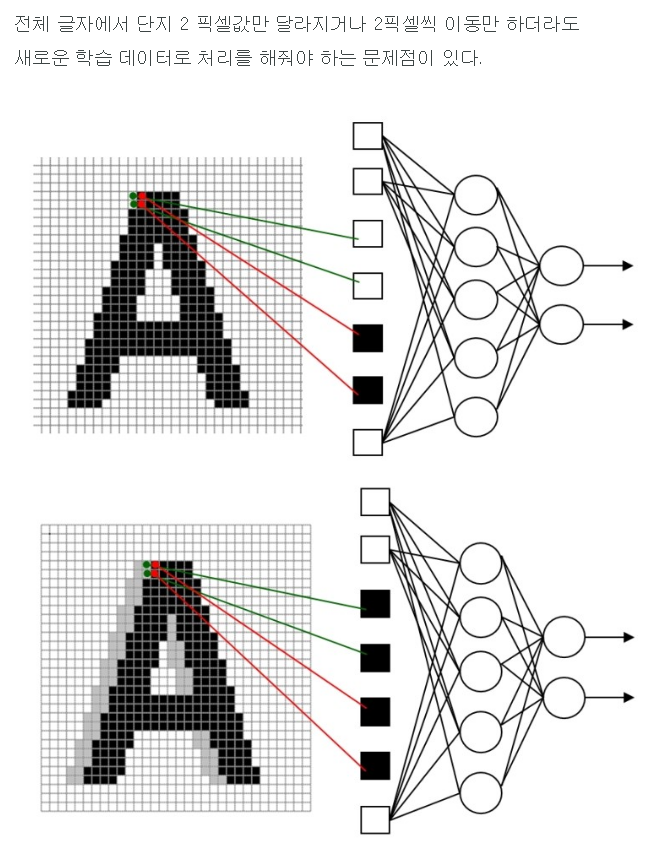
예제3. 예제 2번에서 선택한 3x3 영역의 원소들과 filter2의 원소들의 곱을 구하시오
print (x[0:3, 0:3] * filter2)
예제4. 예제 3에서 출력한 숫자들의 합을 출력하시오.
print (np.sum(x[0:3, 0:3] * filter2)) #15
■ CNN 을 이해하기 위한 그림들 순서대로 나열
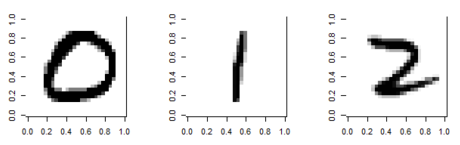
1. 아래의 숫자 8 필기체 784개의 픽셀값이 신경망에 입력이 되는데
2. CNN 을 이용하지 않았을때의 문제점은 ?
3. 그래서 CNN 을 사용하게 되면 ?
4. 그럼 위의 1번에서 특징을 어떻게 추출하는지 ?
컨볼루셔널 레이어는 앞에서 설명 했듯이 입력 데이타로 부터 특징을 추출하는 역할을 한다.
컨볼루셔널 레이어는 특징을 추출하는 기능을 하는 필터(Filter)와, 이 필터의 값을 비선형 값으로 바꾸어 주는 액티베이션 함수(Activiation 함수)로 이루어진다
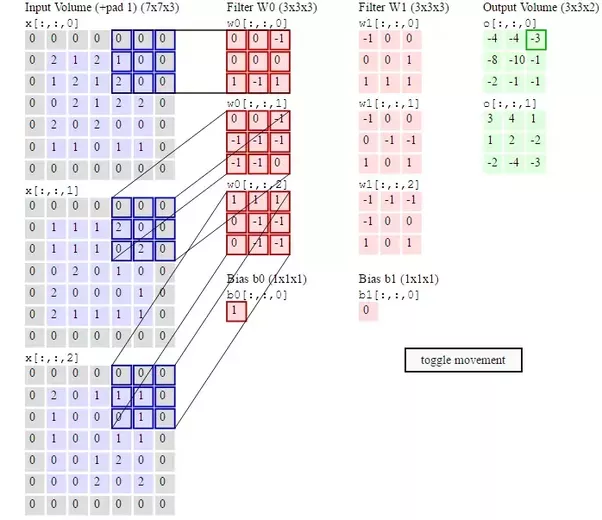
■ Striding 1 의 Convolution 연산 (합성곱 연산)
컨볼루션 연산을 통해 이미지의 특징들을 추출하는 역활을 수행한다.
MNIST는 28*28의 행렬형태로 표현되는 gray scale의 손글씨 예제들입니다. 각각의 픽셀은 0~255의 숫자를 갖죠. MLP는 기본적으로 벡터 인풋을 받기 때문에 (뉴럴 넷에서 인풋 layer가 1열로 길게 늘어선거 보이시죠?) 28*28 행렬을 784 짜리 긴 벡터로 먼저 바꿉니다. 그런 뒤 이러한 데이터들을 MLP에 통과시키고 (forward propagation) 에러 값을 계산한 후 W를 순차적으로 업데이트(back-propagation)하는 전략을 취하죠.
MNIST Data
반변 CNN은 다릅니다. 28*28 형태를 그대로 이용하죠. 그리고 어떻게 하냐면 (예를 들어) 3*3 짜리 커널 형렬로 한번 훑어서(sweep) 이 데이터를 다른 형태로 변형시키는 것입니다. 이 과정을 convolution이라고 하는데, 사실 그렇게 어려운 연산 아닙니다. 그냥 윈도우에 해당하는 원소들끼리 각각 곱해서 더해주는 것이지요.
[1 0 1; 0 1 0; 1 0 1] 커널 행렬로 convolution을 하는 모습. 초록색이 원래 숫자고 분홍색이 convolution의 결과이다.
이렇게 커널 윈도우로 이미지를 훑으면 어떻게 되느냐... 뭔가 변하겠지요? 원본에 이상한 짓을 해놨으니 말이죠 ㅎㅎ 바로 다음과 같이 변하게 된답니다.
대충 얘기하자면 CNN에서 convolution이란 주위값들을 반영해 중앙의 값을 변화시키는 것이라고 할 수 있죠. 어떤 쪽으로 변화시키냐고요? 여기서 바로 CNN의 핵심이 있는 것입니다. CNN은 목적하는 작업의 성공률이 높도록 이미지를 변형해 갑니다. 예를 들어 classification이라면 classification이 더욱 잘되도록 원본으로부터 2차 이미지들을 형성하는 것이지요. 용어설명을 하고 넘어가자면, 이렇게 만들어진 왜곡된 이미지들을 feature map이라고 합니다. 결국 CNN은 원본 입력을 받으면 다양한 커널행렬을 이용해 여러개의 feature map들을 만든 후, 이를 토대로 classification을 진행하는 것이지요. 그러니 원본 딱 하나만 가지고 학습을 했을 때보단, 다양한 feature map을 가지고 학습을 하는게 더 유리할 수 있겠죠?
또 중요한 점은 이 커널행렬이 학습 가능하다는 것입니다. MLP에서는 Wx+b에서 W가 학습 가능했자나요. 사실 convolution도 곱하기와 더하기로 이루어져 있으니 이 연산을 back propagation을 통해 학습하지 못할 이유가 없겠죠. 이 연산을 예를 들어 W*X 라고 표현한다면 (W는 커널 행렬, X는 적용되는 해당 이미지) 여기서의 W도 학습 가능하다는 이야기입니다. 짱이죠? ㅎㅎㅎ
5. 여기서 필터란 무엇이냐면 ?
필터는 그 특징이 데이타에 있는지 없는지를 검출해주는 함수이다.
예를 들어 아래와 같이 곡선을 검출해주는 필터가 있다고 하자.
결과 값이 0에 수렴하게 나온다.
즉 필터는 입력받은 데이타에서 그 특성을 가지고 있으면 결과 값이 큰값이 나오고, 특성을 가지고 있지 않으면 결과 값이 0에 가까운 값이 나오게 되서 데이타가 그 특성을 가지고 있는지 없는지 여부를 알 수 있게 해준다.
다중 필터의 적용
입력값에는 여러가지 특징이 있기 때문에 하나의 필터가 아닌 여러개의 다중 필터를 같이 적용하게 된다.
다음과 같이 |,+,- 모양을 가지고 있는 데이타가 있다고 하자
필터들
6. 패딩 이란 ?
" 합성곱 연산을 수행하기전, 입력 데이터 주변을 특정값으로 채워
늘리는것을 말한다."
- 패딩이 필요한 이유 ?
패딩을 하지 않을 경우 data 의 공간크기는 합성곱 계층을
지날때 마다 작아지게 되므로 가장 자리 정보들이 사라지게
되는 문제가 발생하기 때문에 패딩을 사용한다.
- 제로 패딩후 다시 합성곱 연산
7. 풀링(Pooling) 이란 ?
" 말그대로 출력 값에서 일부분만을 취하는 기능"
CNN은 pooling이라는 단계를 한번 더 거치죠. 이것은 단순히 사이즈를 줄이는 과정이라고 생각하면 좋을 것 같은데요, convolution이 이렇게저렇게 망쳐놓은(?) 그림들을 각각 부분에서 대표들을 뽑아 사이즈가 작은 이미지를 만드는 것이지요. 마치 사진을 축소하면 해상도가 좋아지는 듯한 효과와 비슷하달까요? ㅎㅎ 그런데 놀랍게도 단순한 '골라내기' 과정인 pooling은 성능향상에 매우 큰 기여를 합니다. 여기엔 여러가지 이유가 있지만 (미세한 translation에 대해 invariant한 feature를 제공한다, noise의 역할을 상쇄시킨다 등등) 하지만 제겐 아직도 이 부분이 매우 많은 발전 가능성이 있어 보이네요. 단순한게 이렇게 효과가 좋다면, 좀더 머리를 쓴다면 얼마나 더 나은 효과를 볼 수 있을까요? >.<
공모전 준비로 시계열 데이터 예측을 준비하는 조가 많아 딥러닝으로 시계열 예측하는 방법을 정리하였습니다.
돌아오는 주 수업시간에 아래의 코드로 진행할 예정입니다.
■ 시계열 데이터를 분석하는 방법
1. 전통적인 방법 : statsmodels 라이브러리를 이용한 ARIMA 시계열 분석 2. 딥러닝을 이용한 방법 : 텐써 플로우나 파이토치를 이용한 RNN, LSTM, GRU 모델을 사용하는 방법
문장 "그 남자는 그의 친구에게 선물을 주었다. 그 친구는 기뻐했다."를 RNN, LSTM, GRU 신경망에 넣었을 때, 각 신경망이 어떻게 작동하는지 간단히 설명할게요.
### 1. **RNN (Recurrent Neural Network)** - **원리**: RNN은 시간에 따른 순차적인 데이터를 처리할 수 있는 신경망입니다. 각 단어를 하나씩 처리하며, 이전 단어의 정보를 다음 단어로 전달하는 방식으로 작동합니다. 이때, 모든 정보는 은닉 상태(hidden state)라는 작은 공간에 저장됩니다. - **문제점**: 문장 초반의 정보가 후반으로 갈수록 점차 소실되는 경향이 있습니다. 예를 들어, "그 남자는"이라는 정보가 "기뻐했다"라는 단어에 도달할 때 거의 소실될 수 있습니다. 그래서 긴 문장에서 중요한 정보들이 소실될 수 있습니다.
### 2. **LSTM (Long Short-Term Memory)** - **원리**: LSTM은 RNN의 문제를 해결하기 위해 고안된 구조로, '장기 메모리'와 '단기 메모리'라는 두 가지 메모리 상태를 사용해 긴 문장에서 중요한 정보를 더 오래 유지할 수 있게 합니다. 각 단어를 처리할 때마다 어떤 정보를 기억할지(keep), 잊을지(forget), 새로운 정보를 추가할지(add) 결정하는 '게이트'라는 메커니즘을 사용합니다. - **효과**: 문장의 앞부분인 "그 남자는" 같은 중요한 정보를 잘 유지할 수 있어서, 마지막 "기뻐했다"를 해석할 때 "선물을 주었다"와 같은 앞의 맥락을 기억하고 더 정확하게 예측할 수 있습니다.
### 3. **GRU (Gated Recurrent Unit)** - **원리**: GRU는 LSTM의 간소화된 버전입니다. 장기 메모리와 단기 메모리를 따로 관리하는 대신, 하나의 메모리 상태만 관리하며, '업데이트 게이트'와 '리셋 게이트'라는 두 가지 게이트를 사용해 정보를 기억할지 잊을지 결정합니다. LSTM보다 계산이 덜 복잡해 속도가 빠릅니다. - **효과**: LSTM과 비슷한 성능을 내면서도 더 적은 자원을 사용합니다. 역시 "그 남자는"과 같은 앞의 정보를 비교적 잘 기억하면서도 효율적으로 예측할 수 있습니다.
### 요약 - **RNN**: 정보가 순차적으로 처리되지만 긴 문장에서는 중요한 정보가 소실될 수 있습니다. - **LSTM**: 기억해야 할 정보를 오래 유지하며, 긴 문장에서도 중요한 맥락을 잃지 않도록 설계되었습니다. - **GRU**: LSTM과 비슷한 성능을 내면서도 더 간단하고 빠릅니다.
이러한 차이점으로 인해 RNN은 간단한 문제에는 잘 맞지만, 문맥을 잘 기억해야 하는 긴 문장이나 복잡한 문제에서는 LSTM이나 GRU가 더 좋은 성능을 발휘합니다.
■ 딥러닝 lstm 을 이용하여 시계열 데이터 예측하기
1. 가상의 시계열 데이터 생성 코드
2. LSTM 신경망을 이용한 예측 코드
# 1. 필요한 도구 가져오기
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
# 2. 가상의 시계열 데이터 만들기
np.random.seed(42)
time_steps = 500
time = np.arange(time_steps)
data = 50 + np.sin(0.1 * time) * 100 + np.random.normal(0, 10, size=time_steps)
data
# 3. 데이터를 모델이 학습할 수 있는 형태로 만들기
def create_inout_sequences(input_data, seq_length):
X = []
y = []
L = len(input_data)
for i in range(L-seq_length):
train_seq = input_data[i:i+seq_length] # 입력 시퀀스
train_label = input_data[i+seq_length] # 예측할 타겟 값
X.append(train_seq)
y.append(train_label)
return np.array(X), np.array(y)
# 4. 데이터 전처리 (MinMax 스케일링)
scaler = MinMaxScaler(feature_range=(-1, 1))
data_normalized = scaler.fit_transform(data.reshape(-1, 1))
# 5. 학습할 데이터 준비하기
train_window = 20 # 시퀀스 길이
X_train, y_train = create_inout_sequences(data_normalized, train_window)
# LSTM 모델 입력에 맞게 차원 조정
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
# 6. 신경망 모델 생성
regression = Sequential()
# 첫 번째 LSTM 레이어와 드롭아웃 추가
regression.add(LSTM(units=50, activation="relu", return_sequences=True, input_shape=(X_train.shape[1], 1)))
regression.add(Dropout(0.2))
# 두 번째 LSTM 레이어와 드롭아웃 추가
regression.add(LSTM(units=60, activation="relu", return_sequences=True))
regression.add(Dropout(0.3))
# 세 번째 LSTM 레이어와 드롭아웃 추가
regression.add(LSTM(units=80, activation="relu", return_sequences=True))
regression.add(Dropout(0.4))
# 네 번째 LSTM 레이어와 드롭아웃 추가
regression.add(LSTM(units=120, activation="relu"))
regression.add(Dropout(0.5))
# 출력 레이어 추가
regression.add(Dense(units=1))
# 모델 구조 출력
regression.summary()
# 7. 모델 컴파일
regression.compile(optimizer='adam', loss='mean_squared_error')
# 8. 모델 학습
epochs = 150
history = regression.fit(X_train, y_train, epochs=epochs, batch_size=1, verbose=2)
# 9. 예측하기
test_inputs = data_normalized[-train_window:].tolist()
for i in range(20): # 향후 20 스텝 예측
seq = np.array(test_inputs[-train_window:])
seq = seq.reshape((1, train_window, 1))
predicted_value = regression.predict(seq)
test_inputs.append(predicted_value[0])
# 10. 예측값을 역정규화해서 원래값으로 되돌리기
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:]).reshape(-1, 1))
# 11. 결과 시각화
plt.plot(data, label='True Data')
plt.plot(range(time_steps, time_steps + len(actual_predictions)), actual_predictions, label='Predictions')
plt.legend()
plt.title("True Data vs LSTM Predictions")
plt.show()
문제. 다음 카카오 주가 데이터(cacao5.csv) 를 이용하여 lstm 신경망 모델을 만들고 실제 주가 데이터와 예측 주가 데이터를 시각화 하시오!
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 1. 데이터 불러오기
file_path = 'c:\\data\\cacao5.csv' # 새로운 경로
cacao_data = pd.read_csv(file_path)
# 'close' 열만 선택하여 시계열 데이터로 사용
cacao_close = cacao_data[['close']].values.astype(float)
# 데이터 정규화 (MinMaxScaler 사용)
scaler = MinMaxScaler(feature_range=(-1, 1))
cacao_close_normalized = scaler.fit_transform(cacao_close)
# 2. 시계열 데이터를 LSTM에 맞게 변환하는 함수
def create_inout_sequences(input_data, seq_length):
inout_seq = []
L = len(input_data)
for i in range(L-seq_length):
train_seq = input_data[i:i+seq_length]
train_label = input_data[i+seq_length:i+seq_length+1]
inout_seq.append((train_seq, train_label))
return inout_seq
# 시퀀스 길이 정의
train_window = 20 # 20일치 데이터를 기반으로 다음 날을 예측
# 시퀀스 데이터 생성
train_inout_seq = create_inout_sequences(torch.FloatTensor(cacao_close_normalized), train_window)
# 3. LSTM 모델 정의
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super(LSTM, self).__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size),
torch.zeros(1,1,self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
# 4. 모델 학습
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 학습 과정
epochs = 150
for i in range(epochs):
for seq, labels in train_inout_seq:
optimizer.zero_grad()
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred.view(-1), labels.view(-1))
single_loss.backward()
optimizer.step()
if i % 25 == 0:
print(f'Epoch {i} loss: {single_loss.item():.4f}')
# 5. 예측
model.eval()
test_inputs = cacao_close_normalized[-train_window:].tolist()
for i in range(20): # 향후 20일 예측
seq = torch.FloatTensor(test_inputs[-train_window:])
with torch.no_grad():
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
test_inputs.append([model(seq).item()])
# 정규화 해제 (inverse_transform)
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:]).reshape(-1, 1))
# 6. 결과 시각화
plt.plot(cacao_close, label='Real Cacao Stock Price')
plt.plot(range(len(cacao_close), len(cacao_close) + len(actual_predictions)), actual_predictions, label='Predicted Cacao Stock Price')
plt.legend()
plt.title("Cacao Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("Cacao Stock Price")
plt.show()
문제2. 과거의 카카오 주가 데이터로 미래의 카카오 주가 데이터를 예측하시오 !
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 1. 데이터 불러오기
file_path = 'c:\\data\\cacao5.csv' # 새로운 경로
cacao_data = pd.read_csv(file_path)
# 'close' 열만 선택하여 시계열 데이터로 사용
cacao_close = cacao_data[['close']].values.astype(float)
# 데이터 정규화 (MinMaxScaler 사용)
scaler = MinMaxScaler(feature_range=(-1, 1))
cacao_close_normalized = scaler.fit_transform(cacao_close)
# 2. 시계열 데이터를 LSTM에 맞게 변환하는 함수
def create_inout_sequences(input_data, seq_length):
inout_seq = []
L = len(input_data)
for i in range(L-seq_length):
train_seq = input_data[i:i+seq_length]
train_label = input_data[i+seq_length:i+seq_length+1]
inout_seq.append((train_seq, train_label))
return inout_seq
# 시퀀스 길이 정의
train_window = 20 # 20일치 데이터를 기반으로 다음 날을 예측
# 시퀀스 데이터 생성
train_inout_seq = create_inout_sequences(torch.FloatTensor(cacao_close_normalized), train_window)
# 3. LSTM 모델 정의
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super(LSTM, self).__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size),
torch.zeros(1,1,self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
# 4. 모델 학습
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 학습 과정
epochs = 150
for i in range(epochs):
for seq, labels in train_inout_seq:
optimizer.zero_grad()
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred.view(-1), labels.view(-1))
single_loss.backward()
optimizer.step()
if i % 25 == 0:
print(f'Epoch {i} loss: {single_loss.item():.4f}')
# 5. 예측
model.eval()
test_inputs = cacao_close_normalized[-train_window:].tolist()
for i in range(20): # 향후 20일 예측
seq = torch.FloatTensor(test_inputs[-train_window:])
with torch.no_grad():
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
test_inputs.append([model(seq).item()])
# 정규화 해제 (inverse_transform)
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:]).reshape(-1, 1))
# 6. 결과 시각화
plt.plot(cacao_close, label='Real Cacao Stock Price')
plt.plot(range(len(cacao_close), len(cacao_close) + len(actual_predictions)), actual_predictions, label='Predicted Cacao Stock Price')
plt.legend()
plt.title("Cacao Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("Cacao Stock Price")
plt.show()
문제. 다른 종목의 주가로 예측해봅니다. 다음의 코드로 삼성전자 주가 데이터를 다운 받습니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import pandas as pd
import time
from io import StringIO # 추가된 부분
# webdriver-manager를 사용하여 크롬 드라이버 자동 설치 및 실행
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 삼성전자 주가 페이지로 이동
url = 'https://finance.naver.com/item/sise_day.nhn?code=005930'
driver.get(url)
# 빈 DataFrame 생성
df = pd.DataFrame()
# 페이지 수 만큼 반복하여 데이터 수집
pages = 10 # 원하는 페이지 수 설정
for page in range(1, pages + 1):
driver.get(f"https://finance.naver.com/item/sise_day.nhn?code=005930&page={page}")
time.sleep(2) # 페이지 로드 대기 (2초)
# 페이지에서 테이블 가져오기
table = driver.find_element(By.CLASS_NAME, 'type2')
html = table.get_attribute('outerHTML')
# StringIO로 문자열을 파일처럼 처리하여 pandas로 읽기
df_page = pd.read_html(StringIO(html))[0]
df = pd.concat([df, df_page], ignore_index=True)
# 불필요한 행 제거 및 데이터 정제
df = df.dropna() # 결측치 제거
# '전일비' 열에서 상승(▲)과 하락(▼) 기호 제거 및 숫자 변환
df['전일비'] = df['전일비'].replace({'상승': '', '하락': '', '보합': '0'}, regex=True) # 보합은 0으로 변환
df['전일비'] = df['전일비'].str.replace(',', '').astype(int) # 쉼표 제거 후 숫자로 변환
# 컬럼 이름 영어로 변환
df = df.rename(columns={'날짜': 'Date', '종가': 'Close', '전일비': 'Diff', '시가': 'Open', '고가': 'High', '저가': 'Low', '거래량': 'Volume'})
df['Date'] = pd.to_datetime(df['Date']) # 날짜 형식 변환
# 크롬 드라이버 종료
driver.quit()
# CSV 파일로 저장
df.to_csv('c:\\data\\samsung_stock.csv', index=False)
print("삼성전자 주가 데이터를 CSV로 저장했습니다.")