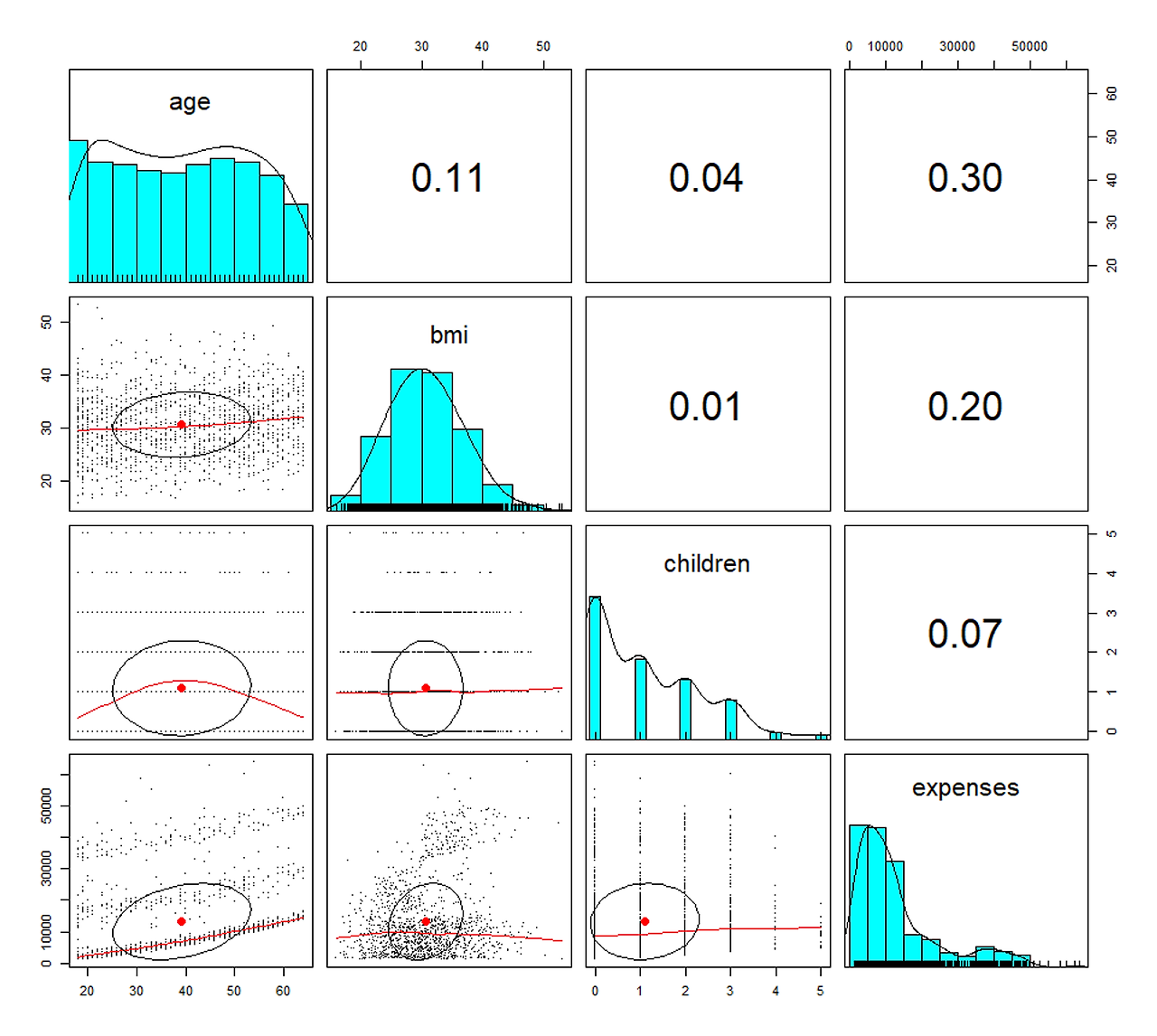
대각선 : age는 값이 고르게 분포되어있고 특정 연령대에 데이터가 집중되어있지 않음 bmi는 대략적인 정규분포 형태를 보이고 대부분의 값이 중간 범위에 집중되어 있음 children은 대부분 0~2 사이에 있고 3이상의 값은 상대적으로 적음 expenses는 오른쪽으로 꼬리가 긴 분포를 보이며 대부분 값이 낮은 범위에 집중되어 있음 두번째 상관관계를 나타내는 숫자 : 거의 대부분 상관관계가 없지만 나이와 의료비와는 약한 양의 상관관게를 보임 나이가 많을수록 의료비가 더 지출되는 경향이 있음을 보임 세번째 빨간색 선, 점, 동그란 원 그래프: 상관관계가 조금이나마 있는 나이와 의료비와의 빨간 직선이 기울어져 있는 부분을 확인하면 됨
■ 정방행렬이란? (정사각형 행렬) ■ 역행렬이란?
방정식에서는 역행렬이 다음과 같이 사용됨.
의사 역행렬
코드로 구현하기 위한 설명:
다음은 참고 자료입니다.
책 264 페이지 맨위에 Y =BX 를 위의 식을 보고 다시 쓰면 BX = Y 가 된다.
여기서 B 를 A 로 하고 Y 를 b 라고 하면 위의 식처럼 나오는데 A 행렬이 정방행렬이 아니면 역행렬을
구할 수 없으니 아래와 같이 A 행렬의 전치행렬을 곱하게 되면 정방행렬이 되고
이 정방행렬의 정방행렬 역행렬을 곱하면 단위행렬이 된다.
단위행렬에 x 를 곱하면 그냥 x 이므로 왼쪽은 그냥 아래와 같이 x 만 남게 된다.
실습. 아래의 식을 R코드로 구현하기 (p.292)
reg <- function(y,x) {
x <- as.matrix(x)
x <- cbind(Intercept = 1,x)
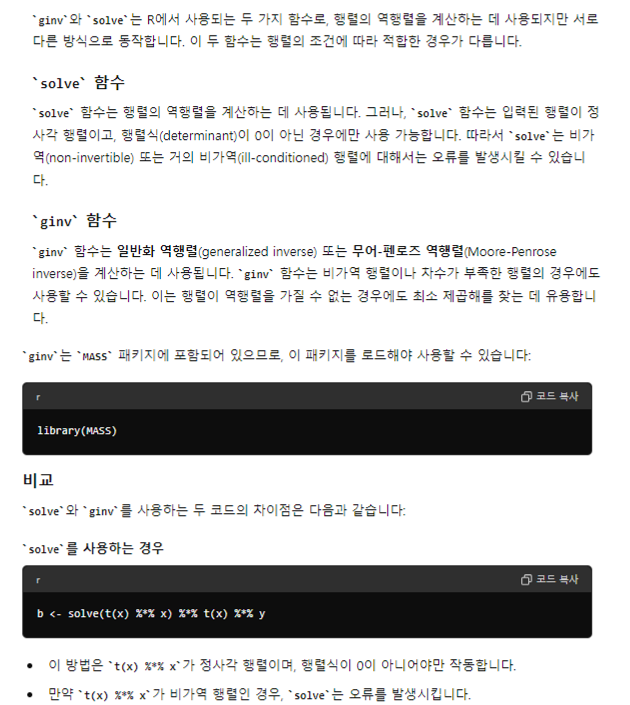
b <- solve(t(x) %*% x) %*% t(x) %*% y
colnames(b) <- "estimate"
print(b)
}
풀이:
# 필요한 패키지 로드
library(MASS)
# reg 함수 정의
reg <- function(y, x) {
x <- as.matrix(x)
x <- cbind(Intercept = 1, x)
b <- ginv(t(x) %*% x) %*% t(x) %*% y
colnames(b) <- "estimate"
print(b)
}
# 주어진 연립일차방정식의 행렬 A와 벡터 b
A <- matrix(c(2, 1, 2, 3, 2, -1), nrow = 2, byrow = TRUE)
b <- matrix( c(7, 1) ,nrow=2, byrow=T)
# 함수를 사용하여 해를 구함
reg(b, A)
실습. 책 p.294 에서 만든 reg 함수를 사용해서 우주 왕복선 챌린저호 폭파의 가장 큰 원인인 O형링 파손 (distress_ct)의 가장 큰 영향을 준 독립변수가 무엇인지 출력하기
setwd("c:\\data\\")
cha <- read.csv("c:\\data\\challenger.csv",header=T)
cha
x <- cha[ ,c(2:4)]
x
y <- cha$distress_ct
y
#reg 함수 정의
reg <- function(y,x) {
x <- as.matrix(x)
x <- cbind(Intercept = 1,x)
b <- solve(t(x) %*% x) %*% t(x) %*% y
colnames(b) <- "estimate"
print(b)
}
reg(y=cha$distress_ct, x=cha[ , c(2:4)])
#1. 데이터를 불러오기
ins <- read.csv("insurance.csv", header=T)
#2. 데이터를 살펴보기
View(ins)
colSums(is.na(ins)) #결측치 확인
#3. 다중회귀 분석 모델을 생성하기
model <- lm(expenses ~ ., data = ins)
#또는 아래와 같이 써도 됨
model <- lm(expenses ~ age + children + sex + smoker + region + bmi, data = ins)
#4. 회귀분석 결과를 해석하기
options(scipen = 999)
summary(model)
#5. 회귀분석 모델의 성능을 높이기
#파생변수를 추가해서 설명력을 높이기
#파생변수1. 기계에게 비만인 사람과 비만이 아닌 사람에 대한 기준을 알려주기
ins$bmi30 <- ifelse(ins$bmi >= 30, 1, 0)
head(ins)
model2 <- lm(expenses ~ ., data = ins)
summary(model2) # 결정계수값이 0.7509 --> 0.7559 으로 소폭 상승
#귀무가설 : 비만과 의료비는 서로 연관이 없다
#대립가설 : 비만과 의료비는 서로 연관이 있다
#bmi30의 p-value 값이 작으므로 대립가설을 채택할 충분한 근거가 있음
#파생변수2. 비만이면서 흡연을 하면 1이라고 하고 아니면 0이라고 하는 파생변수를 smokeryse_bmi30이라는 이름으로 추가하기
ins$smokeryes_bmi30 <- ifelse(ins$smoker=='yes' & insurance$bmi >= 30, 1, 0)
head(ins)
model3 <- lm(expenses ~ ., data = ins)
summary(model3)
#Multiple R-squared: 0.8639
#다음과 같이 모델을 생성해도 됨
#비만이면서 흡연을 했을 때 의료비 영향을 미치는지 확인
model4 <- lm(expenses ~ age + children + bmi +smoker + bmi30*smoker, data=ins)
summary(model4)
해석:
나이가 일년씩 더해질 때 마다 평균적으로 의료비가 256.8 달러 증가될 것으로 예상됨
더미 변수인 sexmale 이 자동으로 추가되면서 변수값의 상대적 추정을 했을 때 결과는 남성은 여성에 비해서 매년 의료비가 131.4 달러 적게 든다고 예상하고 있음
비만지수 (bmi)의 단위가 증가할 때 연간 의료비가 339 달러가 증가될 것으로 예상하고 있음
자녀(children)수가 한 명 추가될 때 마다 475달러가 추가될 것으로 예상됨
흡연자(smokeryes)가 비 흡연자보다 매년 평균 의료비가 23847 달러가 더 소요될 것으로 예상됨
northeast에 비해서 northwest는 의료비가 연간 평균 352.8 달러가 덜 소요되고,
southeast는 의료비가 연간 평균 1035.6 달러가 덜 소요되고 southwest는 의료비가 연간 평균 959.3 달러 덜 소요됨
결정계수 : Multiple R-squared : 0.7509,
결정계수란? 모델이 데이터를 설명하는 설명력의 척도로, 1에 가까울수록 설명력이 좋은 회귀모델임
실습. 여러분들이 추가하고 싶은 파생변수를 위와 같이 * 를 사용해서 모델을 생성하고 통계적으로 유의한지 확인하기
model5 <- lm(expenses ~ age + children + bmi +smoker + bmi30*smoker + children*smoker, data=ins)
summary(model5)
■ 표준화와 정규화를 수행한 후의 회귀분석
실습.미국 학교 데이터의 acceptance에 가장 영향이 큰 과목이 학과점수인지 체육점수인지 음악점수인지 확인하는 방법 1. 정규화하지 않았을 때의 결과
m <- read.csv("sports.csv", header=T)
lm(acceptance ~ ., data=m)
★ 마지막문제: 다중회귀 이론 수업 맨 아래쪽에 나오는 연립방정식 문제를 오늘 만든 reg 함수를 이용해서 풀기
# 필요한 패키지 로드
library(MASS)
# reg 함수 정의
reg <- function(y, x) {
x <- as.matrix(x) # 독립 변수 행렬을 행렬로 변환
b <- ginv(t(x) %*% x) %*% t(x) %*% y # 일반화된 역행렬을 사용하여 해 계산
colnames(b) <- "estimate" # 결과에 열 이름을 붙임
print(b) # 결과 출력
return(b) # 결과 반환
}
# 주어진 연립일차방정식의 행렬 A와 벡터 b
A <- matrix(c(3, 2, 1, 1, -1, 4), nrow = 2, byrow = TRUE)
b <- matrix(c(4, 3), nrow = 2, byrow = TRUE)
A
b
# 함수를 사용하여 해를 구함
r <- reg(b, A)
r
# 해를 검증함
r1 <- 3 * r[1] + 2 * r[2] + r[3] # 첫 번째 방정식의 좌변
r2 <- r[1] - r[2] + 4 * r[3] # 두 번째 방정식의 좌변
# 검증 결과 출력
cat("3 * r[1] + 2 * r[2] + r[3] =", r1, "\n") # 기대값: 4
cat("r[1] - r[2] + 4 * r[3] =", r2, "\n") # 기대값: 3