#1. train200 이라는 폴더를 코렙에 생성하시오
/content/drive/MyDrive/pretty 폴더 밑에 생성
# 2. 코렙에 올린 사진 압축파일의 압축을 풉니다.
!unzip -uq /content/drive/MyDrive/pretty/image_all.zip -d /content/drive/MyDrive/pretty/train200
#3. train_resize 라는 폴더를 만듭니다.
!mkdir /content/drive/MyDrive/pretty/train_resize
#4. 32x32 로 사진들을 전부 resize 합니다.
#1. 훈련 이미지를 resize 합니다.
import cv2
import os
import numpy as np
path = "/content/drive/MyDrive/pretty/train200" # 원본위치
file_list = os.listdir(path) # 파일이름 불러오는 부분
for k in file_list: # 리스트안에 있는 파일들을 하나씩 빼내는 코드
img = cv2.imread(path + '/' + k) # 이미지 데이터를 행렬로 숫자로 변환합니다.
resize_img = cv2.resize(img, (32 , 32), interpolation=cv2.INTER_CUBIC)
cv2.imwrite( '/content/drive/MyDrive/pretty/train_resize/' + k, resize_img)
# train_resize 에 resize 된 이미지들이 몇개가 있는지 확인합니다.
!ls /content/drive/MyDrive/pretty/train_resize | wc -l
#5. 정답 csv 파일을 생성합니다.
# 수지를 0번으로하고 설현을 1번으로 하겠습니다.
path='/content/drive/MyDrive/pretty/train_label.csv'
file = open( path, 'w' )
# 숫자 0을 100개 , 숫자 1을 100개 씁니다.
for i in range( 1, 101 ):
file.write( str(0) + '\n' )
for i in range( 101, 201 ):
file.write( str(1) + '\n' )
file.close()
#6. 어제 만들었던 image_load 함수와 label_load 함수를 생성하시오 !
train_images='/content/drive/MyDrive/pretty/train_resize'
import os
import re
import cv2
def image_load(path):
#1. 사진 파일명에서 숫자부분만 취합니다.
file_list = os.listdir(path) # path 디렉토리에 파일명들을 불러옵니다.
file_name = []
for i in file_list:
a = int( re.sub('[^0-9]', '', i ) ) # i 가 숫자가 아니라면 null 로 변경해라
file_name.append(a)
file_name.sort()
#2. 디렉토리와 숫자 파일명을 이어 붙입니다.
file_res = [ ]
for j in file_name:
file_res.append( path + '/' + str(j) + '.jpg') # 전체 경로 + 파일명을 생성
#3. 위에서만든 디렉토리와 파일명을 가지고 사진을 숫자로 변경합니다.
image= [ ]
for k in file_res:
img = cv2.imread(k) # 이미지를 숫자로 변경합니다.
image.append(img)
return np.array(image)
print ( image_load(train_images) )
from tensorflow.keras.utils import to_categorical
import csv
import numpy as np
train_label = '/content/drive/MyDrive/pretty/train_label.csv'
def label_load(path):
file = open(path)
labeldata = csv.reader(file)
labellist = [ ]
for i in labeldata:
labellist.append(i)
label = np.array( labellist ) # 넘파이 배열로 변환
label = label.astype(int) # 숫자로 변환
label = to_categorical(label) # [ 1, 0] 또는 [0, 1] 로 one hot encoding 합니다.
return label
print ( label_load(train_label) )
#7. 모델 평가하기
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten ,BatchNormalization,Dropout # CNN, 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
tf.random.set_seed(777)
# 이파리 데이터를 가져오는 코드
train_images='/content/drive/MyDrive/pretty/train_resize'
train_label = '/content/drive/MyDrive/pretty/train_label.csv'
x_train = image_load( train_images)
y_train = label_load(train_label)
# 2. 정규화를 진행합니다.
x_train = x_train / 255.0
print(x_train.shape) # (4000, 32, 32, 3)
# 3. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(32,32,3), padding='same', activation='relu') )
model.add(MaxPooling2D(pool_size=(2,2), padding='same') ) # 이미지를 선명하게 해주는 층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Flatten() ) # 완전연결계층에 들어갈수 있도록 이미지(피쳐맵들)를 1차원으로 변경합니다.
model.add(Dense(50, activation = 'relu')) # 1층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(50, activation = 'relu') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense( 2, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='Adam',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
#6. 모델을 훈련시킵니다.
history = model.fit(x_train, y_train,
epochs = 200, # 30에폭
batch_size = 10 )
# 7.모델을 평가합니다. (오차, 정확도가 출력됩니다.)
#model.evaluate(x_test, y_test)
model.save('/content/drive/MyDrive/pretty/suji_model.h5')
예제2. 코렙에서 여러분들이 생성한 모델을 로컬 컴퓨터로 다운로드 받아 c 드라이브 밑에 data10 폴더 밑에 둡니다. 로컬 주피터 노트북에서 다운 받은 모델을 불러옵니다.
from tensorflow.keras.models import load_model # 만들어진 모델을 불러오는 함수
new_model = load_model('c:\\data10\\suji_model.h5')
new_model
사진 한장을 모델에 넣고 잘 예측하는지 확인합니다.
# 1. 필요한 패키지를 불러옵니다.
import tensorflow as tf
import cv2
import numpy as np # NumPy 패키지 불러오기
# 설명: cv2 가 없다고 나오면 다음과 같이 설치합니다.
#!pip install opencv-python
# 2. 이미지를 숫자로 변환합니다.
file_path='C:\\image_all\\1.jpg'
img = cv2.imread(file_path) # 이미지를 숫자로 변환하는 코드
img
# 3. 32 x 32 로 reshape 합니다.
import matplotlib.pyplot as plt
resize_img = cv2.resize( img, (32, 32), interpolation = cv2.INTER_CUBIC)
# 4. 학습 시킨 모델 불러오는 코드
from tensorflow.keras.models import load_model
new_model = load_model('c:\\data10\\suji_model.h5')
# 5. 리사이즈한 사진을 4차원으로 변경하고 정규화 작업을 수행
x4 = tf.reshape(resize_img,(1,32,32,3))
x4 = x4/255 # 정규화
# 6. 모델에 이미지 넣고 예측을 합니다.
results = new_model.predict(x4)
a = np.argmax(results) # [0.6, 0.4] ---> 0, [ 0.2, 0.8 ] ---> 1
print(a)
# 7. 0번이면 '수지', 1번이면 '설현'으로 매칭해줍니다.
target_dict = {
0: '수지',
1: '설현'
}
print(target_dict[a])
# 8. 시각화 합니다.
image = cv2.imread(file_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image)
plt.axis('off') # 축과 눈금 숨기기
plt.show()
예제. 화면 개발을 위한 패키지들을 임폴트해서 오류가 나는지 확인합니다.
# 게임화면 또는 특정 목적의 사용자 인터페이스를 구현 할 수 있는 tkinter 모듈을 임폴트 받습니다.
import tkinter as tk
from tkinter import filedialog
from tkinter import *
import numpy as np
# 이미지 데이터 전처리하는 모듈과 텐써 플로우 케라스 load_model 모듈을 임폴트 합니다.
from PIL import ImageTk, Image
import numpy as np
from keras.models import load_model
import cv2
# 화면을 띄웁니다.
top=tk.Tk() # tkinter 의 Tk 클래스를 이용해서 top 이라는 객체를 만듭니다.
top.geometry('800x600') # 사용자 화면 가로 세로 사이즈를 지정합니다.
top.title('수지와 설현 분류 Classification') # 맨 위에 막대에 제목을 적어줍니다.
top.configure(background='#CDCDCD') # 맨위에 막대에 색깔을 회색으로 지정합니다.
label=Label(top,background='#CDCDCD', font=('arial',15,'bold'))
sign_image = Label(top)
def classify(file_path):
#1. 필요한 패키지를 불러옵니다.
import tensorflow as tf
import cv2
#2. 이미지가 있는 위치를 지정합니다.
img = cv2.imread(file_path) # 이미지를 숫자로 변환하는 코드
#img = cv2.bitwise_not(img)
#3. 28x 28 로 reshape 합니다.
import matplotlib.pyplot as plt
resize_img = cv2.resize( img, (32, 32), interpolation = cv2.INTER_CUBIC)
#4. 다음 코드를 이용해서 흑백으로 변경합니다.
import numpy as np
#x2 =tf.image.rgb_to_grayscale(resize_img)
# 5. 학습 시킨 모델 불러오는 코드
from tensorflow.keras.models import load_model
new_model = load_model('c:\\data10\\suji_model.h5')
x4 = tf.reshape(resize_img,(1,32,32,3)) # 컬러 사진을 인식할 수 있게 사이즈 설정
x4 = x4/255 # 정규화
results = new_model.predict(x4)
a= np.argmax(results)
#7. 9번의 상품이 뭔지 확인하기
target_dict = {
0: '수지',
1: '설현'
}
sign = target_dict[a]
label.configure(foreground='#011638', text=sign)
def show_classify_button(file_path): # 분류하는 버튼을 구현하는 함수
classify_b=Button(top,text="Classify Image",
command=lambda: classify(file_path), padx=10,pady=5)
classify_b.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
classify_b.place(relx=0.79,rely=0.46)
def upload_image(): # 이미지를 업로드하는 버튼을 구현하는 함수
try:
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/2.25),(top.winfo_height()/2.25)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
show_classify_button(file_path)
except:
pass
# 위에서 만든 함수들을 가지고 실행하는 코드들
upload=Button(top,text="Upload an image",command=upload_image,padx=10,pady=5)
upload.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
upload.pack(side=BOTTOM,pady=50)
sign_image.pack(side=BOTTOM,expand=True)
label.pack(side=BOTTOM,expand=True)
heading = Label(top, text="수지와 설현 분류",pady=20, font=('arial',20,'bold'))
heading.configure(background='#CDCDCD',foreground='#364156')
heading.pack()
top.mainloop()
문제. 직접 이미지를 웹스크롤링 해서 신경망을 만듭니다.(티니핑)
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 크롬 드라이버의 위치 지정후 driver 객체를 생성
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 구글 이미지 검색 페이지로 이동
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&ei=l1AdWbegOcra8QXvtr-4Cw&ved=0EKouCBUoAQ")
# 검색창 객체 생성
search = driver.find_element(By.XPATH, "//*[@class='gLFyf']")
# 검색어 입력
name = '푸바오'
search.send_keys(name)
# 엔터 입력
search.submit()
# 스크롤을 아래로 내려서 이미지를 더 로드
for i in range(1, 9):
driver.find_element(By.XPATH, "//body").send_keys(Keys.END)
time.sleep(10)
# 결과 더보기 클릭 (버튼이 있는 경우에만)
try:
driver.find_element(By.XPATH, "//*[@class='mye4qd']").click()
# 결과 더보기를 눌렀으니 마우스를 다시 아래로 내림
for i in range(1, 9):
driver.find_element(By.XPATH, "//body").send_keys(Keys.END)
time.sleep(10)
except Exception as e:
print("결과 더보기 버튼이 없습니다. 다음 단계로 넘어갑니다.")
# 현재 페이지의 HTML 코드를 가져옴
html = driver.page_source
soup = BeautifulSoup(html, "lxml")
# 이미지 URL들을 params 리스트에 담기
params_g = []
imgList = soup.find_all("g-img", class_="mNsIhb")
for g_img in imgList:
img_tag = g_img.find("img") # g-img 태그 내의 img 태그를 찾음
if img_tag:
img_url = img_tag.get("src", img_tag.get("data-src"))
params_g.append(img_url)
# 결과 확인
#print(params_g)
# 이미지들을 로컬 디렉토리에 저장
for idx, p in enumerate(params_g, 1):
if p:
urllib.request.urlretrieve(p, "c:\\data_image2\\" + str(idx) + ".jpg")
else:
print(f"이미지 {idx}는 다운로드할 수 없습니다.")
C:\gorani
특정폴더에 있는 사진의 번호를 다시 1번부터 100번까지 다시 이름을 짓는 파이썬 코드를 수행합니다.
c 드라이브 밑에 gorani2 라는 폴더를 미리 생성해둡니다.
import os
import shutil # 파일을 다른 폴더로 이동하기 위해 사용
# 원본 폴더 경로
source_folder = 'C:\\gorani'
# 새로 이동할 폴더 경로
destination_folder = 'C:\\gorani2'
# 이동할 폴더가 존재하지 않으면 생성
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
# 파일 목록 가져오기
file_list = os.listdir(source_folder)
# 파일 목록 정렬 (숫자로 된 파일명일 경우를 대비)
file_list.sort()
# 번호를 매겨 파일명 변경 및 이동
for idx, filename in enumerate(file_list, 1):
# 파일 확장자 확인
ext = os.path.splitext(filename)[1] # ex) .jpg, .png
# 새 파일명 생성 (1.jpg, 2.jpg, ..., 100.jpg)
new_filename = f"{idx}{ext}"
# 기존 파일 경로와 새 파일 경로 설정
src = os.path.join(source_folder, filename)
dst = os.path.join(destination_folder, new_filename)
# 파일 이동 및 이름 변경
shutil.move(src, dst)
print("파일 이동 및 이름 변경 완료!")
다음 너구리 사진을 다운받기 위해 c 드라이브 밑에 data_image3 폴더를 만듭니다. 그리고 너구리 사진을 웹스크롤링합니다.
그 다음 nuguri 와 nuguri2 라는 폴더는 만듭니다.
잘나온 사진 100장을 nuguri 폴더에 선별합니다.
그리고 nuguri2 에 101~200번까지 번호를 붙여 옮깁니다.
mport os
import shutil # 파일을 다른 폴더로 이동하기 위해 사용
# 원본 폴더 경로
source_folder = 'C:\\nuguri'
# 새로 이동할 폴더 경로
destination_folder = 'C:\\nuguri2'
# 이동할 폴더가 존재하지 않으면 생성
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
# 파일 목록 가져오기
file_list = os.listdir(source_folder)
# 파일 목록 정렬 (숫자로 된 파일명일 경우를 대비)
file_list.sort()
# 번호를 매겨 파일명 변경 및 이동 (101부터 200까지 부여)
for idx, filename in enumerate(file_list, 101):
# 파일 확장자 확인
ext = os.path.splitext(filename)[1] # ex) .jpg, .png
# 새 파일명 생성 (101.jpg, 102.jpg, ..., 200.jpg)
new_filename = f"{idx}{ext}"
# 기존 파일 경로와 새 파일 경로 설정
src = os.path.join(source_folder, filename)
dst = os.path.join(destination_folder, new_filename)
# 파일 이동 및 이름 변경
shutil.move(src, dst)
print("파일 이동 및 이름 변경 완료!")
path='/content/drive/MyDrive/pretty3/train_label.csv'
file = open( path, 'w' )
# 숫자 0을 100개 , 숫자 1을 100개 씁니다.
for i in range( 1, 101 ):
file.write( str(0) + '\n' )
for i in range( 101, 201 ):
file.write( str(1) + '\n' )
file.close()
train_images='/content/drive/MyDrive/pretty3/train_resize'
import os
import re
import cv2
def image_load(path):
#1. 사진 파일명에서 숫자부분만 취합니다.
file_list = os.listdir(path) # path 디렉토리에 파일명들을 불러옵니다.
file_name = []
for i in file_list:
a = int( re.sub('[^0-9]', '', i ) ) # i 가 숫자가 아니라면 null 로 변경해라
file_name.append(a)
file_name.sort()
#2. 디렉토리와 숫자 파일명을 이어 붙입니다.
file_res = [ ]
for j in file_name:
file_res.append( path + '/' + str(j) + '.jpg') # 전체 경로 + 파일명을 생성
#3. 위에서만든 디렉토리와 파일명을 가지고 사진을 숫자로 변경합니다.
image= [ ]
for k in file_res:
img = cv2.imread(k) # 이미지를 숫자로 변경합니다.
image.append(img)
return np.array(image)
print ( image_load(train_images) )
from tensorflow.keras.utils import to_categorical
import csv
import numpy as np
train_label = '/content/drive/MyDrive/pretty3/train_label.csv'
def label_load(path):
file = open(path)
labeldata = csv.reader(file)
labellist = [ ]
for i in labeldata:
labellist.append(i)
label = np.array( labellist ) # 넘파이 배열로 변환
label = label.astype(int) # 숫자로 변환
label = to_categorical(label) # [ 1, 0] 또는 [0, 1] 로 one hot encoding 합니다.
return label
print ( label_load(train_label) )
#7. 모델 평가하기
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten ,BatchNormalization,Dropout # CNN, 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
tf.random.set_seed(777)
# 이파리 데이터를 가져오는 코드
train_images='/content/drive/MyDrive/pretty3/train_resize'
train_label = '/content/drive/MyDrive/pretty3/train_label.csv'
x_train = image_load( train_images)
y_train = label_load(train_label)
# 2. 정규화를 진행합니다.
x_train = x_train / 255.0
print(x_train.shape) # (4000, 32, 32, 3)
# 3. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(32,32,3), padding='same', activation='relu') )
model.add(MaxPooling2D(pool_size=(2,2), padding='same') ) # 이미지를 선명하게 해주는 층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Flatten() ) # 완전연결계층에 들어갈수 있도록 이미지(피쳐맵들)를 1차원으로 변경합니다.
model.add(Dense(50, activation = 'relu')) # 1층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(50, activation = 'relu') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense( 2, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='Adam',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
#6. 모델을 훈련시킵니다.
history = model.fit(x_train, y_train,
epochs = 200, # 30에폭
batch_size = 10 )
# 7.모델을 평가합니다. (오차, 정확도가 출력됩니다.)
#model.evaluate(x_test, y_test)
model.save('/content/drive/MyDrive/pretty3/panda.h5')
# 1. 필요한 패키지를 불러옵니다.
import tensorflow as tf
import cv2
import numpy as np # NumPy 패키지 불러오기
# 설명: cv2 가 없다고 나오면 다음과 같이 설치합니다.
#!pip install opencv-python
# 2. 이미지를 숫자로 변환합니다.
file_path='C:\\image_all2\\1.jpg'
img = cv2.imread(file_path) # 이미지를 숫자로 변환하는 코드
img
# 3. 32 x 32 로 reshape 합니다.
import matplotlib.pyplot as plt
resize_img = cv2.resize( img, (32, 32), interpolation = cv2.INTER_CUBIC)
# 4. 학습 시킨 모델 불러오는 코드
from tensorflow.keras.models import load_model
new_model = load_model('c:\\data10\\panda.h5')
# 5. 리사이즈한 사진을 4차원으로 변경하고 정규화 작업을 수행
x4 = tf.reshape(resize_img,(1,32,32,3))
x4 = x4/255 # 정규화
# 6. 모델에 이미지 넣고 예측을 합니다.
results = new_model.predict(x4)
a = np.argmax(results) # [0.6, 0.4] ---> 0, [ 0.2, 0.8 ] ---> 1
print(a)
# 7. 0번이면 '수지', 1번이면 '설현'으로 매칭해줍니다.
target_dict = {
0: '푸바오',
1: '랫서판다'
}
print(target_dict[a])
# 8. 시각화 합니다.
image = cv2.imread(file_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image)
plt.axis('off') # 축과 눈금 숨기기
plt.show()
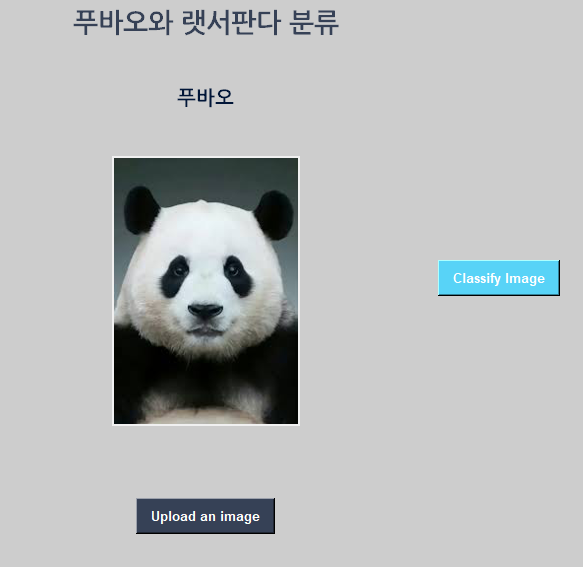
# 게임화면 또는 특정 목적의 사용자 인터페이스를 구현 할 수 있는 tkinter 모듈을 임폴트 받습니다.
import tkinter as tk
from tkinter import filedialog
from tkinter import *
import numpy as np
# 이미지 데이터 전처리하는 모듈과 텐써 플로우 케라스 load_model 모듈을 임폴트 합니다.
from PIL import ImageTk, Image
import numpy as np
from keras.models import load_model
import cv2
# 화면을 띄웁니다.
top=tk.Tk() # tkinter 의 Tk 클래스를 이용해서 top 이라는 객체를 만듭니다.
top.geometry('800x600') # 사용자 화면 가로 세로 사이즈를 지정합니다.
top.title('푸바오와 랫서판다 분류 Classification') # 맨 위에 막대에 제목을 적어줍니다.
top.configure(background='#CDCDCD') # 맨위에 막대에 색깔을 회색으로 지정합니다.
label=Label(top,background='#CDCDCD', font=('arial',15,'bold'))
sign_image = Label(top)
def classify(file_path):
#1. 필요한 패키지를 불러옵니다.
import tensorflow as tf
import cv2
#2. 이미지가 있는 위치를 지정합니다.
img = cv2.imread(file_path) # 이미지를 숫자로 변환하는 코드
#img = cv2.bitwise_not(img)
#3. 28x 28 로 reshape 합니다.
import matplotlib.pyplot as plt
resize_img = cv2.resize( img, (32, 32), interpolation = cv2.INTER_CUBIC)
#4. 다음 코드를 이용해서 흑백으로 변경합니다.
import numpy as np
#x2 =tf.image.rgb_to_grayscale(resize_img)
# 5. 학습 시킨 모델 불러오는 코드
from tensorflow.keras.models import load_model
new_model = load_model('c:\\data10\\panda.h5')
x4 = tf.reshape(resize_img,(1,32,32,3)) # 컬러 사진을 인식할 수 있게 사이즈 설정
x4 = x4/255 # 정규화
results = new_model.predict(x4)
a= np.argmax(results)
#7. 9번의 상품이 뭔지 확인하기
target_dict = {
0: '푸바오',
1: '랫서판다'
}
sign = target_dict[a]
label.configure(foreground='#011638', text=sign)
def show_classify_button(file_path): # 분류하는 버튼을 구현하는 함수
classify_b=Button(top,text="Classify Image",
command=lambda: classify(file_path), padx=10,pady=5)
classify_b.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
classify_b.place(relx=0.79,rely=0.46)
def upload_image(): # 이미지를 업로드하는 버튼을 구현하는 함수
try:
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/2.25),(top.winfo_height()/2.25)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
show_classify_button(file_path)
except:
pass
# 위에서 만든 함수들을 가지고 실행하는 코드들
upload=Button(top,text="Upload an image",command=upload_image,padx=10,pady=5)
upload.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
upload.pack(side=BOTTOM,pady=50)
sign_image.pack(side=BOTTOM,expand=True)
label.pack(side=BOTTOM,expand=True)
heading = Label(top, text="푸바오와 랫서판다 분류",pady=20, font=('arial',20,'bold'))
heading.configure(background='#CDCDCD',foreground='#364156')
heading.pack()
top.mainloop()