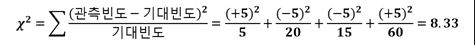설명: 부서번호별 직업별 인원수가 출력되면서 오른쪽에는 row 토탈이 출력 맨 아래쪽에는 칼럼 토털이 출력됩니다.
※ CrossTable 해석 요약:
빈도수 (N): 해당 셀의 실제 관측값 카이제곱 기여도 (Chi-square contribution): 해당 셀이 카이제곱 통계량에 기여하는 정도 행 기준 비율 (N / Row Total): 해당 행에서 해당 셀의 비율 열 기준 비율 (N / Col Total): 해당 열에서 해당 셀의 비율 전체 기준 비율 (N / Table Total): 전체 테이블에서 해당 셀의 비율
예제2. 월급을 2500을 기준으로 직업별로 각각 월급이 2500 이상인 사원들과 월급이 2500 보다 작은 사원들의 분포를 이원 교차표로 확인하시오
카이제곱값: Chi^2 = 0.1539564 / 자유도: d.f. = 2 / p-value: p = 0.92591 설명: P-Value 확률이 0.05 보다 작다면 두 변수가 연관이 있다는 강한 증거를 제공하는데 0.9 이면 모델과 색깔의 연관성은 우연 때문이고 실제로 연관이 있지않을 가능성이 높습니다.
카이제곱 검정이란?
카이제곱 분포는 1900년 경에 칼 피어슨에 의해서 개발되어
모집단에 대한 가설검정이나 교차분석에 유용하게 되는 검정방법
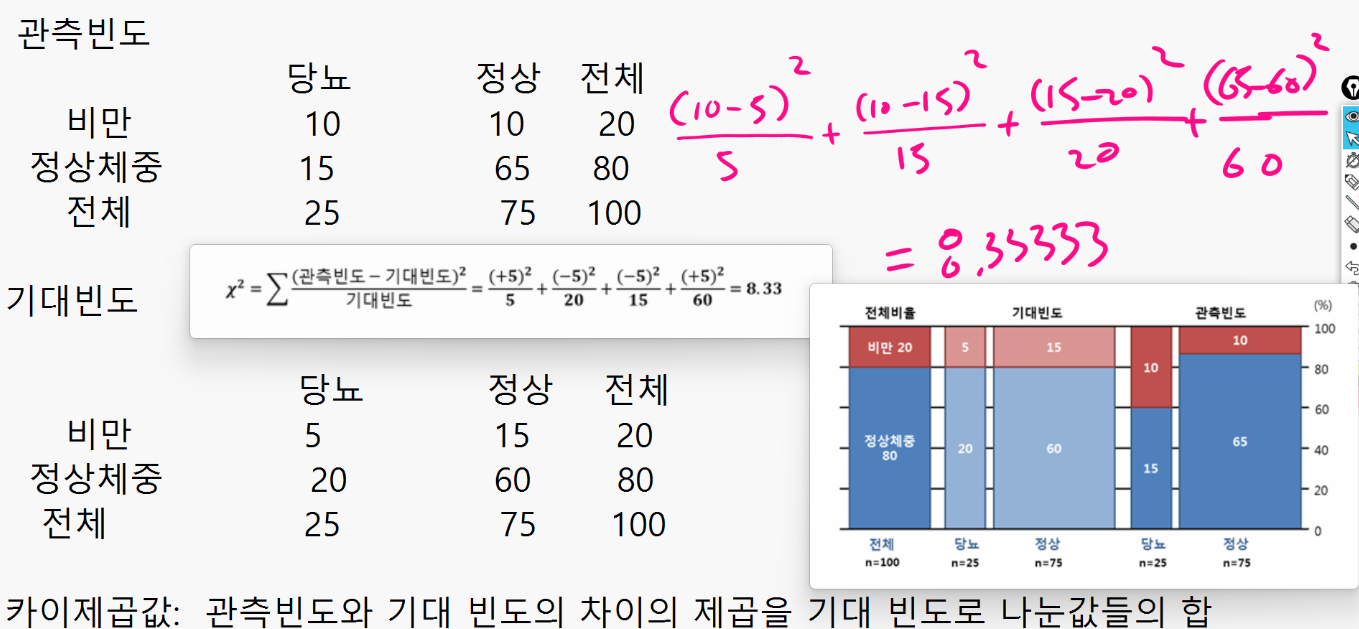
예제 1. 아래의 2x2 크로스 집계 표를 보고 두 변수가 연관성이 있는지 살펴보시오!
관측빈도
당뇨
정상
전체
비만
10
10
20
정상체중
15
65
80
전체
25
75
100
귀무가설: 당뇨와 비만은 연관성이 없다. (챔피언) 대립가설: 당뇨와 비만은 연관성이 있다. (도전자)
두 집단의 비만 비율이 통계적으로 차이가 없다면 당뇨환자 25명 중에서 20% (5명)가 비만이고 정상인 75명 중에서 20%(15명)가 비만일 것으로 기대할 수 있을 것이다. 이렇듯 두 변수 사이에 연관성이 없다는 가정하에 예상되는 빈도를 "기대빈도"라고 합니다.
카이제곱값: 8.33333, 자유도: 1 일 때 p-value 확률은? 1 - pchisq( q=8.33, df = 1, lower.tail=TRUE) 0.003899566 0.004의 확률이므로 유의수준으 5%(0.05)로 두면 귀무가설이 기각이 되고 대립가설이 채택이 될 수 있는 것입니다. 비만과 당뇨는 연관성이 있다고 보는 것입니다.
카이제곱값이 높을수록 ---> 확률이 낮아진다 ---> 두 변수의 연관성이 많다 카이제곱값이 낮을수록 ---> 확률이 높아진다 ---> 두 변수의 연관성이 적다
위에 풀이과정은 카이제곱검정을 이해하기 위한 설명이었고 그냥 실세계에서 두 명목 변수 간의 연관성이 우연인지 아닌지를 확인하는 방법은 다음과 같이 CrossTable 이원 교차표를 이용하면 됩니다.
결과해석: p-value 가 0.007 이므로 0.05 보다 작으므로 귀무가설을 기각하고 대립가설을 채택할 충분한 근거가 있습니다. 그러므로 직업과 커미션의 수급 유무는 연관이 있다고 볼 수 있습니다. 경고 메시지가 나온 이유는 이는 표본의 크기가 작거나 기대빈도가 너무 낮을 때 발생할 수 있습니다.라는 경고 메시지입니다.
문제 2. 카이제곱 검정에 대한 현업 연구 사례의 데이터로 카이제곱 검정을 수행하시오
한 연구에서는 사람들이 영화를 보러 갈 때 간식을 구매하는지 여부가 영화 장르와 관련이 있는지를 조사했습니다. 영화 장르(액션, 코미디, 드라마 등)와 간식 구매 여부(구매함, 구매하지 않음)라는 두 범주형 변수를 사용하여 카이제곱 독립성 검정을 수행했습니다. 이를 통해 특정 영화 장르가 간식 구매에 미치는 영향을 확인할 수 있습니다.
# 영화 장르와 간식 구매 여부에 대한 데이터 생성
data <- data.frame(
Genre = c(rep("Action", 50), rep("Comedy", 50), rep("Drama", 50)),
Snack = c(
sample(c("Yes", "No"), 50, replace = TRUE, prob = c(0.7, 0.3)),
sample(c("Yes", "No"), 50, replace = TRUE, prob = c(0.5, 0.5)),
sample(c("Yes", "No"), 50, replace = TRUE, prob = c(0.4, 0.6))
)
)
# 데이터 확인
print(head(data))
답:
CrossTable( data$Genre, data$Snack, chisq=TRUE )
설명: p-value가 0.05 보다 높으므로 영화 장르와 간식 구매여부 간에는 통계적으로 유의미하지 않으므로 영향을 미치지가 않는다.
자리마다 다른 게 나온 이유는 sample 함수가 랜덤 하게 데이터를 생성해서입니다. 다음과 같이 seed 값을 설정하고 sample 함수를 쓰면 자리마다 동일하게 출력됩니다.