select v.ename, v.sal, v.loc, s.grade
from emp_dept v, salgrade s
where v.sal between s.losal and s.hisal;
답)
select /*+ no_merge(v) leading(s,v)
leading(v.e,v.d) use_hash(v.d)*/ v.ename, v.sal, v.loc, s.grade
from emp_dept v, salgrade s
where v.sal between s.losal and s.hisal;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
[TIL 29] 240625
38. not in 연산자 사용한 서브쿼리문
예제 38. not in 연산자 사용한 서브쿼리문을 튜닝할 줄 알아야됨.
(복습문제) DALLAS에서 근무하는 사원들의 이름과 월급을 출력하는데 서브쿼리문으로 수행하시오.
selecr ename, sal
from emp
where deptno in (selecr deptno from dept where loc ='DALLAS')
(복습문제 2) 위의 실행계획이 해쉬 세미조인(semi join) 이 되게 하시오!
※ 조인문장 튜닝은 조인 순서와 조인방법만 잘 결정하면 됩니다.
※ 세미조인(semi join) 힌트 3가지?
세미조인은 완전한 조인이 아니라 절반의 조인인데 SQL문장이 조인문이 아니라 서브쿼리문의 실행에 조인방법을 사용하려고 만든 오라클 기법입니다.
답:
select ename, sal
from emp
where deptno in ( select /*+ hash_sj */ deptno
from dept
where loc='DALLAS' );
(복습문제 3) 위의 해쉬 세미 조인에서 해쉬 테이블이 dept 가 되게 하시오!
select ename, sal
from emp
where deptno in ( select /*+ hash_sj */ deptno
from dept
where loc='DALLAS' );
답:
select ename, sal
from emp
where deptno in ( select /*+ hash_sj swap_join_inputs(dept) */ deptno
from dept
where loc='DALLAS' );
설명: dept 테이블이 emp 테이블보다 크기가 더 작으니까 dept 테이블이 해쉬 테이블이 되어줘야 합니다.
문제 1. 위의 SQL을 수정해서 DALLAS에서 근무하지 않은 사원들의 이름, 월급 출력하시오.
select ename, sal
from emp
where deptno not in (select deptno from dept where loc = 'DALLAS');
설명: 실행계획을 보게 되면 해쉬 안티 조인을 하고 있습니다. 안티(anti) 조인은 세미 조인과 같은 건데 not이 붙어서 안티 조인인 겁니다. 메인쿼리의 데이터중에 서브쿼리에 없는 데이터를 찾는 실행계획인데 해쉬조인(메모리에서 조인)의 장점을 살려서 찾는 실행계획입니다.
※ 안티 조인(anti join) 힌트 3가지?
1. nested loop anti join : nl_aj 2. hash anti join : hash_aj 3. sort merge anti join : merge_aj
select ename, sal
from emp
where deptno not in ( select /*+ hash_aj */ deptno
from dept
where loc='DALLAS' );
※ 핵심정리 in 연산자 서브쿼리에 썼으면 hash_sj 힌트를 써서 해쉬 세미조인하게 하고 not in 연선자 서브쿼리에 썻으면 hash_aj 힌트를 써서 해쉬 안티조인된게 합니다.
문제 2. 아래의 서브쿼리를 해쉬 안티 조인 할 때 작은 테이블인 dept 테이블이 해쉬테이블로 구성되게 하시오.
select ename, sal
from emp
where deptno not in ( select /*+ hash_aj swap_join_inputs(dept)*/ deptno
from dept
where loc='DALLAS' );
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
★ 중요: dept 테이블이 해쉬테이블이 이 되고 있습니다. 되게 하려면 다음과 같이 sql을 작성해 줘야 됩니다.
select ename, sal
from emp
where deptno not in ( select /*+ hash_aj swap_join_inputs(dept)*/ deptno
from dept
where loc='DALLAS'
and deptno is not null)
and deptno is not null;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
39. in -> exists 튜
예제 38. in 연산자를 exists로 변경해서 튜닝할 줄 알아야 해요! : in은 다 찾아서 해쉬세미조인하시면 exists 문은 메인 쿼리의 데이터 속도가 서브쿼리에 존재하면 찾는 걸 멈춤 (속도: in < exists)
Q1. IN 연산자를 사용해서 아래의 서브쿼리문을 분석하시오.
select deptno
from dept
where deptno in (select deptno
from emp);
-- 부서번호가 여러개이기 때문에 =이면안됨
설명: 위의 문제점은 dept테이블의 deptno를 모두 emp 테이블에 가서 조인을 해서 결과를 출력함 (성능저하)- -> 테이블이 아주 크면 hash_sj로 인트를 줘도 속도가 개선되지 않음 (exists 문으로 사용)
select deptno
from dept d
where exists (select deptno
from emp e
where e.deptno =d.deptno);
문제 1. 아래 sql을 튜닝하시오.
1) 튜닝전
select count(*)
from customers200
where cust_first_name ='Abel'
and cust_id in (select cust_id from sales200);
2) 튜닝후
select count(*)
from customers200 c
where cust_first_name ='Abel'
and exists (select cust_id from sales200 s
where c.cust_id = s.cust_id);
40. minus를 not exists문으로 변경튜닝
예제 40. minus를 not exists문으로 변경 튜닝
※ 집합연산자
1. union all
2. union
3. intersect
4. minus
minus 집합연산자는 정렬작업을 일으키므로 대용량 테이블 사용 시 성능이 느려짐 (not exists 사용)
문제 1. 아래의 sql을 not exists로 변경하시오
1) 변경전 -- DEPT 테이블에는 존재하는 부서번호인데 EMP 테이블에는 존재하지 않는 부서번호를 출력해라
select deptno
from dept
minus
select deptno
from emp;
2) 변경후
select deptno
from dept d
where not exists (select deptno
from emp e
where e.deptno =d.deptno);
문제 2. 아래의 sql을 not exists로 변경하시오
1) 변경전
select telecom
from telecom_table
minus
select telecom
from emp19;
3) 변경후
select telecom
from telecom_table t
where not exists (select telecom from emp19 e
where t.telecom =e.telecom);
41. 데이터 분석함수(1)
예제 41. 데이터 분석함수를 이용해서 SQL을 재작성할 줄 알아야 해요!
1) 튜닝전
select decode( no, 1, deptno, 2, null) as deptno, sum(sal)
from emp e, ( select rownum no
from dual
connect by level <= 2 ) d
group by decode( no, 1, deptno, 2, null )
order by deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
select deptno, sum(sal)
from emp
group by rollup(deptno);
문제 1. 아래의 튜닝 후 sql 을 튜닝 전 sql로 변경하시오
1) 튜닝후
select job, sum(sal)
from emp
group by rollup(job)
order by job asc;
2) 튜닝전
select decode(no,1,job,2,null) as job , sum(sal)
from emp e, (select rownum no from dual
connect by level <=2) v
group by decode(no,1,job,2,null)
order by job;
42. 데이터분석함수(2)
예제 42. 데이터 분석함수를 이용해서 SQL을 재작성할 줄 알아야 해요! (2)
1)튜닝전
select job, deptno, null as mgr, sum(sal)
from emp
group by job, deptno
union all
select null as job, deptno, mgr, sum(sal)
from emp
group by deptno, mgr;
2) 튜닝후
select job, deptno, mgr, sum(sal)
from emp
group by grouping sets ((job,deptno),(deptno,mgr));
문제 1. 아래의 sql을 튜닝하시오.
1) 튜닝전
select job, deptno, null as mgr, sum(sal)
from emp
group by job, deptno
union all
select null as job, deptno, mgr, sum(sal)
from emp
group by deptno, mgr
union all
select to_char(null) as job, to_number(null) as deptno, to_number(null) as mgr , sum(sal)
from emp;
2) 튜닝후
Select Job, Deptno, Mgr, Sum(Sal)
From Emp
Group By Grouping Sets ((Job,Deptno),(Deptno,Mgr),());
43. 데이터분석함수(3)
예제 43. 데 이터 분석함수를 이용해서 SQL을 재작성할 줄 알아야 해요! (3)
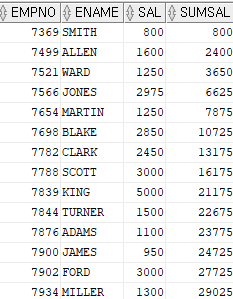
Q1. 사원번호, 이름, 월급, 월급의 누적치를 출력하시오.
1) 튜닝전
select empno, ename, sal, (select sum(sal)
from emp e
where e.empno <= b.empno ) sumsal
from emp b
order by empno;
설명:스칼라 서브쿼리가 emp 테이블의 건수만큼 반복해서 14번이 수행됨.
2) 튜닝후
select empno, ename, sal, sum(sal) over(order by empno asc) sumsal
from emp;
문제 1. 아래의 sql을 튜닝하시오.
1) 튜닝전
select deptno, empno, ename, sal, (select sum(sal) from emp e
where e.empno<=b.empno
and e.deptno = b.deptno) sumsal
from emp b
order by deptno,empno;
2) 튜닝후
select deptno, empno, ename, sal,sum(sal) over(partition by deptno order by empno asc) sumsal
from emp
order by 1;
44.데이터분석함수(4)
예제 44. 데이터 분석함수를 이용해서 SQL을 재작성할 줄 알아야 해요! (4) Q1. 아래의 sql을 튜닝하시오.
1) 튜닝전
select a.deptno , a.empno, a.ename, a.sal, b.sal
from ( select rownum no1, deptno, empno,ename, sal
from ( select deptno, empno, ename, sal
from emp
order by deptno, sal ) ) a,
( select rownum +1 no2, deptno, empno, ename, sal
from ( select deptno, empno, ename, sal
from emp
order by deptno,sal ) ) b
where a.no1 = b.no2 (+)
order by no1;
2) 튜닝후
select deptno, empno, sal, lag(sal, 1) over ( order by deptno, sal ) as sal_lag
from emp;
문제 1. 아래의 sql을 튜닝하시오
1) 튜닝전
select a.deptno , a.empno, a.ename, a.sal, b.sal
from ( select rownum no1, deptno, empno,ename, sal
from ( select deptno, empno, ename, sal
from emp
order by deptno, sal ) ) a,
( select rownum -1 no2, deptno, empno, ename, sal
from ( select deptno, empno, ename, sal
from emp
order by deptno,sal ) ) b
where a.no1 = b.no2 (+)
order by no1;
2) 튜닝후
select deptno, empno, sal, lead(sal, 1) over ( order by deptno, sal ) as sal_lag
from emp;
45.데이터분석함수(5)
예제 45. 데이터 분석함수를 이용해서 SQL을 재작성할 줄 알아야 해요! (5)
Q. 아래의 sql을 튜닝하시오 -- 직업별로 월급이 1등인 사원들을 출
1) 튜닝전
select e.empno, e.ename, e2.job,e2.max_sal
from emp e, (select job, max(sal) as max_sal
from emp
group by job) e2
where e.job =e2.job
and e.sal =e2.max_sal
order by e.empno;
설명: 위 sql의 문제점 emp 테이블을 2번 액세스함.
2) 튜닝후
SELECT empno, ename, job, sal
FROM (
SELECT
empno,
ename,
job,
sal,
RANK() OVER (PARTITION BY job ORDER BY sal DESC) AS sal_rank
FROM emp
) ranked_emps
WHERE sal_rank = 1
ORDER BY empno;
문제 1. 아래의 sql을 튜닝하시오 --부서별 평균월
1) 튜닝전
select e.deptno, e.ename, e.sal, v.avgsal
from emp e, ( select deptno, avg(sal) as avgsal
from emp
group by deptno ) v
where e.deptno = v.deptno and e.sal > v.avgsal
order by 1 asc;
SQL 진단: 1. emp 테이블을 2번 액세스(access) 했습니다. 2. 조인을 해서 결과를 출력했습니다.
SELECT deptno, ename, sal, avgsal
FROM (
SELECT
deptno, ename, sal, AVG(sal) OVER (PARTITION BY deptno) AS avgsal
FROM emp
) subquery
WHERE sal > avgsal
ORDER BY deptno ASC;
46. update 문의 튜닝방
예제 46. update 문의 튜닝방법을 잘 알아야 해요!
Q1. 사원테이블의 LOC칼럼을 DEPT 테이블을 이용해서 근무하는 부서위치로 값을 경신하시오.
1) 코딩전
update emp e
set loc= (select loc
from dept d
where e.deptno =d.deptno);
sql 진단: 업데이트 문장이 총 emp 건수만큼 수행이 되어서 14번 수행되었습니다.
1) 21c버전 튜닝
update (select e.loc as emp_loc, d.loc as dept_loc
from emp e, dept d
where e.deptno = d.deptno )
set emp_loc = dept_loc;
2) 21c버전 이전 튜닝 - dept 에 primary 제약을 걸어야함 or merge문 사용
merge into emp e
using dept d
on ( e.deptno = d.deptno )
when matched then
update set e.loc = d.loc;
문제 1. emp 테이블에 dname 칼럼을 추가하고 행당 사원의 부서명으로 값을 경신하시오.
alter table emp
add dname varchar2(20);
update (select e.dname as emp_dname , d.dname as dept_dname
from emp e, dept d
where e.deptno = d.deptno)
set emp_dname = dept_dname;
47. partition table
예제 47. 파티션 테이블이 뭔지 알아야 해요
회사에 가면 접속하는 서버가 크게 2가지?
OLTP 서버(online trasaction processing)
DW 서버( DATA WAREHOUSE)
※ 파티션 테이블의 종류 3가지
1. range 파티션 테이블
: 숫자나 날짜 칼럼을 기준으로 파티션을 분할
2. hash 파티션 테이블
: 해쉬 함수를 이용해서 오라클이 알아서 데이터 분할
3. list 파티션 테이블
: 문자 컬럼을 기준으로 파티션을 분할
create table emp_partition
partition by range(deptno)
( partition p1 values less than (20),
partition p2 values less than (30),
partition p3 values less than (40))
as
select * from emp;
문제 1. emp 테이블과 emp_partition 테이블의 검색 성능을 비교하시오! (버퍼 개수)
1) 튜닝전 -- 7개
select * from emp
where deptno =10;
2) 튜닝후 -- 3개
select * from emp_partition
where deptno = 10;
문제 2. 우리 반 테이블의 나이 칼럼을 파티션 키로 해서 파티션 테이블을 생성하시오 (20,30,40)
create table emp19_partition
partition by range(age)
( partition p1 values less than (30),
partition p2 values less than (40),
partition p3 values less than (50))
as
select * from emp19;
48. list partition
예제 48. 리스트 파티션이 뭔지 알아야 해요! : 문자형 칼럼값을 기준으로 파티션을 생성하고자 하면 리스트 파티션을 만들면 된다.
문제 1. 우리 반 테이블의 통신사를 파티션 키 칼럼으로 해서 파티션 테이블로 생성하시오.
create table emp19_partition3
partition by list(telecom)
(
partition p1 values ('sk'),
partition p2 values ('kt'),
partition p3 values ('lg'),
partition p4 values ('lg알뜰'))
as
select * from emp19;
문제 2. 이름이 이승원 학생의 모든 컬럼 데이터를 출력하는 sql 튜닝 전과 튜닝후가 있는지 확인하시오.
1) 튜닝전 --2개
select *
from emp19
where ename ='이승원';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후--8개
select *
from emp19_partition3
where ename ='이승원';
설명: 위의 sql차이가 없습니다. 왜냐면 파티션 키칼럼이 where 절에 없기 때문에 승원이 데이터를 찾으려면 모든 파티션 을 다 뒤져야 됨.
1) 튜닝전 --2개
select *
from emp19
where ename ='이승원'and telecom ='sk';
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후--2개
select *
from emp19_partition3
where ename ='이승원' and telecom ='sk';
설명: 위와 같이 파티션 키 칼럼이 where 절에 검색조건에 있어야 해당 파티션만 읽을 수 있음 위와 같이 파티션을 구성하게 되면 lg 알뜰 같은 경우는 1건밖에 없기 때문에 큰 서랍장에 1건만 들어가게 됨. 그래서 파티션만 잘 나누면 되고 데이터가 서랍장마다 골고루 들어가게만 하면 된다면 해쉬 파티션을 만들면 됩니다.
49. hash partition
예제 49. 해쉬파티션이 뭔지 알아야 해요. 파티션 테이블의 데이터 검색 성능을 높이려면 파티션 마다 골고루 데이터가 분배가 되어야됨. range로 하기에도 애매하고 list로 하기에도 애매함. 이럴땐 hash partition으로 하면됨. 대신 어느 데이터가 어느 파티션에 들어있는지도 알수는 없음
Q1. 직업을 파티션 키로 해서 해쉬 파티션테이블을 생성하시오.
create table emp19_partition2
partition by HASH(job) partitions 4
as
select * from emp;
select table_name, partition_name, num_rows
from user_tab_partitions
where lower(table_name)='emp_partition3';
문제 2. emp테이블을 hiredate 기준으로 년도별 range 파티션을 생성하시오.
p1 <--- 1980년도 데이터
p2 <--- 1981년도 데이터
p3 <--- 1982년도 데이터
p4 <--- 1983년도 데이터
p5 <--- 1984년도 포함 그 이후 데이터
create table emp_partition4
partition by range(hiredate)
( partition p1 values less than( to_date('19810101','YYYYMMDD') ),
partition p2 values less than( to_date('19820101','YYYYMMDD') ),
partition p3 values less than( to_date('19830101','YYYYMMDD') ),
partition p4 values less than( to_date('19840101','YYYYMMDD')),
partition p5 values less than( maxvalue )
)
as select * from emp;
문제 3. 81/11/17 에 입사한 사원의 모든 컬럼의 데이터를 출력하는데 emp 테이블에서 검색했을때의 버퍼 갯수 차이를 구하시오.
1) 버퍼갯수 -7개
select * from emp
where hiredate = to_date('1981/11/17' ,'RRRR/MM/DD');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 버퍼갯수 -2개
select * from emp_partition4
where hiredate = to_date('1981/11/17' ,'RRRR/MM/DD');