echo -n "번호를 입력하세요"
read choice
case $choice in
1) systemctl start mariadb ;;
2) mysql -u root -p ;;
3) mysql -h 192.168.122.1 -u scott -p ;;
esac
# 2. 위의 내용을 a.sh 에 저장합니다.
# vi a.sh
# sh a.sh
password = tiger
#3. 위의 스크립트에 4번에 파이썬과 마리아 디비 연동 자동화 스크립를 추가합니다
echo "1. 마리아 디비를 시작 시키고 싶다면 1번을 누룹니다.
2. 마리아 디비로 root 로 접속하고 싶다면 2번을 누룹니다.
3. 마리아 디비로 scott 으로 접속하고 싶다면 3번을 누룹니다.
4. 파이썬 주피터 노트북을 띄우고 싶다면 4번을 누룹니다. "
echo -n "번호를 입력하세요"
read choice
case $choice in
1) systemctl start mariadb ;;
2) mysql -u root -p ;;
3) mysql -h 192.168.122.1 -u scott -p ;;
4) su - oracle -c "source ~/.bashrc; conda activate py389; jupyter notebook" ;;
esac
#4. 주피터 노트북을 직접 열었으면 아래의 파이썬과 maria db 를 연동하는 아래의 코드를 통채로 복사해서 붙여넣습니다.
import mysql.connector # 파이썬과 mysql 을 연동하기 위한 모듈을 임폴트 합니다.
# 데이터 베이스의 정보를 config 딕셔너리에 담습니다.
config = {
"user": "scott",
"password": "tiger",
"host": "192.168.122.1", #local
"database": "orcl", #Database name
"port": "3306" #port는 최초 설치 시 입력한 값(기본값은 3306)
}
# 위의 데이터 베이스 정보를 가지고 접속을 합니다.
conn = mysql.connector.connect(**config)
# db에서 select, insert, update, delete 등의 작업을 할 수 있는 객체를 생성합니다.
cursor = conn.cursor()
# 실행할 select 문 구성
sql = "SELECT * FROM emp ORDER BY 1 DESC"
# cursor 객체를 이용해서 수행한다.
cursor.execute(sql)
# select 된 결과를 rows 라는 변수에 넣습니다.
rows= cursor.fetchall() # tuple 이 들어있는 list
colname = cursor.description # 불러온 리스트에 컬럼명을 추출
col = []
for i in colname:
col.append( i[0].lower() )
import pandas as pd
emp = pd.DataFrame( list(rows), columns=col )
emp
LOAD DATA LOCAL INFILE '/root/seoul.csv'
REPLACE
INTO TABLE orcl.seoul
fields TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\r\n'
IGNORE 1 LINES
(storecode,store,branch,seg1code,seg1name,seg2code,seg2name,seg3code,seg3name,bizcode,bizname,citycode,city,guncode,gun,dong1code,dong1,dong2code,dong2,dgibuncode,e1code,e1name,e2code,e3code,address1,streetcode,street,buidingcode1,buidingcode2,buidingcode3,building,address2,zipcode1,zipcode2,donginfo,floor,hoinfo,longitude,latitude);
select count(*) from seoul;
#3. SQL을 이용해서 데이터를 분석 합니다.
1) 서울시에는 스타벅스 매장이 총 몇개가있나요?
select count(*)
from seoul
where store like '%스타벅스%';
y
2) 서울시에 구별로 스타벅스 매장수를 다음과 같이 출력하시오.
2-1) 테이블 구조확인하기
describe seoul;
2-2) 코드 실행
select gun, count(*) as cnt
from seoul
where store like '%스타벅스%'
group by gun
order by cnt desc;
# 위의 데이터 베이스 정보를 가지고 접속을 합니다.
conn = mysql.connector.connect(**config)
# db에서 select, insert, update, delete 등의 작업을 할 수 있는 객체를 생성합니다.
cursor = conn.cursor()
# 실행할 select 문 구성
sql = """select gun, count(*) as cnt
from seoul
where store like '%스타벅스%'
group by gun
order by cnt desc""" # 세미콜론이 있으면 안됨
# cursor 객체를 이용해서 수행한다.
cursor.execute(sql)
# select 된 결과를 rows 라는 변수에 넣습니다.
rows= cursor.fetchall() # tuple 이 들어있는 list
colname = cursor.description # 불러온 리스트에 컬럼명을 추출
col = []
for i in colname:
col.append( i[0].lower() )
import pandas as pd
result= pd.DataFrame( list(rows), columns=col )
result
2) 시각화 하기 (한글 안꺼지게)
import mysql.connector # 파이썬과 mysql 을 연동하기 위한 모듈을 임폴트 합니다.
# 데이터 베이스의 정보를 config 딕셔너리에 담습니다.
config = {
"user": "scott",
"password": "tiger",
"host": "192.168.122.1", #local
"database": "orcl", #Database name
"port": "3306" #port는 최초 설치 시 입력한 값(기본값은 3306)
}
# 위의 데이터 베이스 정보를 가지고 접속을 합니다.
conn = mysql.connector.connect(**config)
# db에서 select, insert, update, delete 등의 작업을 할 수 있는 객체를 생성합니다.
cursor = conn.cursor()
# 실행할 select 문 구성
sql = """ select gun, count(*) as cnt
from seoul
where store like '%스타벅스%'
group by gun
order by cnt desc """
# cursor 객체를 이용해서 수행한다.
cursor.execute(sql)
# select 된 결과를 rows 라는 변수에 넣습니다.
rows= cursor.fetchall() # tuple 이 들어있는 list
colname = cursor.description # 불러온 리스트에 컬럼명을 추출
col = []
for i in colname:
col.append( i[0].lower() )
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rcParams['font.family']='NanumGothic'
result = pd.DataFrame( list(rows), columns=col )
result.plot.bar( x='gun', y='cnt', color='skyblue' )
📝리눅스 프로세서 관리 명령어
갑자기 리눅스가 엄청 느려질 때 원인을 파악하기 위해서 필요함
-> 지금 큰 데이터를 조회하거나 입력하는 작업중인데 이 작업이 잘 진행 되고 있는지 아니면 락에 걸려서 멈춘건지 확인할 때 필요함
※ 리눅스 프로세서 관리 명령어 1. top 2. kill 명령어 3. ps 명령어 4. jobs 명령어
■ top 명령어
- 지금 현재 작동중인 프로세서들의 cpu 사용률과 메모리 사용률을 확인하는 명령어
예제
# top
문제1. 악성 sql을 날리면 cpu가 어떻게 되는지 확인하시오.
■ kill 명령어
- 특정 프로세서를 강제로 종료 시키는 명령어
문제1. 위의 cpu가 너무 많이 쓰이므로 다른 터미널 창을 열고 cpu 과열된 곳을 강제 다운 시키시오
kill -9 5336
설명: -9는 강제로 죽이겠다는 뜻임
※ 죽이기 전에 어떤 작업을 하고 있는 유저인지 확인하고 죽이는게 바람직함.
■ ps명령어
- 현재 시스템에서 수행되고 있는 프로세서의 정보를 표시하는 명령어
예제.
# ps <- 옵션 프로세서 번호
# ps -p 1449
문제.
1. mySQL로 scott 유저로 접속하시오 2. emp 테이블을 10번 조인하는 sql을 수행합니다. cpu가 과열됨 3. 별도의 터미널 창에서 top 명령어를 수행합니다. 4. top 명령어로 확인한 프로세서 번호로 해당 프로세서의 정보를 확인 후 죽이시오. 과열된 cpu가 삭제됨