select ename, replace(nvl(comm,'-1'),-1,'no comm')
from emp
order by comm desc nulls last;
-> nvl(__(A)__, __(B)__)
-> A 컬럼이 문자일 경우 B에 숫자 기입은 안된다. (반대도 마찬가지)
[TIL 5] 240516
32. 암시적 형변환
예제 32. 암시적 형 변환 이해하기
[변환함수] 데이터 유형 변환 1) 암시적 데이터 유형변화 2)명시적 데이터 유형변화
Q. 다음의 SQL이 에러가 안나고 실행이 되겠는가?
select ename,sal
from emp
where sal ='3000'
-> 숫자와 문자는 서로 비교할 수 없다. 다른 데이터 베이스 소프트 웨어는 에러가 발생한다. (단, 오라클은 에러가 안남) -> 위의 경우 숫자와 문자를 비교하면 숫자가 우선순위가 더 높아서 문자를 암시적 형 변환한다. -> 결론적으로는 에러가 발생 되는게 바람직하므로, 문법에 맞춰서 정석대로 작성하는게 바람직하다.
** 오라클 실행 설명 보기 **
explain plan for
select ename,sal
from emp
where sal ='3000';
select* from table(dbms_xplan.display);
테이블이 full scan 이 실행 계획으로 출력되고 있으므로, emp 테이블을 처음부터 끝까지 scan 했다는 뜻임 -> SQL 성능이 느려짐 (목차(INDEX) 를 만들어 SQL성능을 좋게 해야함)
* 월급에 INDEX를 만드는 SQL
create index emp_sal
on emp(sal);
문제1. 아래의 SQL의 실행계획을 확인해서 인덱스 스캔을 했는지 확인하시오.
explain plan for
select ename,sal
from emp
where sal =3000;
select* from table(dbms_xplan.display);
= FULL SCAN 보다 INDEX SCAN 을 하는 것이 좋은 SQL
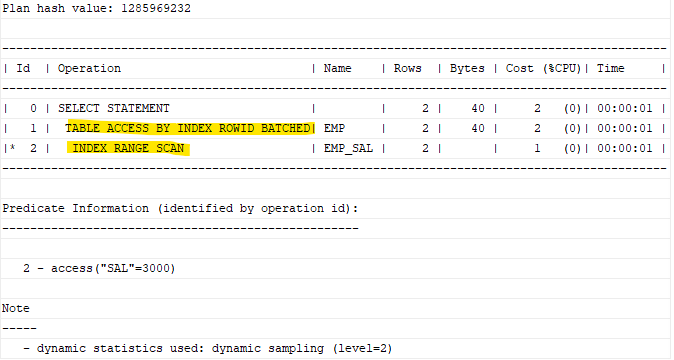
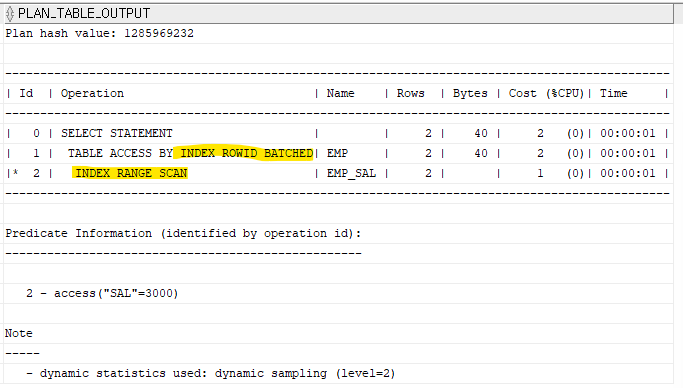
문제2. 아래 SQL의 실행 계획을 확인하시오. (FULL TABLE SCAN 을 하는지 INDEX RANGE SCAN을 하는지)
select ename,sal
from emp
where sal ='3000';
explain plan for
select ename,sal
from emp
where sal ='3000';
select* from table(dbms_xplan.display);
= 인덱스 스캔을 하면서 빠르게 데이터 검색이 되고 있다.
문제3. 아래의 SQL은 실행이 되는지 확인하시오.
select ename,sal
from emp
where sal like '30%';
= 잘 출력됨
문제4. 위의 SQL의 실행 계획을 확인하시오.
explain plan for
select ename,sal
from emp
where sal like '30%';
select* from table(dbms_xplan.display);
= 인덱스를 활용하지 못하고 FULL TABLE SCAN 을 함 -> %를 숫자로 변경 못하고 SAL을 문자형으로 변환함. ->TO_CHAR(SAL) LIKE '30%'이 되면서 성능이 느려짐 -> 암시적 형변환 - SAL은 숫자인데 TO_CHAR(SAL)을 써서 문자형으로 형 변환을 함
** 좋은 성능을 위한 SQL
select ename,sal
from emp
where sal between 3000 and 3099;
※ 다시 정리하면 튜닝전 SQL과 튜닝후 SQL은 다음과 같다. 1)튜닝전
select ename, sal
from
where sal like '30%';
2) 튜닝후
select ename, sal
from
where sal between 3000 and 3099;
문제5. 위 튜닝 후 SQL 실행 계획을 확인하시오.
explain plan for
select ename,sal
from emp
where sal between 3000 and 3099;
select* from table(dbms_xplan.display);
★ ★ WHERE 절 작성시 반드시 숫자는 숫자와 비교되고 날짜는 날짜와 비교되게끔 작성해야함. → 암시적 형 변환이 생기지 않도록!!
문제 6. 입사일에 인데스를 생성하시오.
create index emp_hiredate
on emp(hiredate);
문제 7. 아래의 SQL을 튜닝하시오. A) 튜닝전
select ename, hiredate
from emp
where hiredate like '80%';
Q) 튜닝후
select ename, hiredate
from emp
where hiredate between to_date('1980/01/01', 'RRRR/MM/DD')
and to_date('1980/12/31','RRRR/MM/DD');
문제8. 우리반 테이블에서 1996년에 태어난 학생들의 이름과 생일을 출력하시오.
select ename, birth
from emp19
where birth between to_date('1996/01/01', 'RRRR/MM/DD')
and to_date('1996/12/31','RRRR/MM/DD');
※ SQL 작성시 주의사항! (현업 TIP)
암시적 형변환이 일어나지 않게 작성하라!
33. NVL, NVL2
예제 33번. NULL값 대신 다른 데이터 출력하기 (NVL, NVL2) - NVL함수 (NULL VALUE의 약자)는 NULL 값 대신에 다른 값을 출력하게 해주는 함수
1, 이름과 커미션을 출력하시오
select ename,comm
from emp;
2. 커미션이 null 인 사원들은 0으로 출력하시오
select ename,nvl(comm, 0)
from emp;
3. 이름과 직업을 출력하는데 직업이 null인 사원들은 no job이라는 글씨로 출력되게 하시오.
select ename, substr(ename,1,1), case when substr(ename,1,1) in ('김', '이', '최') then 'A'
when substr(ename,1,1) in ('박', '유', '윤', '신')then 'B'
when substr(ename,1,1) in ('문', '서', '성', '경','심')then 'C'
when substr(ename,1,1) in ('조', '한', '황', '안')then 'ㅇ'
else 'E' END AS 등급
from emp19;
문제 7. 이름, 직업, 보너스를 출력하는데 보너스가 직업이 PRESIDENT 면 null 을 출력하고 나머지 사원들은 자기의 월급으로 출력되게하시오 !
select ename, job, case when job = 'PRESIDENT' then null
else sal end as 보너스
from emp;
문제 8. 위의 결과를 다시 출력하는데 보너스가 높은 사원부터 출력하시오.
select ename, job, case when job = 'PRESIDENT' then null
else sal end as 보너스
from emp
order by 보너스 desc;
문제 9. DECODE사용 - 이름, 월급, 직업과 보너스 출력하는데 보너스가 직업이 PRESIDENT 는 NULL값을 출력하고 나머지는 자신의 월급이 출력되게하시오.
select ename, sal, job, decode(job, 'PRESIDENT', null, sal) as 보너스
from emp;
문제 10. 위의 결과를 보너스가 높은 사원부터 출력하시오. (모 금융사에서 발생한 DECODE 관련 SQL 사고 사례)
select ename, sal, job, decode(job, 'PRESIDENT', NULL, SAL) as 보너스
from emp
order by 보너스 desc ;
틀린 sql - 보너스 950 이 제일 위에 있음 why? ※ decode는 암시적 형변환이 있음
decode
(job,
'PRESIDENT',
NULL,
SAL)
첫번째
두번째
세번째
네번째
1) decode의 세번째 인자값에 따라서 네번째 인자값의 데이터 유형이 결정됨 2) 세번째 인자값으로 null 값이 입력이 되면 null 이 문자형이어서 네번째 값의 데이터 유형이 문자형 (암시적 형변환) = 그래서 문자형이어서 950이 맨위로 올라갔습니다.
문제 11. 위의 결과를 해결하시오.(DECODE CASE 사용)
# case 사용
select ename, sal, job, case when job = 'PRESIDENT' then null
else sal end as 보너스
from emp
order by 보너스 desc nulls last ;
# decode 사용
select ename, sal, job, decode(job, 'PRESIDENT', to_number(NULL), sal) as 보너스
from emp
order by 보너스 desc nulls last;
문제12. (빅데이터 활용 문제) 살인이 가장 많이 일어나는 장소 1위부터 - 3위까지 출력하시오.
select *
from crime_loc
where c_type ='살인'
order by c_cnt desc nulls last fetch first 3 rows only;
문제 13. (빅데이터 활용 문제) 범죄유형을 출력하는데 중복을 제거하여 출력하시오.
select distinct c_type
from crime_loc;
문제 14. (빅데이터 활용 문제) 절도가 많이 일어나는 장소를 1위부터 5위까지 출력하시오.
select *
from crime_loc
where c_type ='절도'
order by c_cnt desc nulls last fetch first 5 rows only;
문제 15. (빅데이터 활용 문제) 살인이 많이 일어나는 시간대가 언제인지 출력하기위한 테이블을 생성하시오.
drop table crime_time;
create table crime_time
( crime_type varchar2(20),
f0t3 number(10),
f3t6 number(10),
f6t9 number(10),
f9t12 number(10),
f12t15 number(10),
f15t18 number(10),
f18t21 number(10),
f21t24 number(10) );
insert into crime_time values('살인',36,34,26,51,46,46,56,69);
insert into crime_time values('살인미수',59,45,24,48,44,61,105,123);
insert into crime_time values('강도',381,594,136,135,169,155,228,349);
insert into crime_time values('강간강제추행',2278,2675,1654,1073,1142,1423,1799,3248);
insert into crime_time values('방화',269,272,107,145,147,211,252,339);
insert into crime_time values('절도',23761,23392,20292,31732,32648,36720,45653,39745);
insert into crime_time values('상해',7751,6107,3401,4412,4254,5508,7572,13043);
insert into crime_time values('폭행',18911,14228,6918,7942,8129,10848,16806,31950);
insert into crime_time values('체포감금',56,69,55,98,89,84,123,114);
insert into crime_time values('협박',222,145,199,506,427,473,544,547);
insert into crime_time values('약취유인',9,5,14,29,22,34,22,21);
insert into crime_time values('폭력행위등',6915,5910,2470,2558,2787,4079,5376,9879);
insert into crime_time values('공갈',207,165,269,612,758,1173,935,591);
insert into crime_time values('손괴',6316,4938,3621,4486,4224,6059,10694,13566);
insert into crime_time values('직무유기',4,6,5,110,27,18,17,10);
insert into crime_time values('직권남용',11,4,6,43,29,17,6,11);
insert into crime_time values('증수뢰',2,1,1,84,37,22,8,2);
insert into crime_time values('통화',51,36,142,2018,777,590,209,133);
insert into crime_time values('문서인장',193,127,65,2364,994,538,359,432);
insert into crime_time values('유가증권인지',10,5,2,86,41,24,19,13);
insert into crime_time values('사기',5149,4034,2315,39296,22459,13987,8323,8483);
insert into crime_time values('횡령',837,686,884,4891,2292,1813,1653,1656);
insert into crime_time values('배임',11,2,3,1007,268,55,24,6);
insert into crime_time values('성풍속범죄',374,286,464,961,983,1608,1296,1353);
insert into crime_time values('도박범죄',360,189,104,450,748,1670,1931,2024);
insert into crime_time values('특별경제범죄',2573,1858,1549,10887,6360,5225,4828,5988);
insert into crime_time values('마약범죄',110,87,53,261,292,322,477,439);
insert into crime_time values('보건범죄',639,369,112,2301,1973,1178,900,1882);
insert into crime_time values('환경범죄',23,29,120,408,813,351,66,64);
insert into crime_time values('교통범죄',42507,31839,41865,44621,47385,59278,75466,157988);
insert into crime_time values('노동범죄',30,21,33,245,74,45,73,157);
insert into crime_time values('안보범죄',5,2,3,13,8,10,5,9);
insert into crime_time values('선거범죄',11,14,49,225,142,124,86,38);
insert into crime_time values('병역범죄',11,3,44,4085,775,106,108,28);
commit;
문제 16. (빅데이터 활용 문제) unpivot문을 이용하여 컬럼이 데이터가 되게하시오
select *
from crime_time
unpivot(건수 for 시간 in (F0T3, F3T6, F6T9,F9T12, F12T15,F15T18,F18T21,F21T24));
문제 17 (빅데이터 활용 문제) . 위의 출력된 결과를 가지고 crime_time2라는 테이블을 생성하시오.
create table crime_time2
as
select * from crime_time
unpivot(건수 for 시간 in (F0T3, F3T6, F6T9,F9T12, F12T15,F15T18,F18T21,F21T24));
select * from crime_time2;
★문제 18 .crime_time2 테이블을로 살인이 많이 일어나는 시간대 1위부터 3까지 출력하시오
select *
from crime_time2
where crime_type ='살인'
order by 건수 desc nulls last fetch first 3 rows only;
★ 문제 19. 아산병원 데이터 분석가가 작성하는 sql인 이름마스킹하는 sql을 case문을 이용하여 만들어 보시고 (제갈 ○, 김송 ○ )
SELECT ename, CASE WHEN ename LIKE '남궁%' THEN REPLACE(ename, SUBSTR(ename, 3, 1), '○')
WHEN ename LIKE '제갈%' THEN REPLACE(ename, SUBSTR(ename, 3, 1), '○')
ELSE REPLACE(ename, SUBSTR(ename, 2, 1), '○') END AS "개인정보보호(이름)"
FROM emp19
ORDER BY empno desc;
2안)
SELECT ename, CASE WHEN ename LIKE '남궁%' THEN '남궁○'||SUBSTR(ename, 4)
WHEN ename LIKE '제갈%' THEN '제갈○'||SUBSTR(ename, 4)
ElSE SUBSTR(ename, 1, 1) || '○' || SUBSTR(ename, 3) END AS "개인정보보호(이름)"
FROM emp19
ORDER BY empno desc;