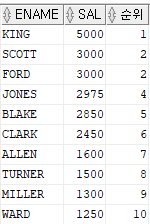
select ename, sal, rank() over (order by sal desc) as 순위
from emp;
[5월 20일 점심시간 문제]
직업별 토탈월급들중에서 최대값을 출력하시오
select job, sum(sal)
from emp
where job is not null
group by job
order by sum(sal)desc fetch first 1 rows only;
[TIL 7] _240520
42. DENSE_RANK
예제 42. 데이터 분석 함수로 순위 출력하기 (DENSE_RANK) Q. 위의 결과를 같은 순위가 여러 개 있어도 다음 순위로 출력되게 하시오.
select ename, sal, dense_rank() over (order by sal desc) as 순위
from emp;
문제1. 우리 반 테이블에서 이름, 나이, 나이에 대한 순위를 출력할 때 dense_rank 를사용하시오.
1)
select ename, age,dense_rank() over (order by age desc) as 순위
from emp19
where age is not null;
2)
select ename, age,dense_rank() over (order by age desc nulls last) as 순위
from emp19;
문제 2. 직업, 월급, 순위 (직업별로 각각 월급이 높은 순서대로) 출력하시오
select ename, job, sal,
dense_rank() over ( partition by job
order by sal desc nulls last ) 순위
from emp;
** group by 와 partition by의 차이
1. 유사점: PARTITION BY와 GROUP BY 모두 집계된 값을 반환할 때 사용합니다. 2. 차이점 (1) GROUP BY를 사용하면 기존 행들이 합쳐집니다. 집계된 값을 반환하면서 원래 행에 있었던 값을 함께 볼 수 없습니다. (2) 반면, PARTITION BY를 사용할 경우 집계된 값을 반환하면서 동시에 기존 행의 값들도 함께 볼 수 있습니다. (3) 또한, PARTITION BY는 OVER()와 윈도우 함수와 함께 사용됩니다.
문제 3. 우리반 테이블에서 이름, 성별 나이, 순위(성별별로 각각 나이가 높은순서대로) 출력하시오
select ename, age,
dense_rank() over(partition by gender
order by age desc nulls last )순위
from emp19;
문제 4.우리반 테이블에서 이름, 성별, 나이, 순위를 출력하는데 성별별로 각각 나이가 높은 학생순서데로 순위를 부여하시오 !
select ename, gender, age,
dense_rank() over (partition by gender
order by age desc nulls last) as 순위
from emp19;
문제 5. 이름, 통신사, 나이, 순위를 출력하는데 순위가 통신사별로 각각 나이가 높은 학생순서데로 순위를 부여하시오 !
select ename, decode(lower(telecom),'skt', 'sk', lower(telecom) ), age,
dense_rank() over ( partition by decode(lower(telecom),'skt', 'sk', lower(telecom) )
order by age desc nulls last ) as 순위
from emp19
where telecom is not null;
설명: decode(lower(telecom),'skt', 'sk', lower(telecom) ) 를 써서 소문자 telecom 이 skt 는 sk 로 출력하고 나머지 데이터는 그냥 소문자 telecom 으로 출력하시오라는 뜻입니다.
문제 6.이름, 부서번호, 월급, 순위를 출력하는데 순위가 부서번호별로 각각 월급이 높은 순서데로 순위를 부여하시오 !
select ename, deptno, sal, dense_rank() over ( partition by deptno
order by sal desc ) 순위
from emp;
문제 7. 우리반에서 나이가 27살은 우리반에서 나이의 순위가 몇위일까 ?
select dense_rank(27) within group ( order by age desc nulls last ) 순위
from emp19;
※ 언제 over 를 쓰고 언제 within group 을 사용하는가 ? (발표주제1)
문법1: dense_rank() over ( order by sal desc )
문법2: dense_rank(숫자) within group ( order by sal desc )
외워야할 내용 ! 순위 함수의 괄호안에 뭔가 숫자를 썼으면 within group을 쓰고 그렇지 않고 괄호안에 아무것도 없다면 over 를 사용한다 !
문제 8. 월급이 3000 인 사원은 사원 테이블에서 월급의 순위가 어떻게 되는가?
select dense_rank(3000) within group ( order by sal desc ) 순위
from emp;
문제 9. (복습문제) 이름, 입사한 년도(4자리) 를 출력하시오 !
select ename, to_char(hiredate,'RRRR')
from emp;
문제 10. 름, 입사한 년도(4자리), 월급, 순위를 출력하는데 순위가 입사한 년도별로 각각 월급이 높은 순서데로 순위를 부여하시오 !
select ename, to_char(hiredate, 'RRRR'), sal,
dense_rank() over ( partition by to_char(hiredate,'RRRR')
order by sal desc nulls last ) as 순위
from emp;
43. NTILE
예제43번. 데이터 분석 함수로 등급 출력하기(NTILE) 머신러닝(기계학습) 을 하려면 좋은 데이터를 기계에게 제공해줘야합니다. 좋은 데이터를 만드는 작업을 사람이 직접 해야합니다. rank 나 ntile 함수를 이용하면 좋은 데이터를 만들 수 있습니다. rank 는 순위를 출력하는 함수이고 ntile 은 등급을 출력하는 함수 입니다. 문제69. 이름, 월급, 등급을 출력하는데 월급을 4개의 등급으로 나눠서 출력하시오 0~25% : 1 ( 0 < 데이터 <= 25) 25~50% : 2 ( 25 < 데이터 <= 50) 50~75% : 3 ( 50 < 데이터 <= 75) 75~100% : 4 (75 < 데이터 <=100)
select ename, sal, ntile(4) over ( order by sal desc ) 등급 from emp; KING 5000 1 SCOTT 3000 1 FORD 3000 1 JONES 2975 1 BLAKE 2850 2 CLARK 2450 2
문제1. 우리반 테이블에서 이름, 나이, 등급을 출력하는데 등급이 나이가 높은 순서로 5개의 등급으로 나눠서 출력하시오 !
select ename, age, ntile(5) over ( order by age desc) 등급
from emp19
where age is not null;
※ 외워야할 내용 ! ntile 은 무조건 over 입니다.
문제2. 사원 테이블에서 부서번호, 이름, 월급, 등급을 출력하는데 등급이 부서번호별로 각각 월급이 높은 순서데로 등급을 부여하시오 3등급으로 하세요 !
select deptno, ename, sal, ntile(3) over ( partition by deptno
order by sal desc ) as 등급
from emp;
문제3. (빅데이터 활용) 우리나라 출산율 대한 테이블을 생성하시오 !
그냥 편하게 csv 파일을 구할 수 도 있는데 그럴수 없는 경우가 많습니다. 아래의 스크립트는 웹상에서 표형태로 있는 화면을 보고 직접 만든겁니다.
drop table child_birth;
create table child_birth
( c_year number(10),
c_cnt number(10,2),
c_rate number(10,2) ) ;
insert into child_birth(c_year, c_cnt, c_rate)
values(1970, 1007, 4.53);
insert into child_birth(c_year, c_cnt, c_rate)
values(1971, 1025, 4.54);
insert into child_birth(c_year, c_cnt, c_rate)
values(1972, 953, 4.12);
insert into child_birth(c_year, c_cnt, c_rate)
values(1973, 966, 4.07);
insert into child_birth(c_year, c_cnt, c_rate)
values(1974, 923, 3.77);
insert into child_birth(c_year, c_cnt, c_rate)
values(1975, 874, 3.43);
insert into child_birth(c_year, c_cnt, c_rate)
values(1976, 796, 3);
insert into child_birth(c_year, c_cnt, c_rate)
values(1977, 825, 2.99);
insert into child_birth(c_year, c_cnt, c_rate)
values(1978, 751, 2.64);
insert into child_birth(c_year, c_cnt, c_rate)
values(1979, 863, 2.9);
insert into child_birth(c_year, c_cnt, c_rate)
values(1980, 863, 2.82);
insert into child_birth(c_year, c_cnt, c_rate)
values(1981, 867, 2.57);
insert into child_birth(c_year, c_cnt, c_rate)
values(1982, 848, 2.39);
insert into child_birth(c_year, c_cnt, c_rate)
values(1983, 769, 2.06);
insert into child_birth(c_year, c_cnt, c_rate)
values(1984, 675, 1.74);
insert into child_birth(c_year, c_cnt, c_rate)
values (1985, 655, 1.66);
insert into child_birth(c_year, c_cnt, c_rate)
values(1986, 636, 1.58);
insert into child_birth(c_year, c_cnt, c_rate)
values(1987, 624, 1.53);
insert into child_birth(c_year, c_cnt, c_rate)
values(1988, 633, 1.55);
insert into child_birth(c_year, c_cnt, c_rate)
values(1989, 639, 1.56);
insert into child_birth(c_year, c_cnt, c_rate)
values(1990, 650, 1.57);
insert into child_birth(c_year, c_cnt, c_rate)
values(1991, 709, 1.71);
insert into child_birth(c_year, c_cnt, c_rate)
values(1992, 731, 1.76);
insert into child_birth(c_year, c_cnt, c_rate)
values(1993, 716, 1.65);
insert into child_birth(c_year, c_cnt, c_rate)
values(1994, 721, 1.66);
insert into child_birth(c_year, c_cnt, c_rate)
values(1995, 715, 1.63);
insert into child_birth(c_year, c_cnt, c_rate)
values(1996, 691, 1.57);
insert into child_birth(c_year, c_cnt, c_rate)
values(1997, 675, 1.54);
insert into child_birth(c_year, c_cnt, c_rate)
values(1998, 642, 1.46);
insert into child_birth(c_year, c_cnt, c_rate)
values(1999, 621, 1.43);
insert into child_birth(c_year, c_cnt, c_rate)
values(2000, 640, 1.48);
insert into child_birth(c_year, c_cnt, c_rate)
values(2001, 560, 1.31);
insert into child_birth(c_year, c_cnt, c_rate)
values(2002, 497, 1.18);
insert into child_birth(c_year, c_cnt, c_rate)
values(2003, 495, 1.19);
insert into child_birth(c_year, c_cnt, c_rate)
values(2004, 477, 1.16);
insert into child_birth(c_year, c_cnt, c_rate)
values(2005, 439, 1.09);
insert into child_birth(c_year, c_cnt, c_rate)
values(2006, 452, 1.13);
insert into child_birth(c_year, c_cnt, c_rate)
values(2007, 497, 1.26);
insert into child_birth(c_year, c_cnt, c_rate)
values(2008, 466, 1.19);
insert into child_birth(c_year, c_cnt, c_rate)
values(2009, 445, 1.15);
insert into child_birth(c_year, c_cnt, c_rate)
values(2010, 470, 1.23);
insert into child_birth(c_year, c_cnt, c_rate)
values(2011, 471, 1.24);
insert into child_birth(c_year, c_cnt, c_rate)
values(2012, 485, 1.3);
insert into child_birth(c_year, c_cnt, c_rate)
values(2013, 437, 1.19);
insert into child_birth(c_year, c_cnt, c_rate)
values(2014, 435, 1.21);
insert into child_birth(c_year, c_cnt, c_rate)
values(2015, 438, 1.24);
insert into child_birth(c_year, c_cnt, c_rate)
values(2016, 406, 1.17);
insert into child_birth(c_year, c_cnt, c_rate)
values(2017, 358, 1.05);
insert into child_birth(c_year, c_cnt, c_rate)
values(2018, 327, 0.98);
insert into child_birth(c_year, c_cnt, c_rate)
values(2019, 303, 0.92);
insert into child_birth(c_year, c_cnt, c_rate)
values(2020, 272, 0.84);
insert into child_birth(c_year, c_cnt, c_rate)
values(2021, 261, 0.81);
commit;
c_year : 년도 c_cnt : 출생아수 c_rate : 합계출산율
문제 4. 년도, 합계출산율, 순위(합계출산율이 높은 순서대로 순위를 부여하시오)
select c_year, c_rate , rank () over(order by c_rate desc nulls last) 순위
from child_birth;
44. cume_list
예제44. 데이터 분석 함수로 순위의 비율 출력하기(CUME_DIST) 상위 몇 퍼센트인지를 보고 싶을 때 사용하는 함수 Q1. 이름, 월급, 순위, 순위에 대한 비율을 출력하시오(월급에 대한순위)
select ename, sal, dense_rank () over (order by sal desc nulls last) 순위 ,
dense_rank () over (order by sal desc) / 14 as 비율
from emp;
위와 같이 sql을 작성하게 되면 숫자 14를 미리알고 있어야 한다. (but, 회사에서의 데이터는 실시간으로 업뎃됨)
select ename, sal, dense_rank () over (order by sal desc nulls last) 순위 , dense_rank () over (order by sal desc) / 14 as 비율 from emp;
select ename, sal, dense_rank () over (order by sal desc) 순위 ,
cume_dist() over (order by sal desc)as 순위비율
from emp;
문제 1. cume_dist를 사용해서 순위의 비율을 출력하는데 사원 테이블에서 직업이 SALESMAN인 사원들의 사원이름과 월급과 순위의 비율을 출력하시오.
select ename, sal, rank() over ( order by sal desc ) as 순위,
cume_dist() over ( order by sal desc ) as 비율
from emp
where job='SALESMAN';
문제 2. 직업, 직업별 최대월급을 출력하는데 직업별 최대월급이 높은 것 부터 출력하시오.
select job, max(sal)
from emp
group by job
order by 2 desc;
문제3. 위의 결과에서 최대 월급을 출력할때 천단위를 부여하시
select job, to_char(max(sal),'999,999,999')
from emp
group by job
order by 2 desc;
문제4. 위의 결과에서 직업별 최대월급이 2000이상인 것만출력하시오.
select job, to_char(max(sal),'999,999,999')
from emp
group by job
having max(sal)>=2000
order by 2 desc;
45. LIST AGG (+ within group/ group by)
예제 45. 데이터 분석 함수 데이터를 가로로 출력하기(LIST AGG) Q1. 부서번호, 부서번호별 해당하는 사원들의 이름을 가로로 출력하시오.
select deptno, listagg(ename, ',') within group (order by sal desc)
from emp
group by deptno;
select deptno, listagg(ename, '/') within group (order by sal desc)
from emp
group by deptno;
select deptno, listagg(ename, '/') within group (order by ename asc)
from emp
group by deptno;
※ listagg 함수는 다른 데이터 분석함수와는 다르게 group by 절을 필요로 함,
문제1. 직업, 직업별로 속한 사원들의 이름을 가로로 출력하는데 가로로 출력할 때 먼저 입사한 사원순으로 출력하시오 !
select job, listagg(ename, ',') within group (order by hiredate asc)
from emp
group by job
문제2. 입사년도 4자리 ,이름출력하시오.
select to_Char(hiredate,'RRRR'), ename
from emp;
문제3. 입사년도 4자리, 입사년도 별로 속한 사원들의 아름을 가로로 출력하는데 이름을 출력할 때 abcd 순으로 출력하시오.
select to_char(hiredate,'RRRR'), listagg(ename, ',') within group (order by ename asc)
from emp
group by to_char(hiredate,'RRRR');
문제 4. 우리반 테이블에서 성별, 성별별로 속한 학생들의 이름을 가로로 출력 하는데 나이순서데로 출력되게 하시오 ! (나이가 높은 학생부터 출력)
select gender, listagg( ename, ',') within group ( order by age desc )
from emp19
where gender is not null
group by gender;
문제5. (서울 시청 요청 sql) 위의 결과를 다음과 같이 출력하시오.
select gender, listagg(ename||'('||age||')', ',') within group (order by age desc)
from emp19
where gender is not null
group by gender;
문제6. 통신사, 통신사별로 속한 학생들의 이름을 가로로 출력하는데 이름을 출력할때 ㄱㄴㄷㄹ순으로 출력하시오.
select decode(lower(telecom), 'skt', 'sk',lower(telecom)) as telecom,
listagg(ename,',')within group(order by ename asc) as ename
from emp19
where telecom is not null
group by decode(lower(telecom), 'skt', 'sk',lower(telecom)) ;
문제7. emp19에서 나이를 출력하고 나이별로 해당하는 학생들의 이름들을 가로로 출력하시오.
select age, listagg(ename,',') within group(order by birth asc)
from emp19
where age is not null
group by age;
★ 문제8. 위의 결과에 이름 옆에 (통신사) 가 나오도록 출력하시오.
select age, listagg(ename||'('|| lower(telecom)||')',',') within group(order by birth asc)
from emp19
where age is not null
group by age;
46. LAG, LEAD
예제 46. 데이터 분석 함수로 바로 전 행과 다음행 출력하기(LAG, LEAD) - LAG : 이전행 - LEAD : 다음행 Q1. 사원번호, 이름, 바로전행의 사원이름, 바로 다음행의 사원이름을 출력하시오.
select empno, ename, lag(ename,1) over (order by empno asc) 이전행,
lead(ename,1) over (order by empno asc) 다음행
from emp;
문제 1. 이름, 입사일, 바로전 입사한 사원의 입사일, 바로 다음에 입사한 사원의 입사일을 출력하시오.
select ename, hiredate, lag(hiredate,1) over (order by hiredate asc) as "이전 입사일",
lead(hiredate,1) over (order by hiredate asc) "다음 입사일"
from emp;
문제2. 이름, 입사일, 바로전 입사한 사원과의 간격일을 출력하시오.
select ename,hiredate- lag(hiredate,1) over (order by hiredate asc) as "이전 입사일"
from emp;
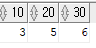
select sum(decode(deptno, 10, sal)) as "10" ,
sum(decode(deptno, 20, sal)) as "20"
from emp;
Q5. 위 결과에서 30번도 출력하시오.
select sum(decode(deptno, 10, sal)) as "10" ,
sum(decode(deptno, 20, sal)) as "20" ,
sum(decode(deptno, 30, sal)) as "30"
from emp;
문제1. 직업,직업별 토탈월급을 세로로 출력하시오.
select job, sum(sal)
from emp
group by job;
문제2. 위의 결과를 가로로 출력하시오.
select sum(decode(job, 'SALESMAN',sal)) as "SALESMAN",
sum(decode(job, 'CLERK',sal)) as "CLERK",
sum(decode(job, 'ANALYST',sal)) as "ANALYST",
sum(decode(job, 'MANAGER',sal)) as "MANAGER",
sum(decode(job, 'PRESIDENT',sal)) as "PRESIDENT"
from emp;
문제3. 우리반에서 성별, 성별 별 평균 나이를 출력하시오. *세로 출력
select gender, round(avg(age))
from emp19
where gender is not null
group by gender;
문제 4. 위 결과를 가로 출력하시오.
select round(avg(decode(gender, '남', age,null)))as "남" ,
round(avg(decode(gender, '여', age,null)))as "여"
from emp19;
where gender is not null;
문제 5. 우리반 테이블 통신사, 통신사별 평균나이 출력하시오,(세로출력)
select lower(telecom), round(avg(age))
from emp19
where lower(telecom) is not null
group by lower(telecom);
문제 6. 위 문제를 가로로 출력하시오.
select round(avg(decode(telecom, 'sk', age))) as "sk",
round(avg(decode(telecom, 'kt', age))) as "kt",
round(avg(decode(telecom, 'lg', age))) as "lg",
round(avg(decode(telecom, 'lg알뜰', age))) as "lg알뜰"
from emp19;
문제 7. (복습문제) 직업, 직업별 인원수를 출력하세요 (세로)
select job, count(job)
from emp
group by job;
문제 8. 부서번호, 부서번호별 인원수 출력 (세로)
select deptno, count(deptno)
from emp
group by deptno;
문제 9. 부서번호, 부서번호별 인원수를 가로로 출력하시오,
1)
select count(decode(deptno, '10', empno)) as "10",
count(decode(deptno, '20', empno)) as "20",
count(decode(deptno, '30', empno)) as "30"
from emp;
2)
select sum(decode(deptno, 10, 1)) as"10",
sum(decode(deptno, 20, 1)) as"20",
sum(decode(deptno, 30, 1)) as"30"
from emp;
문제 10. (복습) 우리반 테이블에서 이름, 주소를 출력하는데 주소를 출력할때 다음과 같이 앞에 3글자만 출력하시오.
select ename, substr(address,1,3)
from emp19
where address is not null;
문제 11. (복습) 주소를 앞에 세글자만 출력하고 주소앞에 세글자 별 건수를 다음과 같이 세로로 출력하시오.
select substr(address,1,3),count(substr(*)) as cnt
from emp19
where address is not null
group by substr(address,1,3);
문제 12. 위 결과를 ㄱㄴㄷ 순으로로 출력하시오.
select substr(address,1,3),count(*) as cnt
from emp19
where address is not null
group by substr(address,1,3)
order by substr(address,1,3) asc;
★문제 13. 위의 결과를 가로로 출력하시오.
select sum(decode(substr(address,1,3), '경기도', 1, null)) as "경기도",
sum(decode(substr(address,1,3), '서울시', 1, null)) as "서울시",
sum(decode(substr(address,1,3), '성남시', 1, null)) as "성남시",
sum(decode(substr(address,1,3), '안양시', 1, null)) as "안양시",
sum(decode(substr(address,1,3), '용인시', 1, null)) as "용인시"
from emp19;