
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 순위출력
- 상관관계
- 히스토그램 그리기
- 불순도제거
- 그래프시각화
- Intersect
- 단순회귀 분석
- 그래프 생성 문법
- Dense_Rank
- 막대그래프
- if문 작성법
- 데이터분석가
- sql
- 회귀분석
- 팀스파르타
- Sum
- 빅데이터분석
- difftime
- 회귀분석 알고리즘
- merge
- count
- loop 문
- sqld
- %in%
- max
- 총과 카드만들기
- 데이터분석
- 빅데이터
- 정보획득량
- 여러 데이터 검색
- Today
- Total
ch0nny_log
[빅데이터분석] Linux_10. 리눅스 & 하둡 최신 버전 설치 (24.09.30) 본문
✅ 리눅스 설치
[ https://cafe.daum.net/oracleoracle/Sho9/1 (참고링크) ]
※ oracle VM VirtualBox 에서 머신 -> 새로만들기



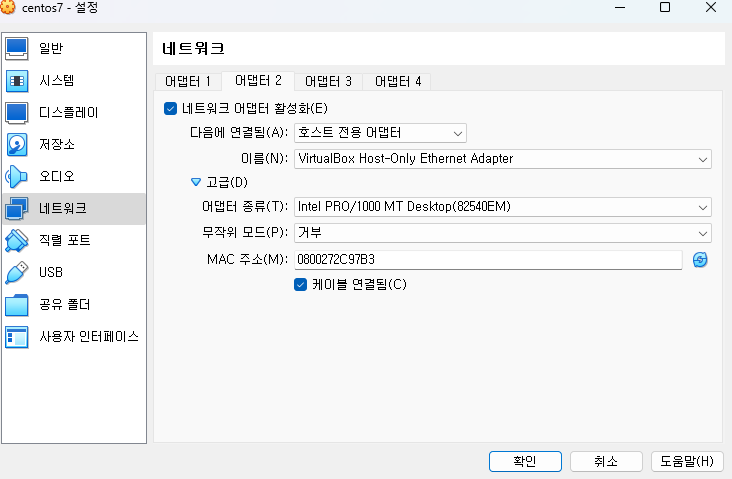
※ centos7 오른쪽 마우스 -> 설정 클릭
※ centos7 실행
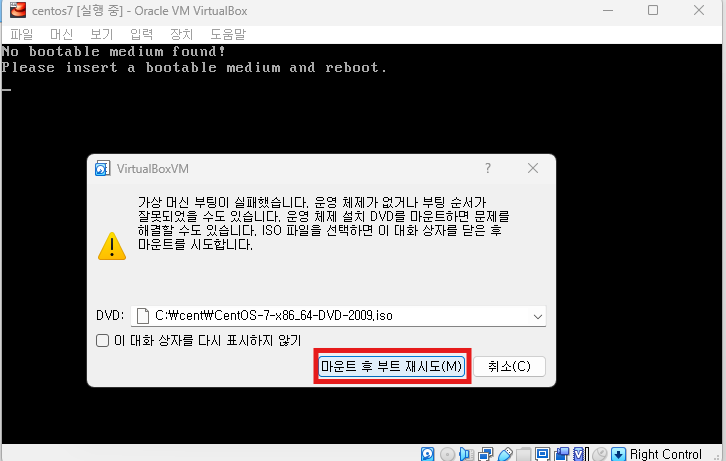
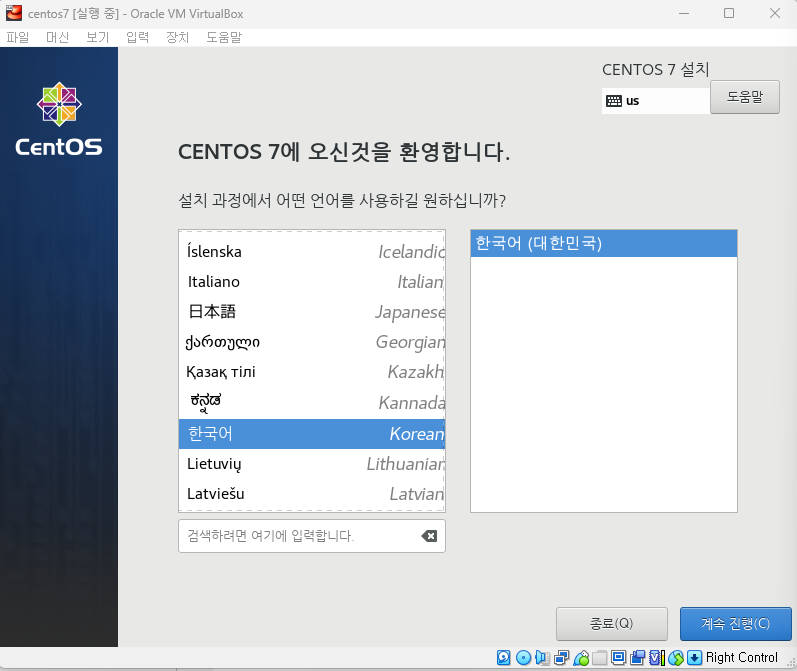
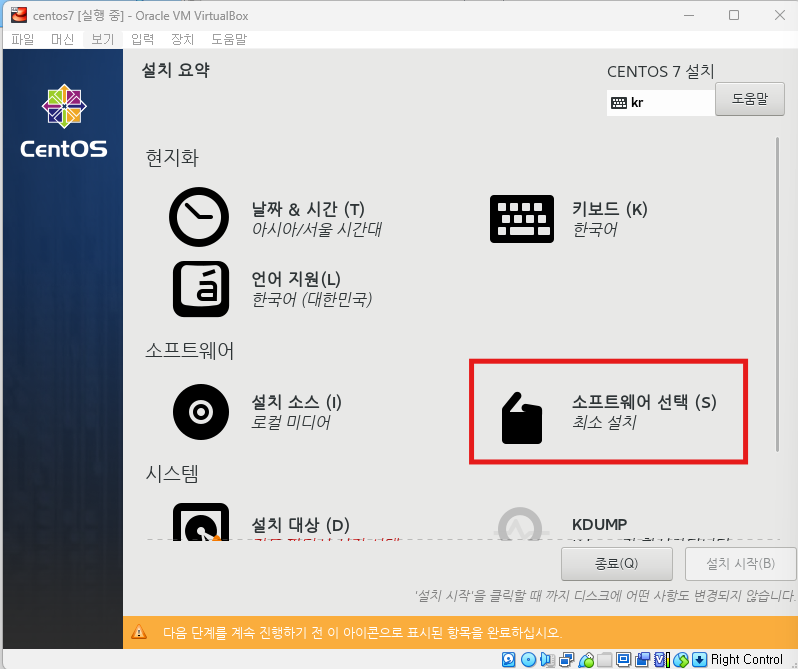
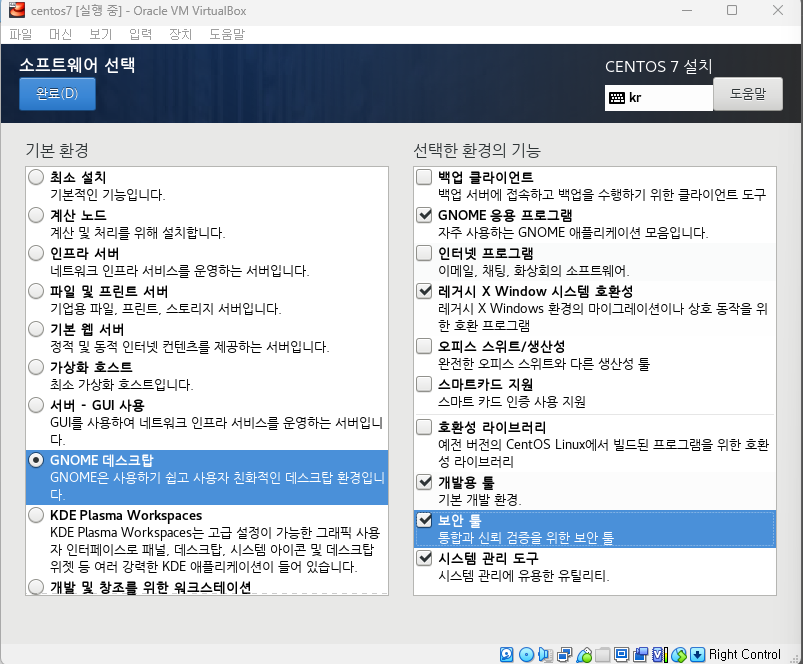
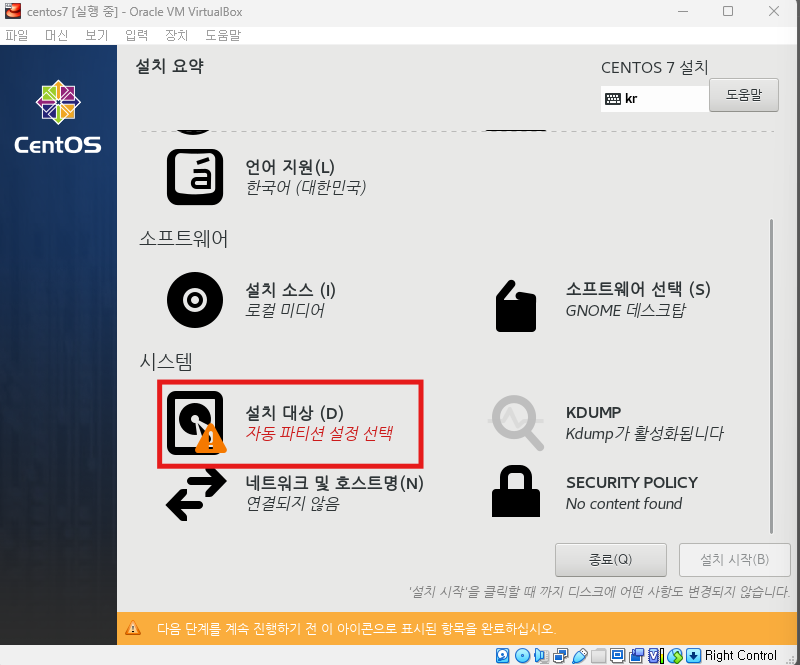
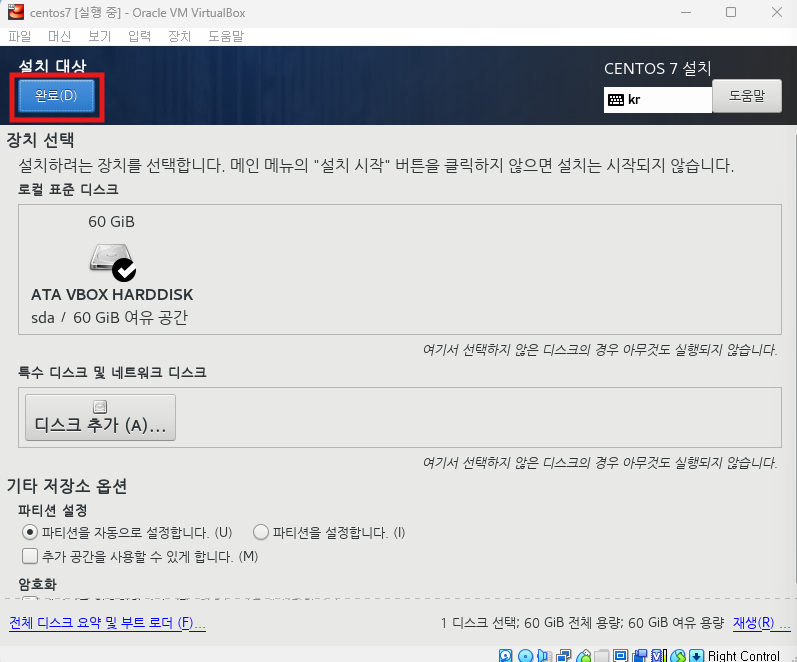
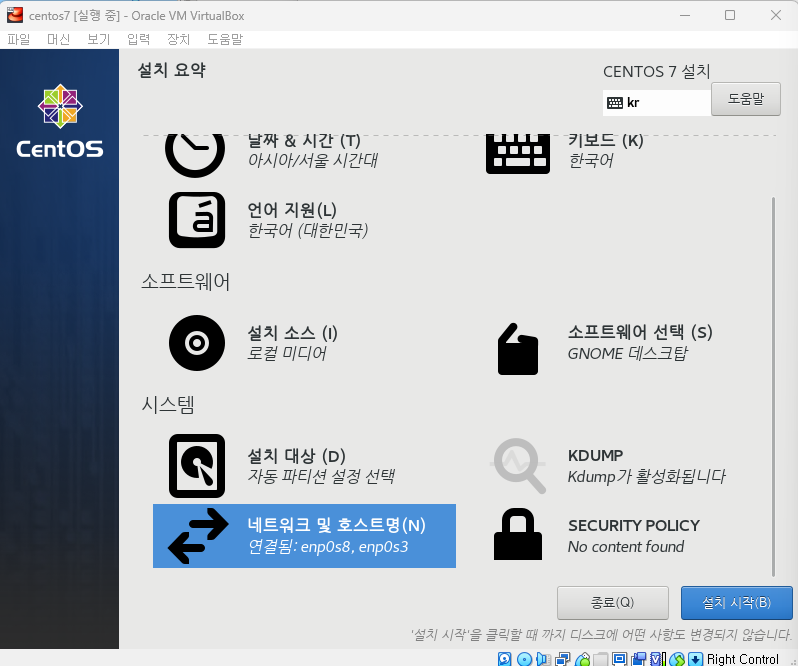
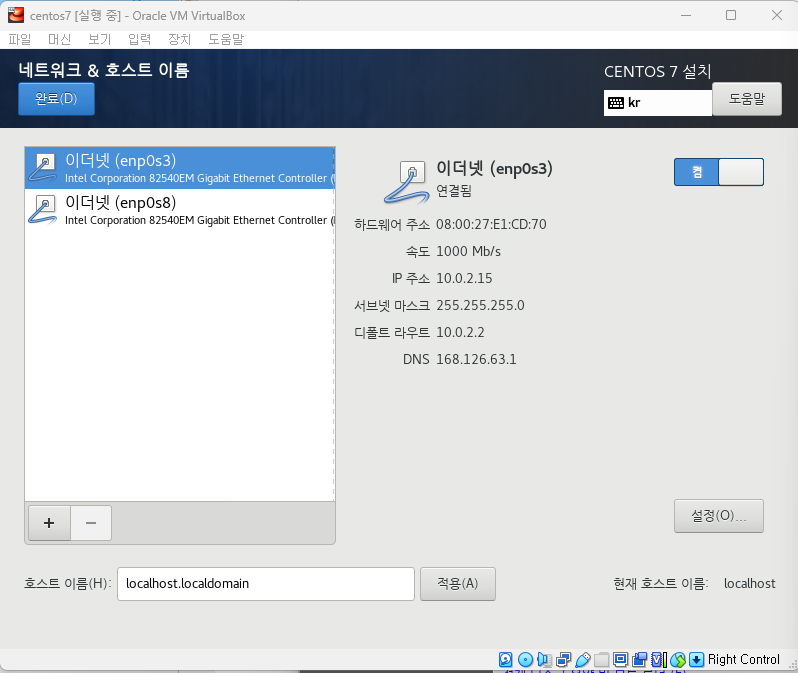
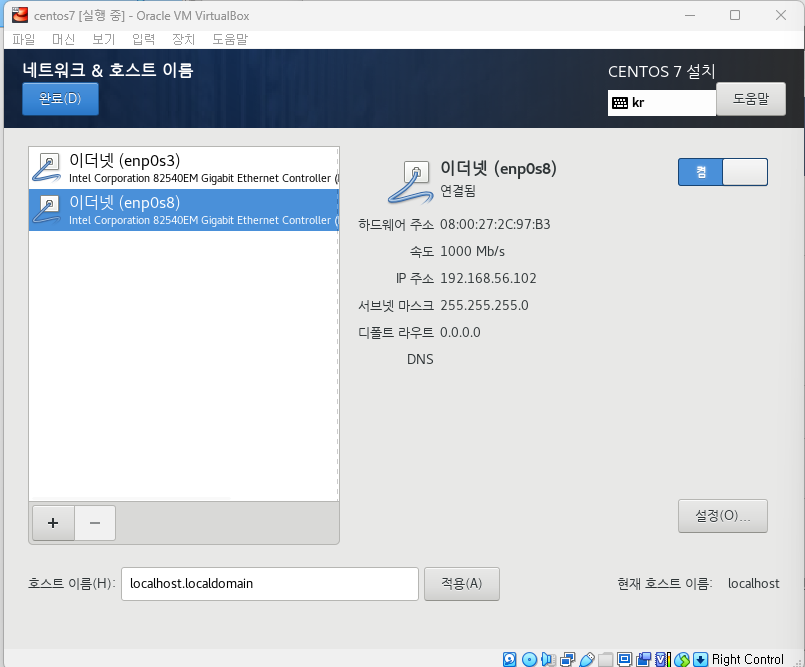
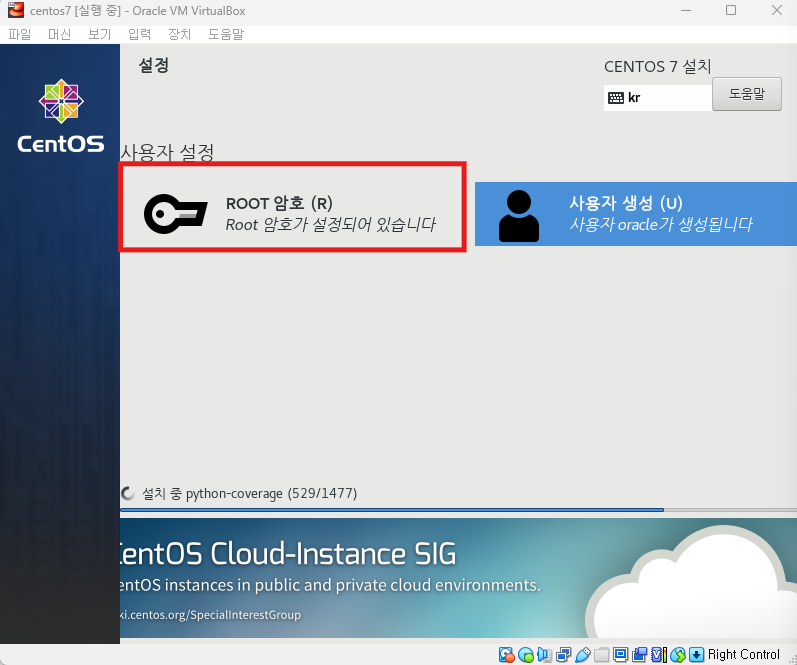
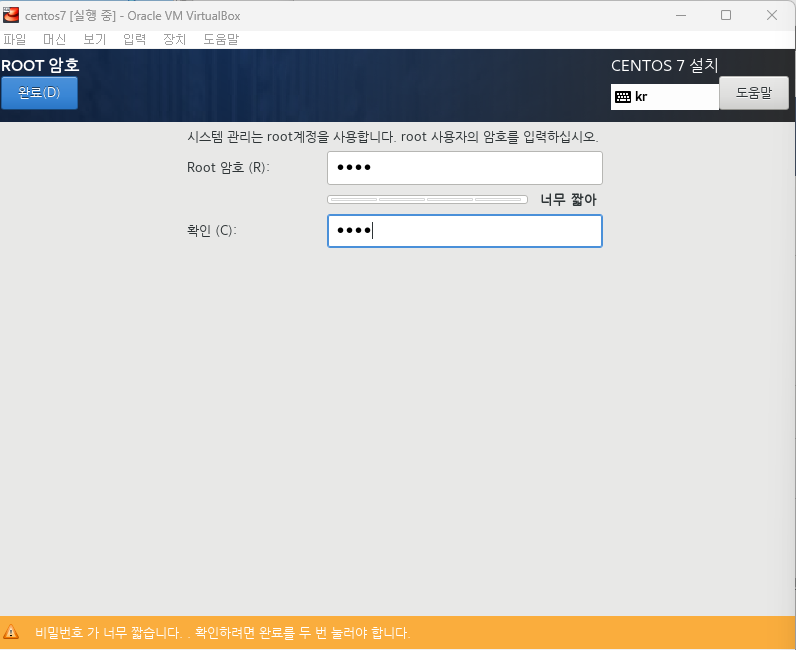
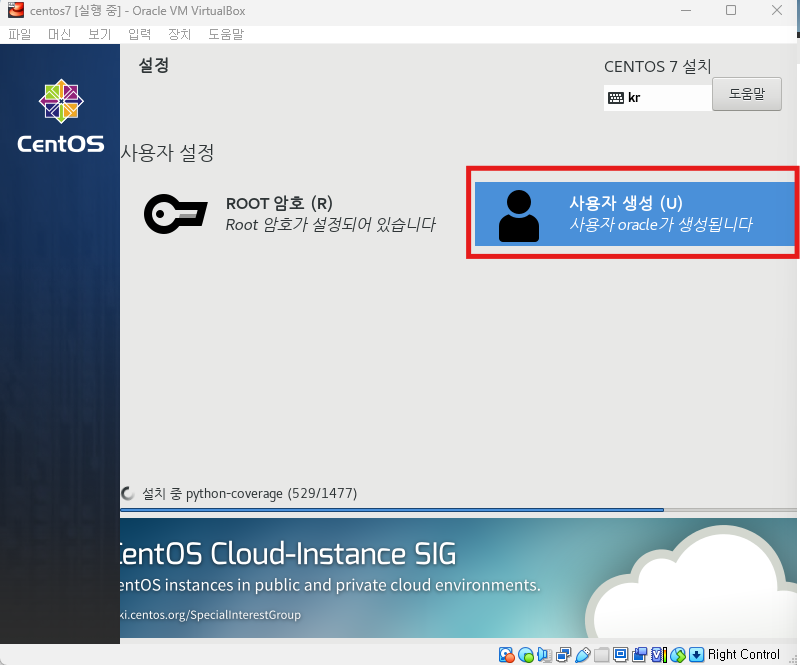
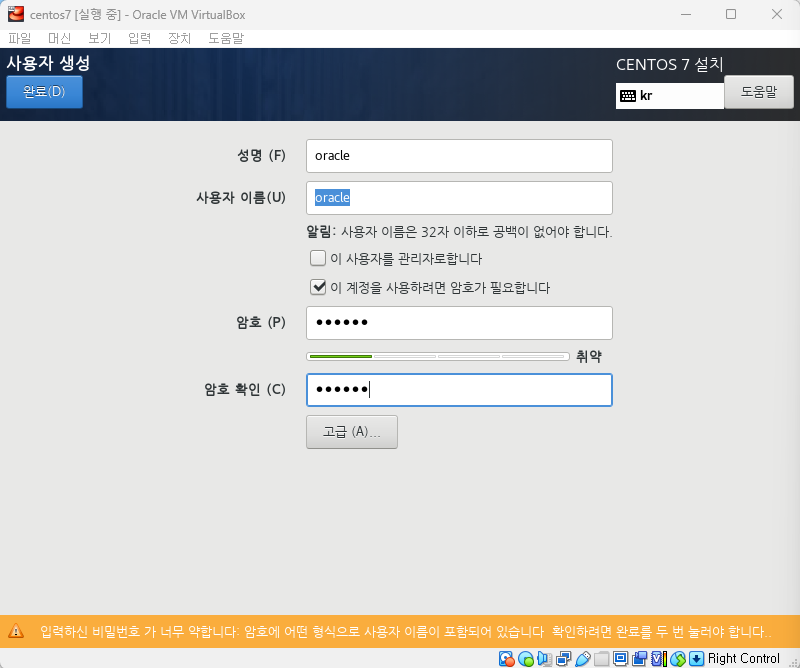
완료 클릭후 설치 시작 -> 재부팅 버튼 클릭
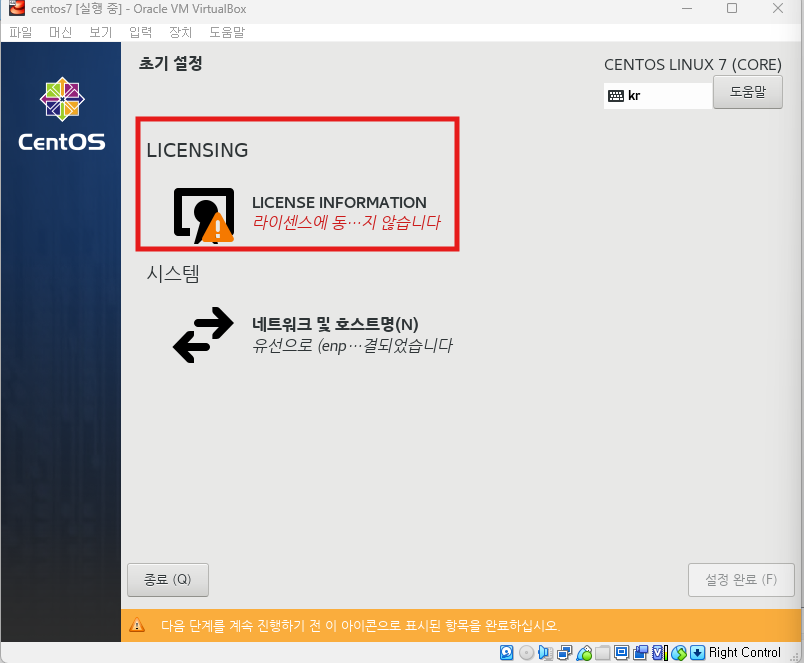
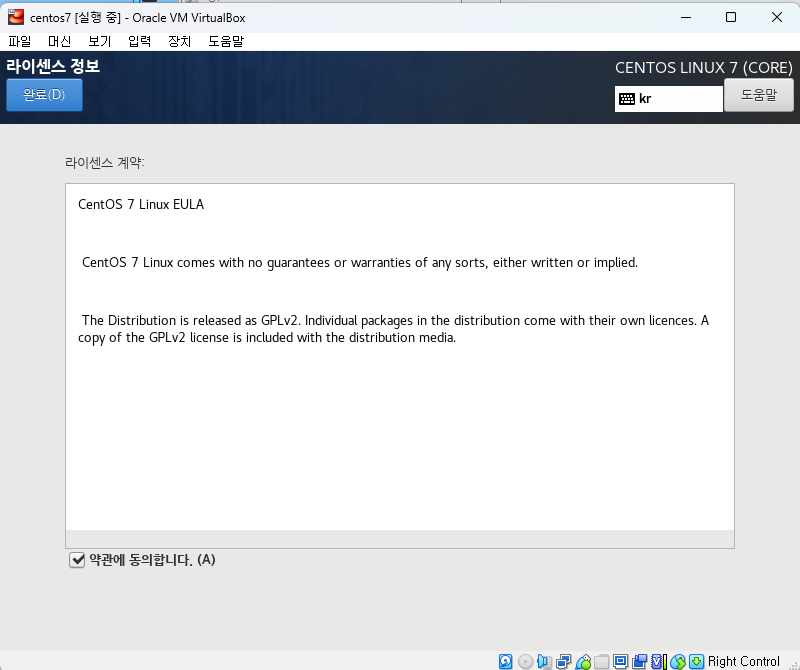
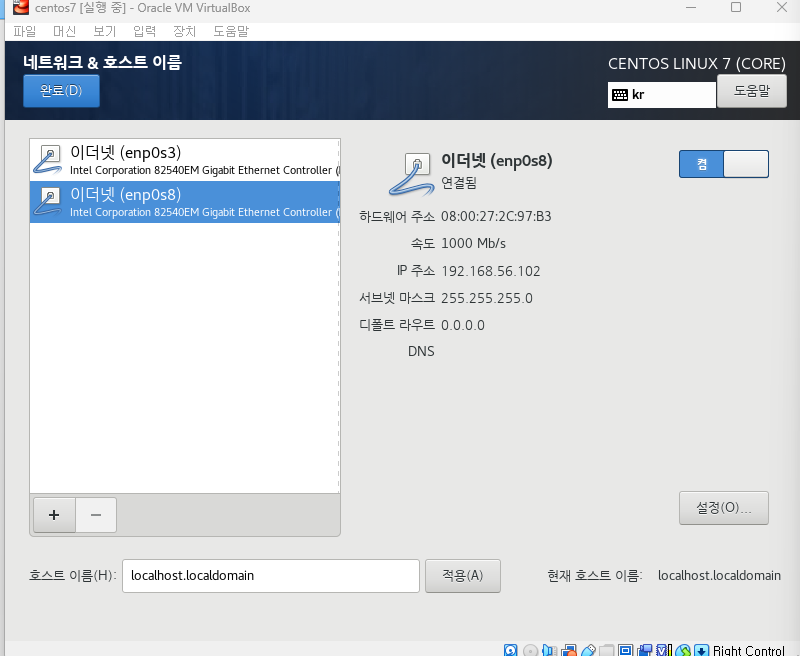
네트워크 두개 모두 켜야됨
※ 시스템 확장
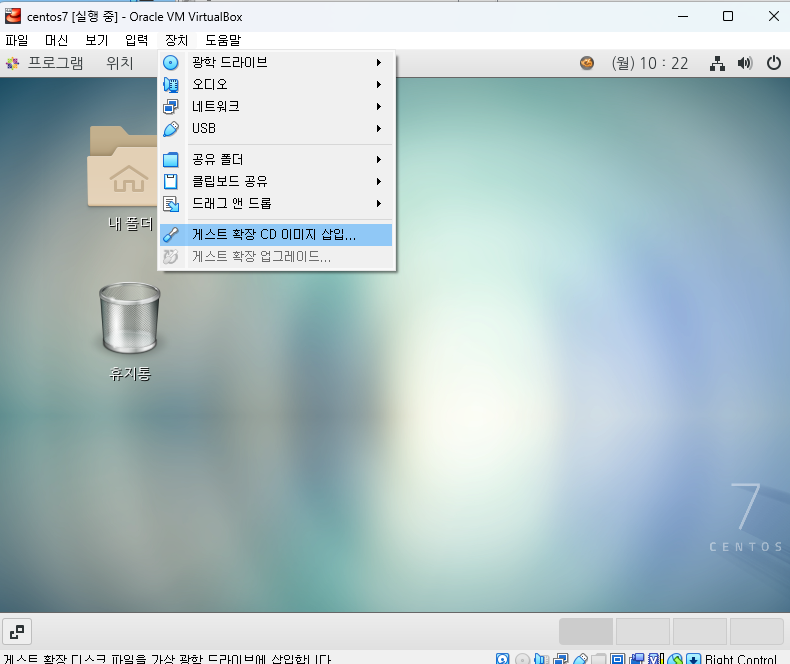
실행 완료가 되면 터미널 창이 알아서 닫김
★ 반드시 터미널 창에서 리부팅해야됨
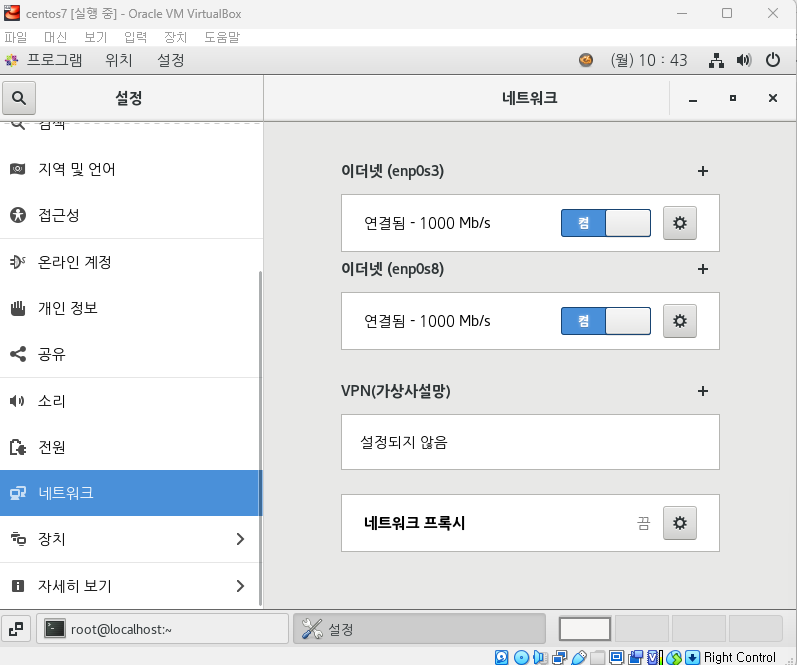
이더넷 톱니바퀴 클릭
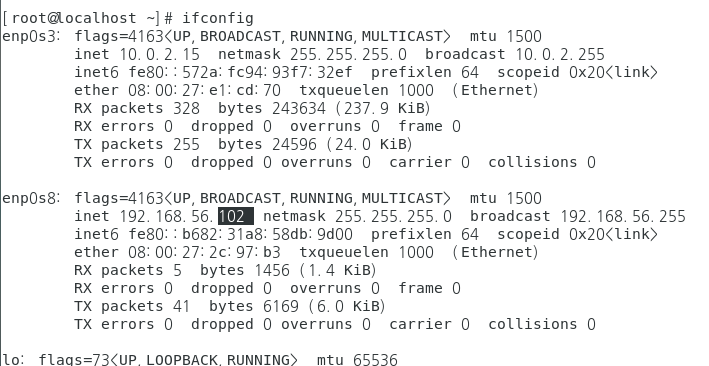
터미널창 열고 ip 확인
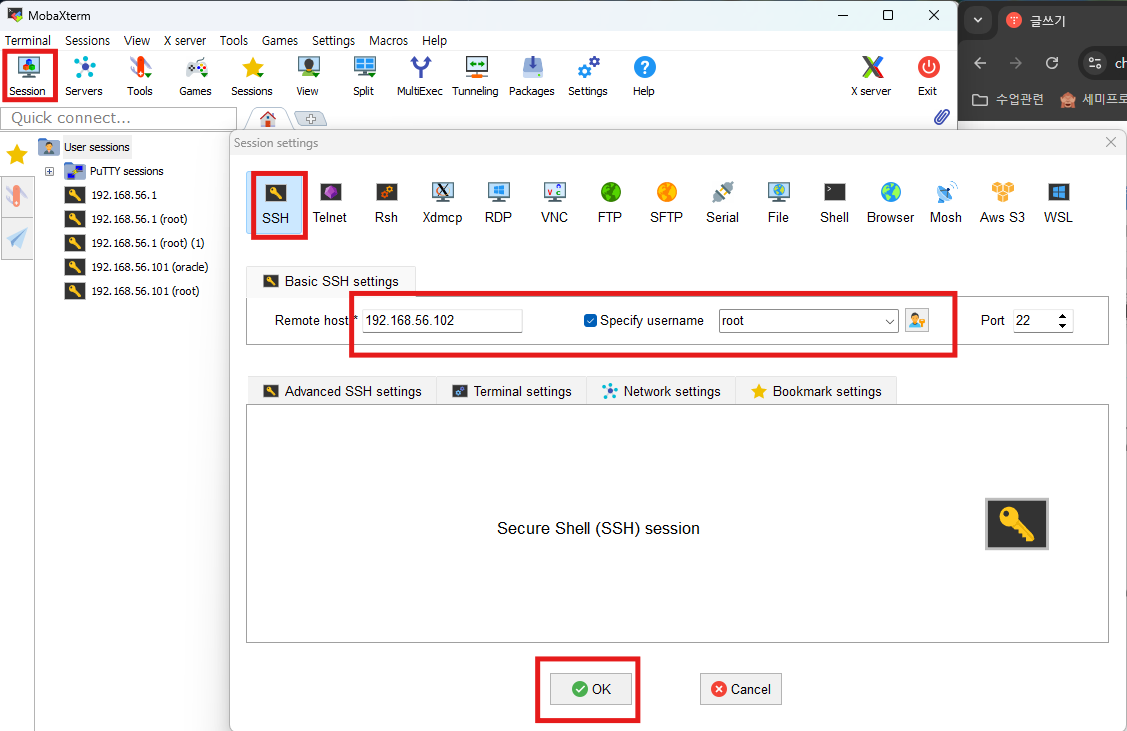
mobaxterm 열기
✅ 하둡 설치
https://cafe.daum.net/oracleoracle/SpJO/141(참고링크)
centos7 에 하둡 3.0 설치후 하이브 3.13 설치까지 총 스크립트
0. 먼저 다시 vm을 새로 만들어서 centos7 을 새로 설치합니다.
1. oracle 유져가 sudo 명령어를 수행할 수 있도록 설정합니다.
1.1. Root 사용자로 로그인
su -
1.2. sudoers 파일 수정
visudo 명령어를 사용하여 sudoers 파일을 수정합니다.
visudovisudo 편집기에서 다음 줄을 추가합니다: (마지막줄에)
## Allow 'oracle' user to run any commands anywhere
oracle ALL=(ALL) ALL파일을 저장하고 종료합니다 (Esc, :wq, Enter).
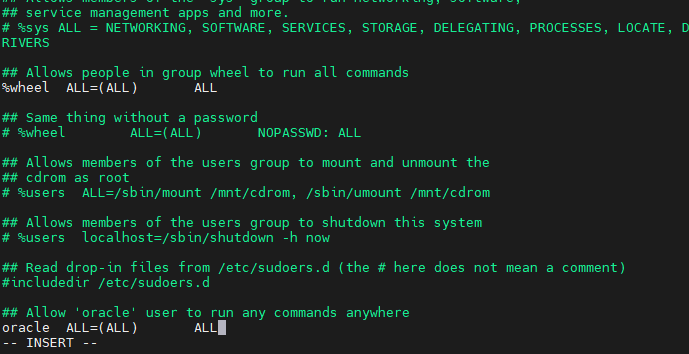
1.3. oracle 사용자로 전환 후 sudo 테스트
oracle 사용자로 전환하고 sudo 권한이 정상적으로 작동하는지 테스트합니다.
su - oracle
sudo ls /root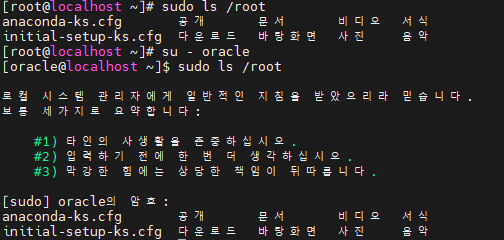
2. 기존 자바 제거 및 새로 설치 (Root 사용자)
2.1. 기존 자바 제거
기존 자바를 제거합니다.
sudo yum remove java-1.7.0-openjdk java-1.8.0-openjdk -y2.1. DNS 를 설정합니다.
sudo vi /etc/resolv.conf아래의 2줄을 추가합니다.
nameserver 8.8.8.8
nameserver 8.8.4.4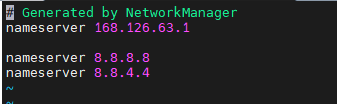
2.2. YUM 리포지토리 설정 수정
리포지토리 설정 문제를 해결하기 위해 /etc/yum.repos.d/CentOS-Base.repo 파일을 수정합니다.
1.리포지토리 파일 열기:
sudo vi /etc/yum.repos.d/CentOS-Base.repo2. 안의 내용을 전부 지우고 아래의 내용으로 변경합니다.
[updates]
name=CentOS-7 - Updates
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates&infra=$infra
baseurl=http://vault.centos.org/centos/7/updates/x86_64/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
[extras]
name=CentOS-7 - Extras
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras&infra=$infra
baseurl=http://vault.centos.org/centos/7/extras/x86_64/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7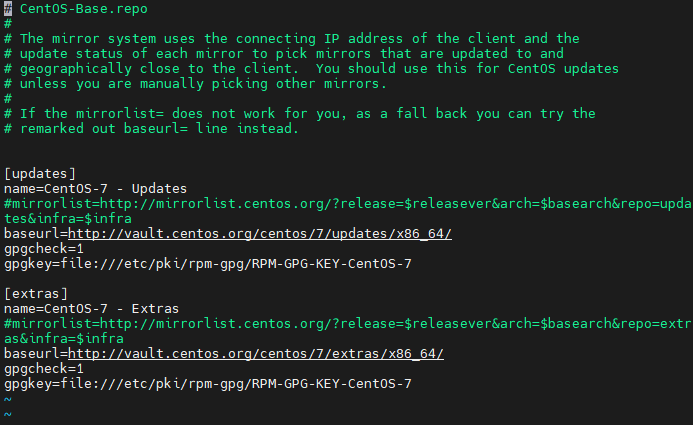
3.파일 저장 및 종료:
vi 편집기에서 Esc, :wq 입력 후 Enter를 누릅니다.
4. YUM 캐시 정리 및 재생성: YUM 설정을 변경한 후 캐시를 정리하고 다시 생성합니다.
sudo yum clean all
sudo yum makecache
2.3. 자바 설치
Java 8을 새로 설치합니다.
sudo yum install java-1.8.0-openjdk-devel -y2.4. 자바 설치 확인
설치된 자바 버전을 확인합니다.
java -version
3. SSH 설정 (Oracle 사용자)
3.1. oracle 사용자로 전환
oracle 사용자로 전환합니다.
su - oracle3.2. SSH 키 생성
oracle 사용자로 SSH 키를 생성합니다. 프롬프트에서 기본 경로를 사용하고 비밀번호 없이 생성합니다:
ssh-keygen -t rsa -P ""
그냥 엔터

키를 저장할 파일 위치로 기본값 (/home/oracle/.ssh/id_rsa)을 사용하고, 비밀번호 없이 생성하도록 설정합니다.
SHA256:9qpJrS89e+FlgeEaKmXxAmTWjNQF9oa0OpLs51Ko2Mo oracle@localhost.localdomain
The key's randomart image is:
+---[RSA 2048]----+
| o==+o. |
| ooo=+ . |
| .ooo. o |
| . . .+.o o . |
| +.oo oSo . |
| ...o..o... o |
|.o.........+ |
|+ oo ..oo.o |
|.E .. ++++ |
+----[SHA256]-----+
3.3. SSH 공개 키 설정
생성한 SSH 공개 키를 authorized_keys 파일에 추가합니다:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys3.4. SSH 디렉토리 및 파일 권한 설정
SSH 디렉토리와 파일의 권한을 올바르게 설정합니다:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys3.5. SSH 설정 파일 수정
SSH 설정 파일에서 PasswordAuthentication이 허용되도록 설정합니다.
/etc/ssh/sshd_config 파일을 열어 다음 내용을 확인하거나 수정합니다:
sudo vi /etc/ssh/sshd_config
다음 설정이 존재하고 설정되어 있는지 확인합니다: (맨밑에)
PermitRootLogin no
PasswordAuthentication yes
PubkeyAuthentication yes
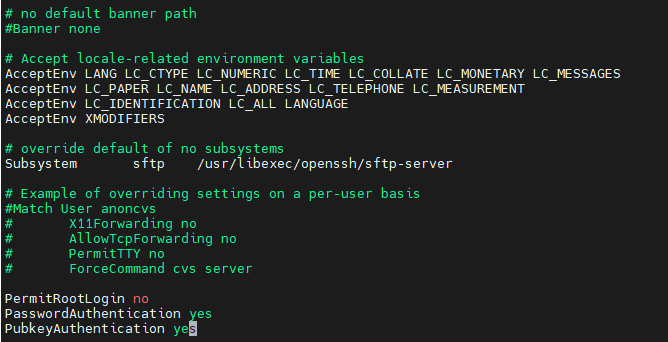
변경 후 파일을 저장하고 나옵니다 (Esc, :wq, Enter).
3.6. SSH 데몬 재시작
SSH 설정을 적용하기 위해 SSH 데몬을 재시작합니다:
sudo systemctl restart sshd
3.7 oracle 유져로 접속해서 패스워드 안물어보는지 확인합니다.
[oracle@localhost ~]$ ssh oracle@localhost
[oracle@localhost ~]$ ssh oracle@localhost
3.1. oracle 사용자로 전환
oracle 사용자로 전환합니다.
su - oracle3.2. 환경 변수 설정
3.2.1. .bash_profile 파일 열기
vi ~/.bash_profile3.2.2. 환경 변수 추가
다음 내용을 .bash_profile 파일의 끝에 추가합니다:
# Java 환경 변수 설정
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$JAVA_HOME/bin:$PATH
# Hadoop 환경 변수 설정
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin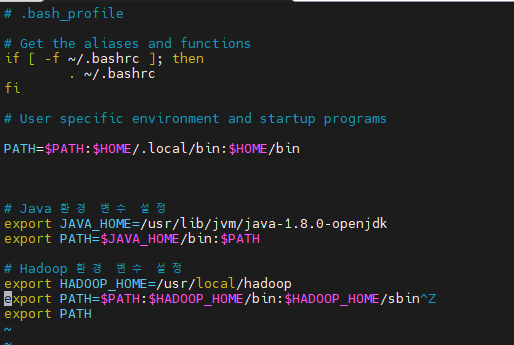
3.2.3. 파일 저장 및 종료
Esc 키를 누른 후 :wq 입력 후 Enter 키를 누릅니다.
3.3. 환경 변수 적용
변경된 환경 변수를 적용합니다.
source ~/.bash_profile
4. 하둡 설치4.1.
하둡 다운로드 및 압축 해제
4.1.1. 하둡 다운로드
최신 하둡 패키지를 다운로드합니다.
$ wget https://downloads.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz4.1.2. 압축 해제
다운로드한 파일의 압축을 풉니다.
$ tar -xzvf hadoop-3.4.0.tar.gz4.1.3. 하둡 디렉토리 이동 및 권한 설정
하둡 디렉토리를 /usr/local로 이동하고, oracle 사용자에게 권한을 부여합니다.
$ sudo mv hadoop-3.4.0 /usr/local/hadoop
$ sudo chown -R oracle:oracle /usr/local/hadoop5. 하둡 설정
5.1. 환경 설정 파일 수정
5.1.1. core-site.xml 설정
$HADOOP_HOME/etc/hadoop/core-site.xml 파일을 열어 다음 내용을 추가합니다.
vi $HADOOP_HOME/etc/hadoop/core-site.xml| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> |
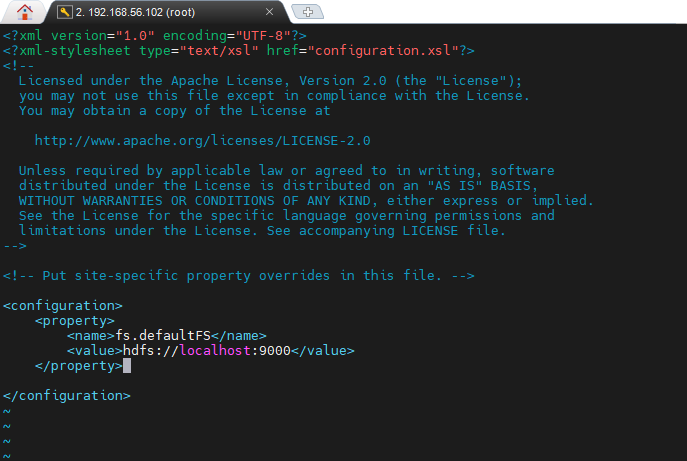
5.1.2. hdfs-site.xml 설정
$HADOOP_HOME/etc/hadoop/hdfs-site.xml 파일을 열어 다음 내용을 추가합니다.
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml| <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop/hdfs/datanode</value> </property> </configuration> |
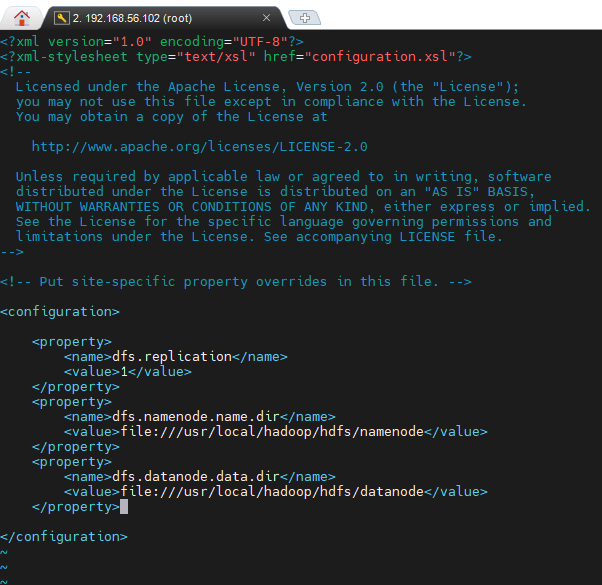
5.1.3. mapred-site.xml 설정
$HADOOP_HOME/etc/hadoop/mapred-site.xml 파일을 생성하고, 다음 내용을 추가합니다.
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
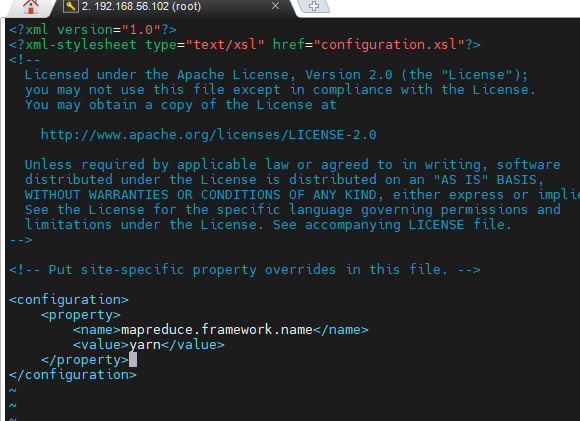
5.1.4. yarn-site.xml 설정
$HADOOP_HOME/etc/hadoop/yarn-site.xml 파일을 열어 다음 내용을 추가합니다.
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml| <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
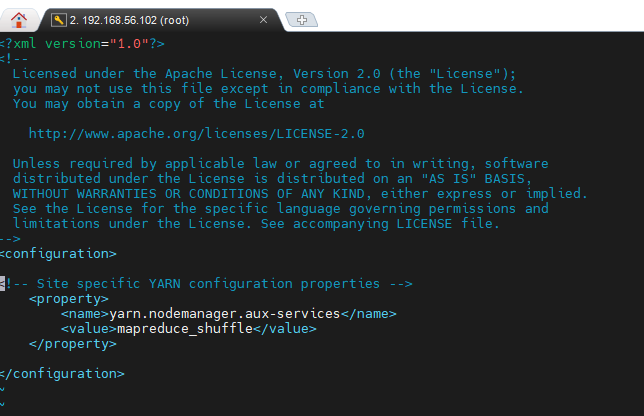
5.1.5. hadoop-env.sh 설정
$HADOOP_HOME/etc/hadoop/hadoop-env.sh 파일을 열어 JAVA_HOME을 설정합니다.
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh| export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk |
맨밑에 끼워넣기
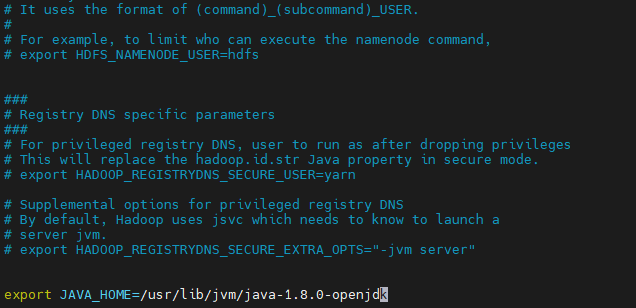
6. 네임노드 및 데이터노드 디렉토리 생성
하둡 데이터 저장을 위한 네임노드와 데이터노드 디렉토리를 생성합니다.
mkdir -p /usr/local/hadoop/hdfs/namenode
mkdir -p /usr/local/hadoop/hdfs/datanode
7. 네임노드 포맷
네임노드를 포맷합니다.
The authenticity of host 'localhost (::1)' can't be established.8. 하둡 데몬 시작8.1. HDFS 시작
다음 명령어로 HDFS 데몬을 시작합니다.
start-dfs.sh8.2. YARN 시작
다음 명령어로 YARN 데몬을 시작합니다.
start-yarn.sh
8.3. 데몬 상태 확인
jpsjps 명령어로 하둡 데몬들이 정상적으로 실행되고 있는지 확인합니다.
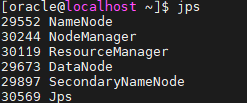
★ 하둡관련해서 면접질문 ?
원리를 주로 물어보니까 원리를 잘 정리해서 이해하고 있으면 됩니다.
■ 원리1] 하둡의 hdfs 가 무엇인지 설명해주실 수 있나요 ?
답변: 하둡의 핵심 구성요소 중 하나로 대규모 데이터를 분산하여 저장하고
관리하는 파일 시스템입니다. hdfs 로 인해서 여러대의 컴퓨터(노드)들을 묶어서
하나의 큰 서버로 쓸 수 있는것입니다.
■ 원리2] 하둡의 맵리듀스(mapreduce) 에 대해서 설명해주실 수 있나요 ?
답변: 구글이 개발한 분산 데이터 처리 모델이자 소프트웨어 프레임워크로
대규모 데이터를 병렬처리하고 계산하는데 사용됩니다.
■ 원리3] 하둡의 장점이 무엇인가요 ?
답변: 수백 수천대의 서버로 구성된 클러스터에서 동작될 수 있도록 설계가 되어있어
하둡 클러스터의 노드를 쉽게 추가할 수 있고 데이터와 작업을 자동으로 분산하여
처리합니다. 데이터의 양이 급
'빅데이터 분석(with 아이티윌) > 리눅스' 카테고리의 다른 글
| [빅데이터분석] Linux_7.스파크 설치 및 운영 (3) | 2024.09.26 |
|---|---|
| [빅데이터분석] Linux_6. 몽고 디비(mongo db) 설치 및 운영관리 (1) | 2024.09.24 |
| [빅데이터분석] Linux_5. 하둡 설치 (0) | 2024.09.23 |
| [빅데이터분석] Linux_3. 리눅스함수 및 centos에 아나콘다 ,workbench 설치 (0) | 2024.09.23 |
| [빅데이터분석] Linux_2. 리눅스 함수 및 maria db 설치 (0) | 2024.09.23 |



