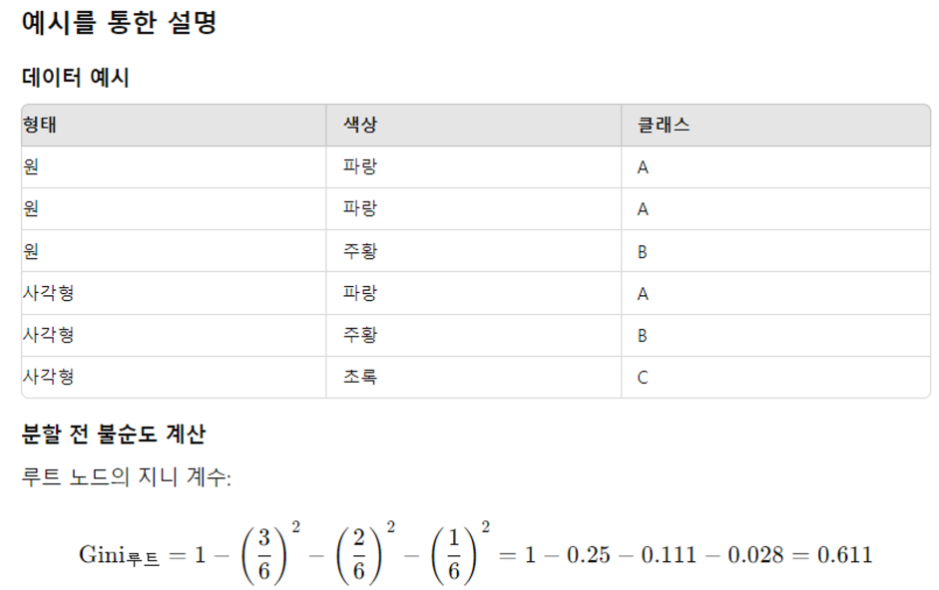
# 데이터 불러오기
buy <- data.frame(
cust_name=c('SCOTT','SMITH','ALLEN','JONES','WARD'),
card_yn=c('Y','Y','N','Y','Y'),
intro_yn=c('Y','Y','N','N','Y'),
before_buy_yn=c('Y','Y','Y','N','Y'),
buy_yn=c('Y','Y','N','Y','Y') )
buy
library(FSelector) # 정보 획득량 구하기
library(doBy) # 자동 정렬 처리
library(plotly)
weights <- information.gain( buy_yn ~ . , buy[ , c(2:5)], unit='log2')
weights
orderBy( ~ attr_importance, weights )
# 1. 데이터 불러오기
a <- orderBy( ~ attr_importance, weights )
info_gain_df <- data.frame( col1=rownames(a), col2=a$attr_importance)
info_gain_df
# 색깔 지정하기
colors <- c('#FFCDD2','#E1BEE7','#BBDEFB')
# 4. plotly 를 사용한 막대 그래프 생성하기
fig <- plot_ly( info_gain_df,
x = ~col1,
y = ~ col2,
type = 'bar',
marker = list(color = colors))
# 5. 그래프 출력
fig
■ R을 이용해서 의사결정 트리모델 만들기
실습 2 데이터: 화장품 고객 데이터 (skin.csv) 1) 순서: #1. 데이터 불러오기 #2. 데이터 살펴보기 #3. 훈련 데이터와 테스트 데이터 분리하기 #4. 의사결정트리 모델 만들기 #5. 테스트 데이터 예측하기 #6. 모델 성능 확인하기 #7. 모델 성능 평가하기
2) 코드구현:
summary(model) 결과
설명: 결혼유무를 가장 중요한 결정 요인으로 골랐습니다. 그리고 나이와 직업 순서로 정보획득량이 높아서 위와 같이 질문 나무를 생성함
#1. 데이터 불러오기
setwd("c:\\data")
skin <- read.csv("skin.csv" , stringsAsFactors=T, fileEncoding = "euc-kr")
head(skin)
#2. 데이터 살펴보기
colSums(is.na(skin))
#3. 훈련 데이터와 테스트 데이터 분리하기
library(caret)
set.seed(1)
train_num <- createDataPartition( skin$cupon_react, p=0.8, list=F)
length(train_num) # 25
train_data <- skin[ train_num, ]
test_data <- skin[ -train_num, ]
nrow(train_data) # 25
nrow(test_data) # 5
#4. 의사결정트리 모델 만들기
install.packages("C50")
library(C50) # 질문 나무 만드는 패키지
model <- C5.0( train_data[ , c(-1, -7) ], train_data[ , 7] )
## 고객번호와 정답을 제외 정답
model
## Classification Tree
## Number of samples: 25 ->
## Number of predictors: 5 -> 가지를 5개 만들었다.
summary(model)
plot (model)
#5. 테스트 데이터 예측하기
# 1) 훈련 데이터의 정확도
train_result <- predict( model, train_data[ , c(-1, -7) ] )
train_result
sum(train_result ==train_data[ ,7])/25*100 #정확도 88%
# 2) 테스트 데이터의 정확도
test_result <- predict( model, test_data[ , c(-1, -7) ] )
test_result
sum(test_result ==test_data[ ,7])/5*100 #정확도 80%
#6. 모델 성능 확인하기
library(C50)
model2 <- C5.0( train_data[ , c(-1, -7) ], train_data[ , 7] ,trials = 5 )
model2
## trials = 5 의 의미 : 의사결정트리 모델 5개를 생성해서 5개의 모델이
## 예측한 결과를 가지고 다수결을 붙여서 다수결에 의해서 예측하겠다는 뜻
#7. 모델 성능 평가하기
test_result2 <- predict( model2, test_data[ , c(-1, -7) ] )
test_result2
sum(test_result2 ==test_data[ ,7])/5*100 #정확도 60%
설명: 훈련 데이터의 정확도는 100% 인데 트스트가 60% 입니다. 오버피팅이 발생했습니다. 오버피팅이 적게 일어나면서 정확도는 좋은 적절한 trials 값을 알아내야합니다.
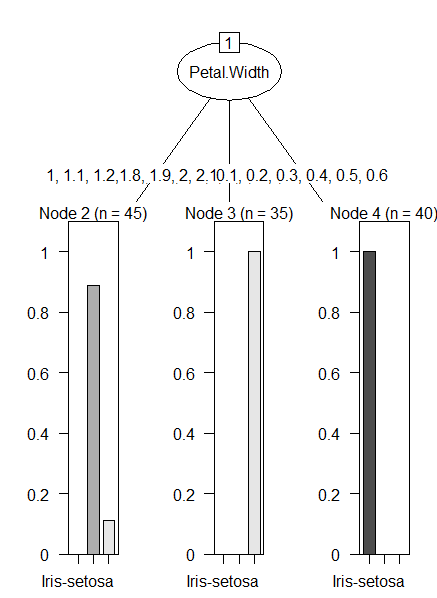
실습 2. 아이리스 꽃의 품종을 분류하는 의사결정트리 모델을 생성하시오. 데이터: 아이리스 데이터
#1. 데이터 불러오기
setwd("c:\\data")
iris <- read.csv("iris2.csv" , stringsAsFactors=T, fileEncoding = "euc-kr")
head(iris)
#2. 데이터 살펴보기
colSums(is.na(iris)) # 결측치 0개
#3. 훈련 데이터와 테스트 데이터 분리하기
library(caret)
set.seed(1)
train_num <- createDataPartition( iris$Species, p=0.8, list=F)
length(train_num) # 120
train_data <- iris[ train_num, ]
test_data <- iris[ -train_num, ]
nrow(train_data) # 120
nrow(test_data) # 30
#4. 의사결정트리 모델 만들기
install.packages("C50")
library(C50) # 질문 나무 만드는 패키지
model <- C5.0( train_data[ ,-5], train_data[ , 5] )
## 정답을 제외 정답
model #가지를 3개 만들음음
summary(model)
plot (model)
#5. 테스트 데이터 예측하기
# 1) 훈련 데이터의 정확도
train_result <- predict( model, train_data[ ,-5 ] )
train_result
sum(train_result ==train_data[ ,5])/120 *100 #정확도 95.83%
# 2) 테스트 데이터의 정확도
test_result <- predict( model, test_data[ , -5 ] )
test_result
sum(test_result ==test_data[ ,5])/30*100 #정확도 96.66%
#6. 모델 성능 확인하기
y <- 0
jumpby <-1
options(scipen=999)
for ( i in 1:10 ) {
model<-C5.0(train_data[ ,-5],train_data[ ,5], trials=y)
test_result2 <- predict(model, test_data[ ,-5])
a<- sum(test_result2 == test_data[ ,5])/30 *100 #100%
y <- y + jumpby
print(paste(i,'일때',a))
}
library(C50)
model2 <- C5.0( train_data[ , -5], train_data[ , 5] ,trials = 5 )
model2
## trials = 5 의 의미 : 의사결정트리 모델 5개를 생성해서 5개의 모델이
## 예측한 결과를 가지고 다수결을 붙여서 다수결에 의해서 예측하겠다는 뜻
#7. 모델 성능 평가하기
test_result2 <- predict( model2, test_data[ , -5 ] )
test_result2
sum(test_result2 ==test_data[ ,5])/30*100 #정확도 96.66%
train_result <- predict( model2, train_data[ ,-5 ] )
train_result
sum(train_result ==train_data[ ,5])/120 *100 #정확도 100%
실습3. 은행 대출 불이행자 예측 모델
#1. 데이터를 불러옵니다.
credit <- read.csv("credit.csv", stringsAsFactors=T)
head(credit)
#2. 데이터를 살펴봅니다.
str(credit)
# 데이터 설명
checking_balance : 예금계좌
saving_balance : 적금계좌
amount : 대출금액
default : 채무불이행 여부(종속변수)
# amount을 히스토그램 그래프로 그려보시오!
hist(credit$amount)
summary(credit$amount)
Min. 1st Qu. Median Mean 3rd Qu. Max.
250 1366 2320 3271 3972 18424
최소250마르크(천칠백 오십만원) ~ 18,424(12억 8천만원)
정답컬럼: default ---> yes : 대출금 상환안함
no : 대출금 상환함
prop.table( table(credit$default) )
30% 에 해당하는 사람들이 대출금을 상환하지 않고있어서
머신러닝 모델을 만들어서 대출금을 상환하지 않을것으로 예측되는 고객은
아예 대출을 안해주게 해서 대출금 상환안하는 고객의 비율을 최대한 낮춰보는것이
머신러닝 모델을 만드는 목적입니다.
# 결측치 확인
colSums( is.na(credit))
#3. 훈련 데이터와 테스트 데이터 분리
library(caret)
set.seed(1)
train_num <- createDataPartition( credit$default, p=0.9, list=F)
train_data <- credit[ train_num, ]
test_data <- credit[ -train_num, ]
nrow(train_data) #900
nrow(test_data) #100
ncol(train_data) # 17
head(train_data) # 종속변수가 17번째 컬럼입니다.
#4. 모델 생성
library(C50)
credit_model <- C5.0( train_data[ , -17], train_data[ , 17] )
#5. 모델 확인
summary(credit_model)
Decision tree:
checking_balance = unknown: no (356/42) # 예금통장이 unknown 인 사람들 356이
# 돈을 갚았고 42명은 예외입니다.
checking_balance in {< 0 DM,> 200 DM,1 - 200 DM}:
:...amount > 8648: yes (31/6) 대출금액이 8648 마르크보다 더 큰 사람들중 31명이
amount <= 8648: 대출금을 상환하지 않았습니다. 대출금액이 8448 이하
:...credit_history in {perfect,very good}: 인 사람들중에 신용이력이 perfect,very good
:...housing in {other,rent}: yes (26/3) 인 사람들중에서 집이 랜트이거나 기타유형
이면 돈 안갚았습다.
: housing = own: 집이 자가 소유인데
: :...savings_balance in {> 1000 DM,500 - 1000 DM, 적금이 있으면
: : unknown}: no (8/2) 8명이 대출금 갚았습니다.(2명 예외)
#6. 모델 예측
train_result <- predict( credit_model, train_data[ , -17] )
test_result <- predict( credit_model, test_data[ , -17] )
#7. 모델 평가
#훈련 정확도
sum( train_result == train_data[ , 17] ) / 900 * 100 # 83.33 %
#테스트 정확도
sum( test_result == test_data[ , 17] ) / 100 * 100 # 67%
#8. 모델 개선
문제172. trials 파라미터를 주고 모델의 성능을 올리시오 !
y <- 1
jumpby <-1
options(scipen=999)
for ( i in 1:20 ) {
credit_model2 <- C5.0( train_data[ , -17], train_data[ , 17], trials=y )
test_result2 <- predict( credit_model2, test_data[ , -17] )
a<- sum(test_result2 == test_data[ ,17])/100 *100 #100%
y <- y + jumpby
print(paste(i,'일때',a))
}
[1] "6 일때 78" 이 나왔습니다. 정확도만 봐서는 안되고 FN (거짓부정) 을 같이
봐야합니다.
library(gmodels) # 의사결정 나무의 갯수는 1 ~100까지만 지정할 수 있습니다.
credit_model2 <- C5.0( train_data[ , -17], train_data[ , 17], trials=6 )
test_result2 <- predict( credit_model2, test_data[ , -17] )
x <- CrossTable( test_data[ , 17], test_result2 )
x$t
y
x no yes
no 65 5
yes 17 13
★ 마지막 문제: 와인데이터를 이용하여 의사결정 트리모델을 올리고 정확도를 올리시오.
#1. 데이터를 불러옵니다.
wine <- read.csv("wine2.csv", stringsAsFactors=T)
head(wine)
#2. 데이터를 살펴봅니다.
str(wine)
#3. 결측치 확인
colSums(is.na(wine)) # 결측치 없음음
#3. 훈련 데이터와 테스트 데이터 분리
library(caret)
set.seed(1)
train_num <- createDataPartition( wine$Type, p=0.8, list=F)
train_data <- wine[ train_num, ]
test_data <- wine[ -train_num, ]
nrow(train_data) #143
nrow(test_data) #34
#4. 모델 생성
library(C50)
model <- C5.0( train_data[ , -1], train_data[ , 1] )
#5. 모델 확인
summary(model)
#6. 모델 예측
train_result <- predict( model, train_data[ , -1] )
test_result <- predict( model, test_data[ , -1] )
#7. 모델 평가
#훈련 정확도
sum( train_result == train_data[ , 1] ) / 143 * 100 # 99.3%
#테스트 정확도
sum( test_result == test_data[ , 1] ) / 34 * 100 # 94.12%
#8. 모델 개선
y <- 1
jumpby <-1
options(scipen=999)
for ( i in 1:20 ) {
model2 <- C5.0( train_data[ , -1], train_data[ , 1], trials=y )
test_result2 <- predict( model2, test_data[ , -1] )
a<- sum(test_result2 == test_data[ ,1])/34 *100 #100%
y <- y + jumpby
print(paste(i,'일때',a))
}
[1] "4 일때 100" 으로 가장 높음