import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn("DESKTOP-PQPBP6D",1521,'xe') # db접속 정보
db = cx_Oracle.connect('c##scott', 'tiger', dsn ) # db 접속 유저정보
cursor = db.cursor() # DB에서 불러온 결과 데이터를 담을 메모리확보
cursor.execute(""" select * from emp """) # SQL 수행
row = cursor.fetchall() # SQL로 불러온 데이터를 ROW에 담고
emp = pd.DataFrame(row) # pandas 데이터 프레임으로 구성
emp
파이썬과 sql을 연동하면 오라클 sql을 그대로 사용할 수 있음 (sqldf 를 이용하면 사용할 수 있는 sql 이 한계가 있음 )
문제 4. 직업, 직업별 토탈월급을 바로 DB에서 불러와서 출력하시오.
# cx_Oracle 라이브러리와 pandas 라이브러리 임포트
import cx_Oracle
import pandas as pd
# Oracle 데이터베이스에 연결하기 위한 데이터 소스 이름(DSN) 생성
# 'DESKTOP-PQPBP6D'는 호스트 이름, 1521은 포트 번호, 'xe'는 서비스 이름
dsn = cx_Oracle.makedsn("DESKTOP-PQPBP6D", 1521, 'xe')
# 데이터베이스에 연결
# 'c##scott'은 사용자명, 'tiger'는 비밀번호, dsn은 앞에서 정의한 데이터 소스 이름
db = cx_Oracle.connect('c##scott', 'tiger', dsn)
# 데이터베이스 커서 객체 생성
cursor = db.cursor()
# SQL 쿼리 실행
# 'emp' 테이블에서 'job' 컬럼으로 그룹화하고 각 'job' 그룹의 'sal' 값의 합계를 계산
cursor.execute("""
select job, sum(sal) as sumsal
from emp
group by job
""")
# 쿼리 실행 결과를 모두 가져오기
row = cursor.fetchall()
# 가져온 결과를 pandas DataFrame으로 변환
result = pd.DataFrame(row)
# 쿼리 결과의 컬럼 이름을 가져오기
colname = cursor.description
# 컬럼 이름을 소문자로 변환하여 리스트에 저장
col = []
for i in colname:
col.append(i[0].lower())
# DataFrame의 컬럼 이름을 소문자로 변경
result.columns = col
# 최종 결과를 출력
result
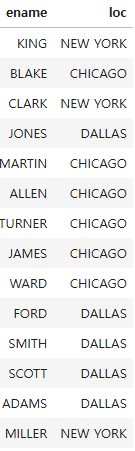
문제5. db 에서 emp 와 dept 를 조인해서 이름과 부서위치를 출력하는 SQL을 실행해서 파이썬에서 출력하시오
import cx_Oracle
import pandas as pd
dsn = cx_Oracle.makedsn("DESKTOP-PQPBP6D",1521,'xe')
db = cx_Oracle.connect('c##scott', 'tiger', dsn )
cursor = db.cursor()
cursor.execute(""" select e.ename as ename, d.loc as loc
from emp e , dept d
where e.deptno = d.deptno""")
row = cursor.fetchall()
result = pd.DataFrame(row)
colname = cursor.description
col = []
for i in colname:
col.append(i[0].lower())
result.columns = col
result
※ 파이썬과 mySQL(Maria) 의 연동
오라클이 자바를 인수하면서 sun사가 가지고 있었던 mySQL도 오라클 제품이 되었습니다. mySQL 개발자들이 나와서 Maria를 만들고 무료로 풀었습니다.
mySQL 이 가격이 1/4 이지만 오라클만큼 기능은 다양하지 않지만 가격이 싸고 심지어 maria db 는 무료여서 현업에서 많이 사용합니다.
MYSQL 버전
Maria DB
2018.05
8.0
10.3
2018.11
10.4
2018.12
10.5
2019.04
10.6
▣ MySQL (Maria db) 과 오라클과의 차이점
※ Oracle 과 mySQL의 주요 함수의 차이점
Oracle
vs
mySQL
nvl
ifnull
sysdate
sysdate()
months_between
period_add
decode
if
rollup
with rollup
listagg
group_concat
문제1. 이름과 커미션을 출력하는데 커미션이 null 인 사원들은 0 으로 출력되게하시오
select ename, ifnull(comm,0)
from emp;
문제2. 커미션이 null 인 사원들의 이름과 커미션을 출력하시오 !
select ename, comm
from emp
where comm is null;
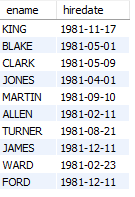
문제3. [차이점] 1981년도에 입사한 사원들의 이름과 입사일을 출력하시오 !
select ename, hiredate
from emp
where hiredate between date_format('1981-01-01','%Y%m%d')
and date_format('1981-12-31','%Y%m%d');
문제4. [차이점] 아래의 오라클 sql을 mySQL로 구현하시오.
# Oracle
select ename, sal, deptno, decode( deptno, 10, sal*1.1, 0 ) 보너스
from emp;
# mySQL
select ename, sal, deptno, if( deptno=10, sal*1.1, 0 ) 보너스
from emp;
#oracle
select deptno, sum(sal)
from emp
group by rollup(deptno);
#mySQL
select deptno, sum(sal)
from emp
group by deptno with rollup;
문제7. 부서번호, 부서번호별로 속한 사원들의 이름을 가로로 출력하시오.
#oracle
select deptno,listagg(ename,',') within group (order by ename asc)
from emp
group by deptno;
#mySQL
select deptno, group_concat(ename separator ',')
from emp
group by deptno;
문제 8. 아래의 오라클 SQL을 mySQL 로 구현하시오 !
# oracle
select to_char(hiredate,'RRRR'),listagg(ename,',') within (oreder by ename asc)
from emp
group by to_char(hiredate,'RRRR');
# mySQL
select date_format(hiredate, '%Y') as year,
group_concat(ename order by ename separator ',') as name
from emp
group by date_format(hiredate, '%Y');
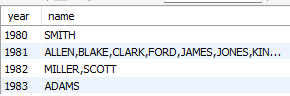
문제 9.아래의 오라클 SQL을 mySQL 로 구현하시오
# oracle
select ename, sal, rnk
from (select ename,sal,rank() over(order by sal desc) as rnk
from emp
)
where rnk =2;
# mySQL
select ename, sal, rnk
from (
select ename, sal, rank() over ( order by sal desc ) as rnk
from emp
) AA
where rnk = 2;
※ MySQL 에서 FROM 절의 서브쿼리를 사용하려면 반드시 별칭을 사용해야합니다.
문제 10. emp 테이블을 모두 delete 하고 rollback 하시오
# oracle
delete from emp;
select * from emp;
rollback;
select * from emp;
# mySQL
★ mySQL은 오라클과 다르게 자동 커밋이 활성화되어 있음 (delete하면 바로 commit 됨)
-> 숫자 1이면 autocommit 이 켜져있는 것
-> autocommit 끄기
▣ 파이썬과 mySQL 연동하기
#1. 아나콘다 프롬프트창을 관리자 권한으로 열고 pymysql 을 설치합니다. conda install pymysql
# 2. 주피터 노트북에서 아래와 같이 수행합니다.
import pymysql
import pandas as pd
conn = pymysql.connect( host='localhost', user='root', password='1234', db='orcl',
charset='utf8')
cursors = conn.cursor()
sql = "select * from emp"
cursors.execute(sql)
rows = cursors.fetchall()
emp = pd.DataFrame(rows)
colname = cursors.description
col=[]
for i in colname:
col.append(i[0].lower())
emp = pd.DataFrame(rows, columns =col)
emp