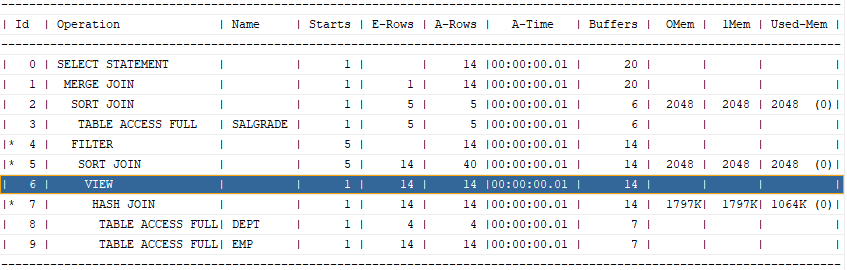
select /*+ leading(e, d,b) use_hash(d) use_hash(b) swap_join_inputs(b) */ e.ename, e.sal, d.loc,b.comm2
from emp e, dept d, bonus b
where e.deptno = d.deptno
and e.empno = b.empno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
30. 선택적 조인
예제 30. 선택적 조인을 하면서 조인의 성능을 높일 수 있다.
-- 환경구성
@demo
-- emp 테이블에 emp_kind 라는 컬럼을 추가하고 default값을 1로 해서 추가함.
-- default 값을 1로 주겠다는 것은 emp_kind 값을 입력안하면 무조건 1로 값이 할당되는 것
alter table emp
add emp_kind varchar2(1) default 1 not null;
-- 사원번호가 홀수이면 정규직으로 하고 짝수면 비정규직으로 emp_kind 수정
update emp
set emp_kind = case when mod(empno,2) = 1 then 1
else 2 end ;
select ename, emp_kind from emp;
--- emp_kind 가 1이면 정규직 , emp_kind 가 2이면 비정규직
-- 정규직 사원 테이블 생성
create table emp_kind1
as
select empno, ename, sal + 200 as office_sal
from emp
where emp_kind ='1';
-- 비정규직 사원 테이블 생성
create table emp_kind2
as
select empno, ename, sal + 200 as sal
from emp
where emp_kind ='2';
-- primary key 제약을 각각 건다
alter table emp_kind1
add constraint pk_emp_kind1 primary key(empno);
alter table emp_kind2
add constraint pk_emp_kind2 primary key(empno);
-- emp테이블에서 sal 컬럼을 삭제함
alter table emp
drop column sal ;
문제 1. emp와 emp_kind1과 emp_kind2 테이블을 조인해서 사원번호가 7389인 사원의 사원번호, 이름, 정규직 사원 월급(office_sal), 비정규직 월급(sal)을 출력하시오.
select e.empno, e.ename, k1.office_sal, k2.sal
from emp e , emp_kind1 k1 ,emp_kind2 k2
where e.empno=k1.empno (+)
and e.empno= k2.empno(+)
and e.empno=7902;
설명: 왜 위의 sql에서는 outer join 사인이 필요한가? (사인을 안 쓰면 출력이 안됨) -> 7839 사원이 정규직일지 비정규직일지 모르기 때문에 꼭 써야 됨
실행계획을 보면 비정규직 사원 테이블과도 조인을 해서 버퍼의 개수가 1 이상으로 보임 그래서 위의 sql에 정규직 사원번호가 들어오면 비정규직 테이블하고는 조인되지 않게 하고 비 정규직 사원번호가 들어오면 정규직 사원 테이블하고는 조인되지 않게 하려면 선택적 조인을 하면 됨
★문제 2. 위의 sql을 선택적 조인(상호 배타적 관계의 조인)을 하게 하시오.
select e.empno, e.ename, k1.office_sal, k2.sal
from emp e , emp_kind1 k1 ,emp_kind2 k2
where decode (e.emp_kind, 1, e.empno) = k1.empno (+)
and decode (e.emp_kind, 2, e.empno) = k2.empno(+)
and e.empno=7839;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
★문제 3. 아래의 환경을 만들고 아래 SQL을 상호 배타적 관계 조인이 되게 튜닝하시오
@demo
drop table dept_10;
drop table dept_20;
drop table dept_30;
create table dept_10
as
select empno, sal*0.1 bonus_10
from emp
where deptno = 10;
create table dept_20
as
select empno, sal*0.2 bonus_20
from emp
where deptno = 20;
create table dept_30
as
select empno, sal*0.3 bonus_30
from emp
where deptno = 30;
alter table dept_10
add constraint dept_10_pk primary key(empno);
alter table dept_20
add constraint dept_20_pk primary key(empno);
alter table dept_30
add constraint dept_30_pk primary key(empno);
1) 튜닝전
select e.empno, e.ename, d1.bonus_10, d2.bonus_20, d3.bonus_30
from emp e, dept_10 d1, dept_20 d2, dept_30 d3
where e.empno = d1.empno (+)
and e.empno = d2.empno (+)
and e.empno = d3.empno (+)
and e.empno = 7788;
2) 튜닝후
select e.empno, e.ename, d1.bonus_10, d2.bonus_20, d3.bonus_30
from emp e, dept_10 d1, dept_20 d2, dept_30 d3
where decode( e.deptno, 10,e.empno) = d1.empno (+)
and decode( e.deptno,20,e.empno) = d2.empno (+)
and decode( e.deptno,30,e.empno) = d3.empno (+)
and e.empno = 7788;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: 사원번호가 7788번인 사원은 부서번호가 20번이므로 조인연결 조건 중에 decode(e.deptno,20, empno) =d2.empno(+)만 작동이 되고 나머지는 0이 됨.
31. 인라인 조인 해체 되지 않게 하시오. ( no merge )
예제 31. 인라인 뷰와 조인할 때 인라이뉴가 해체되지 않게 하시오. (no merge)
설명: 위의 sql의 조인 순서는 salgrade -> in line view 순이야 하는데 query transformer가 in line view를 아래와 같이 해체해 버림
select e.ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno and e.sal between s.losal and s.hisal ;
-- in line view 를 해체하지 못하게 하시오 !
select /*+ no_merge(v) */ v.ename, v.loc, s.grade
from salgrade s, ( select /*+ no_merge */ e.ename, e.sal, d.loc
from emp e, dept d
where e.deptno = d.deptno ) v
where v.sal between s.losal and s.hisal ;
-- 위 2개 /*+ no_merge(v) */ 중 1개만 써도 됨
1. no_merge 힌트 : 인라인 뷰나 뷰를 해체하지 말아라 !
2. merge : 인라인 뷰나 뷰를 해체해라 !
문제1. 아래의 sql의 inline view가 해체되지 않도록 힌트를 주시오.
1) 튜닝전
select v.ename, v.sal, v.grade, d.loc
from dept d, (select e.ename, e.sal, s.grade, e.deptno
from emp e , salgrade s
where sal between s.losal and s.hisal) v
where v.deptno=d.deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
select /*+ no_merge(v) */v.ename, v.sal, v.grade, d.loc
from dept d, (select e.ename, e.sal, s.grade, e.deptno
from emp e , salgrade s
where sal between s.losal and s.hisal) v
where v.deptno=d.deptno;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
32. 조인 순서 조
예제 32. 뷰와 조인을 할 대 조인 순서를 조정할 수 있다.
-- 환경설정
create view emp_dept
as
select e.ename, e.sal, d.loc, e.deptno
from emp e ,dept d
where e.deptno =d.deptno;
1) 튜닝전 -- 뷰가 해체됨
select v.ename, v.sal, v.loc, s.grade
from emp_dept v, salgrade s
where v.sal between s.losal and s.hisal;
2) 튜닝후
select /*+ no_merge(v) */v.ename, v.sal, v.loc, s.grade
from emp_dept v, salgrade s
where v.sal between s.losal and s.hisal;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
Q2. 의 조인 순서를 아래와 같이되게 하시오.
조인순서: 인라인뷰 v ----> salgrade 조인방법: nested loop 조인
select /*+ no_merge(v) leading(v,s) use_nl(s)*/v.ename, v.sal, v.loc, s.grade
from emp_dept v, salgrade s
where v.sal between s.losal and s.hisal;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명 : 위의 실행계획이 나오려면 인라인 뷰를 해체하지 않게 no_merge 힌트를 먼저 사용해줘야됨.
★ Q3. 위의 sql의 조인순서를 변경하는데 emp_dept뷰 안의 조인순서가 emp -> dept 순이 되게 하고 조인방법은 nested loop 조인이 되게하시오.
select /*+ no_merge(v) leading(v,s) use_nl(s)
leading(v.e,v.d) use_nl(v.d)*/v.ename, v.sal, v.loc, s.grade
from emp_dept v, salgrade s
where v.sal between s.losal and s.hisal;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
33. MVIEW
예제 33. 조인 성능을 높이고 싶다면 MVIEW 생성을 고려하시오. 일반 VIEW는 데이터를 저장하고 있지 않은데 materialize view 는 데이터를 저장하는 view 입니다.
Q1. 아래와 같이 VIEW를 생성하시오.
create view emp_dept2
as
select d.loc, sum(e.sal) as sumsal
from emp e , dept d
where e.deptno=d.deptno
group by d.loc;
select * from emp_dept2;
설명: view는 데이터를 저장하지 않고 바라만 봄.
Q2. emp_dept3로 위의 결과를 담아내는 MVIEW를 생성하시오.
create materialized view emp_dept3
as
select d.loc, sum(e.sal) as sumsal
from emp e , dept d
where e.deptno=d.deptno
group by d.loc;
설명: emp_dept3 mview를 만들기 위해 20분이 걸렸다고 가정해봅시다. 그러면 앞으로 emp_dept3 를 조회할때는 20분이 걸리지 않고 3건밖에 안되기 때문에 금방조회됩니다. 왜냐면 3건의 데이터를 저장하고 있기 때문입니다. 그러나 emp_dept2 같은 경우는 매번 select * from emp_dept2; 를할 때마다 20분이 걸릴겁니다. 왜냐면 결과 데이터가 저장되지 않기 때문입니다. 그래서 매번 조인해야합니다.
문제 1. emp와 dept, salgrade를 조인해서 dallas에서 근무하는 사원들의 이름,월급,부서위치,급여등급을 출력하는 쿼리문이 20분 이상 돈다고 가정하고 이 결과를 빠르게 보기 위해서 mview생성하시오. mview는 emp_dept_salgrade로 하시오 1) MARERIALIZED VIEW - buffer 2개
create materialized view emp_dept_salgrade
as
select e.ename, e.sal, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and e.sal between s.losal and s.hisal
and d.loc='DALLAS';
2. 일반 VIEW - buffer 20개
create view emp_dept_salgrade2
as
select e.ename, e.sal, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and e.sal between s.losal and s.hisal
and d.loc='DALLAS';
select * from emp_dept_salgrade2;
설명: 일반 뷰는 데이터를 저장하고 있지 않으므로 다시 조인합니다. 그래서 20개의 버퍼를 읽어들이고 있습니다.
문제 2. 다음과 같이 일반뷰인 emp_dept_salgrade2를 drop 하고 다음과 같이 rewrite 힌트를 써서 아래의 조인문의 실행계획을 확인하시오.
drop view emp_dept_salgrade2;
create materialized view emp_dept_salgrade3
enable query rewrite
as
select e.ename, e.sal, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and e.sal between s.losal and s.hisal
and d.loc='DALLAS';
설명: 위와 같이 하면 조인을 하지 않고 mview의 데이터를 읽습니다.
문제 3. 다음과 같이 mveiw 를생성하시오 !
create materialized view dept_sal
build immediate -- mview 생성과 동시에 결과 데이터로 생성되는 옵션
refresh
complete
on demand -- mview 와 테이블간의 데이터 동기화를 요구할 때만 동기화
enable query rewrite -- 아래의 쿼리무ㄴ만 수행해도 mview의 데이터를 가져오게 함
as
select d.dname, sum(e.sal) as sumsal
from emp e, dept d
where e.deptno = d.deptno
group by d.dname;
select * from dept_sal;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
select d.dname, sum(e.sal) as sumsal
from emp e, dept d
where e.deptno = d.deptno
group by d.dname;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
※ 1. rewrite 힌트 : mview 에서 데이터를 가져와라 ! 2. no_rewrite 힌트: 테이블에서 데이터를 가져와라 !
문제 4. 다음의 sql을 mview로 만들고 query rewrite가 될 수 있도록 하시오.(view 이름 emp_mview75)
create materialized view emp_mview75
enable query rewrite
as
select e.ename, d.loc, e.sal
from emp e, dept d
where e.deptno = d.deptno;
select * from emp_mview75;
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
34. 데이터가 작은 서브쿼리 수행
예제 34. 서브쿼리문에서 서브쿼리의 데이터가 작으면 서브쿼리부터 수행되게 해야해요. Q1. JONES 보다 더 많은 월급을 받은 사원들의 이름과 월급을 출력하시오.
select ename, sal
from emp
where sal > (select sal
from emp
where ename='JONES');
- 서브쿼리부터 수행되는게 성능에 더 좋음(서브쿼리의 데이터가 1건이기 떄문)
Q2. 위의 SQL의 실행계획을 확인해서 서브쿼리부터 수행했는지 확인하시오.
select ename, sal
from emp
where sal > (select sal
from emp
where ename='JONES');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
실행계획을 보면 서브쿼리를 먼저 수행하고 나서 메인쿼리를 수행햇습니다.
Q3. 똑같은 결과가 나오는거면 조인이 더 속도가 빠른가요? 아니면 서브쿼리가 더 빠른가요 ? (증명하시오)
1) JOIN 전
select ename, sal
from emp
where deptno = ( select deptno
from dept
where loc='DALLAS');
2) JOIN 후
select e.ename, e.sal
from emp e, dept d
where e.deptno = d.deptno and d.loc='DALLAS';
-> 두개중에 어떤게 빠르디고 얘기할 수 없음 (왜냐하면 나는 서브쿼리 수행했지만 오라클이 조인으로 변경해서 수행할 수 있기 때문입니다. )
문제 1.아래의 sql의 실행계획을 확인해서 서브쿼리를 먼저 수행했는지 메인쿼리를 먼저수행했는지 확인하시오.
select ename, sal
from emp
where deptno = ( select deptno
from dept
where loc='DALLAS');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제 2. 아래의 sql의 실행계획을 확인하시오.
select ename, sal
from emp
where deptno in ( select deptno
from dept
where loc='DALLAS');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
설명: =을 in으로 변경했더니 join으로 수행 (서브쿼리로 수행하려면 in 이 아니라 =로 작성해야함)
문제 3. . 아래의 SQL이 메인 쿼리부터 수행되게하시오
select /*+ gather_plan_statistics */ ename, sal
from emp
where deptno = ( select deptno
from dept
where loc='DALLAS' );
답:
select /*+ gather_plan_statistics */ ename, sal
from emp
where deptno = ( select /*+ no_push_subq */ deptno
from dept
where loc='DALLAS' );
no_unnest 를 써서 서브쿼리로 실행되게 해야 서브쿼리부터 수행되게 하라고 하는 push_subq힌트가 의미가 있고 no_push_subq를 써서 메인 쿼리부터 수행되게해라라는 의미가 있는 것임.
문제 1. 아래의 sql이 서브쿼리부터 수행되게 하시오.
select ename, sal
from emp
where deptno in(select deptno
from dept
where loc ='NEW YORK');
답)
select /*+ gather_plan_statistics */ ename, sal
from emp
where deptno in ( select /*+ no_unnest push_subq */ deptno
from dept
where loc = 'NEW YORK' );
문제 2. 위의 sql을 메인쿼리부터 수행되게 하시오.
select ename, sal
from emp
where deptno in ( select /*+ no_unnest no_push_subq */ deptno
from dept
where loc = 'NEW YORK' );
문제 3. 아래 sql을 튜닝하시오.
튜닝전: select count(*)
from sales200
where cust_id in ( select /*+ no_unnest no_push_subq */ cust_id
from customers200
where cust_first_name='Abel' );
튜닝후: select count(*)
from sales200
where cust_id in ( select /*+ no_unnest push_subq */ cust_id
from customers200
where cust_first_name='Abel' );
튜닝후도 40초 넘게 걸리지만 main query 부터 수행하는것보다는 빠르게 결과가
출력이 됩니다.
위와 같이 튜닝 전이나 튜닝후나 결과가 느리게 출력된다면 서브쿼리로 수행하면 안되고 세미 조인으로 수행되게 해줘야됨.
36. semi join
예제 36. 서브쿼리를 세미조인으로 변경해서 수행되게 하세요 ! :서브쿼리 문장을 튜닝할 때 push_subq 와 no_push_subq 힌트로는 튜닝이 안될때 세미조인을 사용해야함 세미 조인은 기본적으로 메인쿼리의 테이블부터 먼저 드라이빙됨. 그렇지만 조인이기 때문에 조인방법중 아주 강력한 해쉬조인을 사용할 수 있음.
문제1.아래 sql을 튜닝하시오.
1) 튜닝전
select count(*)
from sales200
where cust_id in (select /*+ no_unnest push_suqb */ cust_id
from customers200
where cust_first_name='Abel');
2) 튜닝후
select count(*)
from sales200
where cust_id in (select /*+ unnest hash_sj */ cust_id
from customers200
where cust_first_name='Abel');
※ unnest힌트는 서브쿼리를 조인으로 수행해라 라는 힌트이고 세미조인의 종류가 3가지임
1. nl_sj
nested loop semi 조인
★ 2. hash_sj
hash semi 조인
3. merger_sj
sort merge semi 조인
문제 2. 아래 sql의 실행계획이 hash semi 조인이 되 튜닝하시오.
1) 튜닝전
select ename, sal
from emp
where deptno in(select /*+ no_unnest no_push_subq */ deptno
from dept
where loc ='DALLAS');
2) 튜닝후
select ename, sal
from emp
where deptno in(select /*+ unnest hash_sj */ deptno
from dept
where loc ='DALLAS');
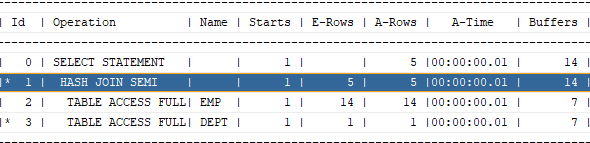
37. swap_join_inputs
예제 37. 해쉬 세미 조인도 서브쿼리부터 수행되게 할 수 있다. 해쉬 세미조인은 원래 메인쿼리의 테이블을 해쉬 테이블로 구성할 수 밖에없는거였는데 swap_join_inputs 힌트가 나오면서 서브쿼리의 테이블도 해쉬 테이블로 구성할 수 있게 되었습니다.
1) 튜닝전
select ename, sal
from emp
where deptno in (select deptno
from dept
where loc ='DALLAS');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
2) 튜닝후
select ename, sal
from emp
where deptno in (select /*+ unnest hash_sj swap_join_inputs(dept) */ deptno
from dept
where loc ='DALLAS');
select * from table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
1) 튜닝전
select count(*)
from sales200
where cust_id in (select /*+ unnest hash_sj */ cust_id
from customers200
where cust_first_name='Abel');
2) 튜닝후
select count(*)
from sales200
where cust_id in (select /*+ unnest hash_sj swap_join_inputs( customers200) */ cust_id
from customers200
where cust_first_name='Abel');
★ 마지막문제. 아래의 sql을 해쉬 세미조인이 되게 튜닝하시오. 작은 테이블이 해쉬테이블이 되게하시오.
1) 튜닝전
select count(*)
from customers200
where cust_id in ( select /*+ no_unnest push_subq */ cust_id
from sales200
where amount_sold between 1 and 10000);
2) 튜닝후
select count(*)
from customers200
where cust_id in ( select /*+ unnest hash_sj swap_join_inputs(sales200) */ cust_id
from sales200
where amount_sold between 1 and 10000);
답)
select count(*)
from customers200
where cust_id in ( select /*+ unnest hash_sj swap_join_inputs(customers200) */ cust_id
from sales200
where amount_sold between 1 and 10000);