오라클 엑사 서버라는 서버가 있는데 2-3억 이상입니다. 오라클 엑사 서버가 빅데이터를 핸들링하는 지금까지 나온 제일 좋은 프로그램이자 서버입니다. 저렴한 비용으로 빅데이터를 다룰 수 있는 프로그램이 있는데 이게 바로 하둡입니다.
분산처리란 ?
데이터를 여러개의 서버들에 나눠서 저장하고 여러 서버들의 자원을 다 이용해서 데이터를 처리하는 것을 말합니다.
구글에서 구글의 쌓이는 빅데이터를 처음에는 오라클에 저장하려고 했는데 너무 데이터가 많아서 오라클에 저장하는것을 실패하고 나름의 방법으로 빅데이터를 저장하는 기술을 만들고 논문을 하나 발표했는데 그 논문을 더그커팅이라는 사람이 읽고 자바로 구현을 했습니다. 그리고 무료로 쓸수 있게 했습니다.
그게 하둡입니다.
hadoop 이란 이름은 더그커팅의 아들이 노란 코끼리 장난감을 가지고 놀다가 '하둡' 이라고 했다고해서 하둡이라고 지었다고 합니다.
하둡 생태계에 기생하게된 모든 프로그램들 이름이 다 동물 이름이 되었습니다.
* 데이터의 종류 3가지 ?
1. 정형화된 데이터 : emp 테이블과 같은 rdbms 에 저장된 테이블 형태의 데이터 2. 반정형화된 데이터 : html , 웹로그, json 파일 3. 비정형화된 데이터 : 동영상, 이미지, 텍스트 데이터
정형화 된 데이터는 주로 rdbms (오라클, mysql) database 에 저장하고 관리하며 검색합니다. 반정형화된 데이터와 비정형화된 데이터는 주로 '하둡' 에 저장을 하고 데이터 분석을 합니다.
※ 현업의 하둡 사용 예
텍스트 데이터 ------> "나는 스파게티아에서 스파게티를 먹었다."
rdbms 제품
vs
비 rdbms 제품
oracle (유료)
하둡 (무료)
mysql (유료)
maria db (무료)
postgre SQL (무료)
중요도가 높은 데이터는 ------> 회사내에 서버에 저장
중요도가 낮은 데이터는 -------> 클라우드(AWS) <--- 엘라스틱 서치(SQL) 구글 클라우드 <----- 구글 BigQuery ↓ 구독 서비스료
* 현업의 하둡 사용예( 6기의 안상준(딥러닝 개발자), 8기의 혜진(dba) )
1. 채팅방의 글 데이터(비정형 데이터)를 다 하둡에 저장합니다. 2. 특정 단어를 자주 사용하는 채팅방의 형태를 분석합니다. 3. 머신러닝을 이용해서 채팅 데이터를 학습 시키고 특정 단어를 사용하거나 불건전한 대화를 이끌 가능성이 높은 방을 미리 예측하고 그 확률이 높은것만 사람이 직접 모니터링 합니다. 그리고 채팅방을 자동 폐쇄 시킵니다.
* 현업의 미국 사례의 예:
뉴욕 타임즈는 130년 분량의 신문기사 1100만 페이지를 하둡을 이용해서 단 하루만에 pdf 로 변환햇습니다. 이때 든 비용이 200만원 밖에 안들었습니다. 만약에 하둡이 아닌 일반 서버를 사용햇다면 14년이 걸렸을 것으로 예상했습니다.
자주 물어보는 면접문제: 하둡 설치할 때 어떠한 어려움이 있었나요 ? (개발형 질문)
▩ 하둡 설치
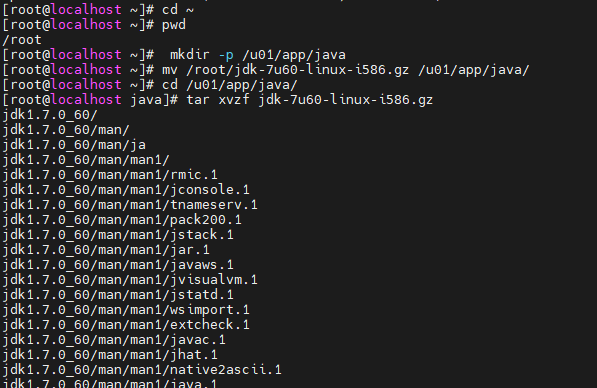
centos에 하둡설치파일.zip 압축을 풀면 아래의 3개의 파일이 생깁니다.
1. jdk-7u60-linux-i586.gz : 자바 설치 파일(하둡이 자바로 이루어져 있어서 먼저 설치) 2. hadoop-1.2.1.tar.gz : 하둡 설치 파일 3. protobuf-2.5.0.tar.gz : 서버간의 통신을 위한 프로그램 설치 파일
→ 우리반 30대의 컴퓨터를 마치 하나의 서버처럼 보이게 하는 프로그램이 하둡입니다.
■ 하둡 설치의 큰 그림
1. java 설치 -----> 하둡이 자바로 만들어져 있어서 자바를 설치해야합니다. ↓ 2. keygen 설치 ----> 여러 컴퓨터들을 묶어서 마치 하나의 컴퓨터 처럼 보이게 하는게 하둡의 목표이므로 컴퓨터들 끼리 서로 데이터를 전송할 때 접속을 해야하는데 접속할 때마다 패스워드 물어보면 통신할 때 제대로 운영이 안됩니다. 패스워드를 암호화 해서 저장해놓고 패스워드 없이 접속할 수 있게 셋팅해주는 작업 ↓ 3. 하둡설치 -----> 하둡설치는 아주 간단한데 그냥 4개의 파일의 내용만 수정하면 됩니다.
1. hadoop-env.sh : 자바 홈 디렉토리와 hadoop 홈 디렉토리가 어딘지 저장합니다. 2. core-site.xml : 하둡의 네임노드가 어느 서버인지 지정합니다. 3. mapred-site.xml : java 로 만들어진 mapreduce 프레임워크와 관련된 정보를 저장하는 파일 4. hdfs-site.xml : 하둡 파일 시스템인 HDFS(Hadoop Distributed File System) 와 관련된 정보를 저장하는 파일
▩ 하둡 구성도 1. 네임노드 : 메타 데이터(데이터의 위치 정보) 가 위치 하는 곳
2. 보조 네임 노드 : 네임노드 컴퓨터가 다운 되었을때를 대비해서 필요한 노드. 주기적으로 네임노드의 메타 데이터를 백업하면서 네임노드가 다운 되었을 때 사용하려고 준비하는 노드
3. 데이터 노드 : emp.csdv 와 같은 데이터들을 저장하는 컴퓨터들 ( 원본 1개과 백업본 2개를 항상 유지합니다 )
만약 우리가 우리반 컴퓨터 30대를 하둡 파일 시스템으로 구성한다면 네임노드 1대, 보조 네임노드 1대, 28대의 데이터 노드들로 구성되는 것입니다.
영화 "인셉션" 을 생각하면 되는데
현실 --------------------------> 꿈 -------------------------------> 꿈 ↓ ↓ ↓ 여러분 컴퓨터의 윈도우 ---------> 가상의 리눅스 서버 --------------> 하둡
[oracle@centos ~]$ su -
Password:
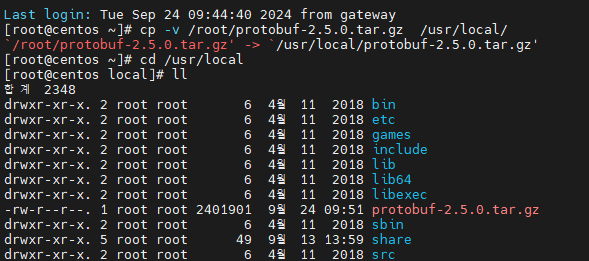
[root@centos ~]# cp -v /root/protobuf-2.5.0.tar.gz /usr/local/
[root@centos ~]# cd /usr/local
[root@centos local]# ll
[root@centos local]# tar xvfz protobuf-2.5.0.tar.gz
[root@centos local]# cd protobuf-2.5.0
[root@centos protobuf-2.5.0]# ./configure
[root@centos protobuf-2.5.0]# make
[root@centos protobuf-2.5.0]# make install
[root@centos protobuf-2.5.0]# protoc --version
libprotoc 2.5.0
시스템을 reboot 합니다.
[root@centos protobuf-2.5.0]# reboot
reboot 후에는 oracle 유져로 putty 로 접속합니다.
8. keygen 생성
하둡은 SSH 프로토컬을 이용해 하둡 클러스트간의 내부 통신을 수행한다. 하둡을 다 설치하고 나서 하둡을 시작하는 명령어인 start-all.sh 쉘 스크립트를 수행하면 네임노드가 설치된 서버에서 데이터 노드가 설치된 서버로 접근해 데이터 노드와 테스크 트래커를 구동하게 된다.
그런데 이때 ssh 를 이용할 수 없다면 하둡을 실행할 수 없다. 네임노드에서 공개키를 설정하고 이 공개키(authorized_keys) 를 다른 데이터 노드에 다 복사해줘야한다. 이 키를 가지고 있으면 ssh 로 다른 노드에 접속할때 패스워드 없이 접속할 수 있다.
## 공개키 생성
[oracle@centos ~]$ rm -rf .ssh
[oracle@centos ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/oracle/.ssh/id_rsa): 그냥 엔터
Created directory '/home/oracle/.ssh'.
Enter passphrase (empty for no passphrase): 그냥 엔터
Enter same passphrase again: 그냥 엔터
[oracle@centos ~]$ ssh-copy-id -i /home/oracle/.ssh/id_rsa.pub oracle@192.168.122.1 The authenticity of host '192.168.56.101 (192.168.56.101)' can't be established. ECDSA key fingerprint is 6b:de:64:c5:27:c4:c6:d7:62:2a:9c:fa:83:d5:65:13. Are you sure you want to continue connecting (yes/no)? yes <- 입력 /bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys oracle@192.168.122.1's password: 1234 <- 패스워드입력
# 공개키 잘 생성되었는지 확인 [oracle@centos ~]$ ssh oracle@192.168.122.1
Last login: Thu Aug 6 22:17:11 2020
※ 중요: 여기서 접속시 패스워드를 물어보면 안됩니다.
만약 패스워드를 물어봤다면 8번부터 다시 진행합니다.
9. hadoop 디렉토리를 만들고 거기에 하둡설치 파일 압축을 풉니다.
[oracle@centos ~]$ cd
[oracle@centos ~]$ mkdir hadoop
[oracle@centos ~]$ cd hadoop
root 유져로 접속하여 /root 밑에 있는 hadoop-1.2.1.tar.gz의 권한을 777 로 올립니다.
[oracle@centos]$ cd hadoop
[oracle@centos hadoop]$ pwd
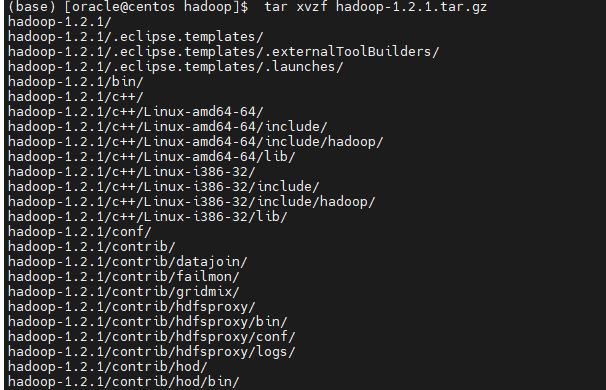
oracle 유져에서 hadoop-1.2.1.tar.gz 의 압축을 풉니다.
[oracle@centos hadoop]$ tar xvzf hadoop-1.2.1.tar.gz
[oracle@centos hadoop]$ rm hadoop-1.2.1.tar.gz
11. 하둡 홈 디렉토리를 설정한다.
다시 oracle 의 홈디렉토리로 옵니다.
[oracle@centos]$ cd
.bash_profile 을 열어 맨 아래에 아래의 내용을 추가합니다.
[oracle@centos ~]$ vi .bash_profile
#=====================================================
export HADOOP_HOME=/home/oracle/hadoop/hadoop-1.2.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#=====================================================
[oracle@centos ~]$ source .bash_profile
12. 하둡 환경설정을 하기 위해 아래의 4개의 파일을 셋팅해야 합니다.
1. hadoop-env.sh : 자바 홈디렉토리와 hadoop 홈디렉토리가 어딘지 지정한다.
2. core-site.xml : 하둡의 네임노드가 어느 서버인지를 지정한다.
3. mapred-site.xml : java 로 만들어진 mapreduce 프레임워크와 관련된 정보를 지정하는 파일
4. hdfs-site.xml : 하둡 파일 시스템인 HDFS(Hadoop Distributed File System) 와 관련된 정보를 저장하는 파일
앞으로 4개의 파일을 수정하는 부분이 정말 중요합니다. 하나씩 차근차근 진행하세요
[oracle@centos ~]$ cd $HADOOP_HOME/conf
[oracle@centos conf]$ vi hadoop-env.sh
#===================================================== # The java implementation to use. Required. # export JAVA_HOME=/usr/lib/j2sdk1.5-sun export JAVA_HOME=/u01/app/java/jdk1.7.0_60 export HADOOP_HOME=/home/oracle/hadoop/hadoop-1.2.1 export HADOOP_HOME_WARN_SUPPRESS=1 #=====================================================
[oracle@centos conf]$ cd /home/oracle/hadoop/hadoop-1.2.1/dfs
[oracle@centos dfs]$ chmod 755 data
[oracle@centos dfs]$ chmod 755 name
[oracle@centos dfs]$ ls -l
13. 하둡 네임노드를 포멧한다.
[oracle@centos dfs]$ cd
[oracle@centos ~]$ hadoop namenode -format
14/08/06 00:28:19 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = edydr1p2.us.oracle.com/192.168.100.102 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.1 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013 STARTUP_MSG: java = 1.7.0_60 ************************************************************/ Re-format filesystem in /u01/app/hadoop/hadoop-1.2.1/dfs/name ? (Y or N) Y (대문자) ...
14. 하둡파일 시스템을 올린다.
[oracle@centos ~]$ start-all.sh
15. 하둡파일 시스템의 데몬이 잘 올라왔는지 확인한다.
[oracle@centos ~]$ jps
위의 6개의 프로세서들이 잘 떠있으면 설치를 성공한것입니다.
※ 잘 안되었을 때의 조치 방법
1. 하둡을 모두 내립니다.
[oracle@centos conf]$ stop-all.sh
2.하둡 네임노드를 포멧한다.
[oracle@centos conf]$ cd [oracle@centos ~]$ hadoop namenode -format
3. 하둡 데이터 노드와 네임노드의 데이터를 다 지웁니다.
[oracle@centos dfs]$ cd /home/oracle/hadoop/hadoop-1.2.1/dfs
[oracle@centos dfs]$ ls data name [oracle@centos dfs]$ cd data [oracle@centos data]$ rm -rf * [oracle@centos data]$ cd ../name [oracle@centos name]$ rm -rf *