
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- count
- 순위출력
- 불순도제거
- 총과 카드만들기
- 빅데이터
- 빅데이터분석
- Sum
- 정보획득량
- 여러 데이터 검색
- Intersect
- 막대그래프
- max
- sql
- %in%
- 팀스파르타
- sqld
- merge
- 상관관계
- 히스토그램 그리기
- difftime
- 회귀분석 알고리즘
- 그래프시각화
- Dense_Rank
- 데이터분석
- loop 문
- 회귀분석
- 데이터분석가
- if문 작성법
- 단순회귀 분석
- 그래프 생성 문법
- Today
- Total
ch0nny_log
[빅데이터분석] Linux_1. 리눅스 설치 , 리눅스 함수 본문
※ 출처
리눅스 설치
1. 오라클 virtual box 다운로드 www.virtualbox.org/wiki/DownloadsDownloads – Oracle VM VirtualBoxDownload VirtualBox Here you will find links to VirtualBox binaries and its source code. VirtualBox
cafe.daum.net
※ 설치 프로그램
Downloads – Oracle VM VirtualBox
Oracle VirtualBox Extension Pack Personal Use and Educational License (PUEL) This VirtualBox Extension Pack Personal Use and Educational License governs your access to and use of the VirtualBox Extension Pack. It does not apply to the VirtualBox base packa
www.virtualbox.org
※ 리눅스 설치 방법
1. Oracle vm virtualbox 를 실행합니다.
2. 새로만들기를 누릅니다.
3. c 드라이브의 공간이 부족하므로 d 드라이브 밑에 oraclevm이라는 폴더를 만들고
그 폴더를 선택합니다.
4. 종류를 리눅스로 하고 버전을 oracle(64-bit) 로 선택합니다.
5. 계속 다음 버튼 누르다가 메모리는 2048로 하고
6. 계속 다음 버튼 누르다가 디스크 크기를 20gb 로 잡습니다.
7. 만들기를 누룹니다.
지금까지는 가상환경 컴퓨터를 만들건데 메모리는 2기가, 디스크는 20기가로 생성한것 입니다.
8. 리눅스14를 더블클릭을 하면 시동디스크 선택이 나옵니다.
9. 폴더 처럼 생긴것을 눌러서 아까 다운로드 받은 centos 설치파일을 선택합니다.
10. test this media & install centos 를 선택합니다. (방향키로 움직여야합니다)
11. 엔터를 치고 선택합니다.
12. 설치할 언어를 한글로 선택합니다.
13. 소프트웨어 선택을 누룹니다.
14. GNOME 데스트탑을 선택합니다.
15. GNOME 개발툴, 레거시 X 윈도우 , 개발용툴, 시스템 관리도구를 체크합니다.
16. 설치대상 누르고 완료를 누르면 경고 메세지가 없어지면서 설치시작 버튼이 활성화 됩니다.
17. root 암호는 1234로 합니다.
18. 사용자 생성을 누루고 계정명을 oracle, 비밀번호는 1234 로 합니다.
19. 재부팅을 누룹니다.
20. 라이센스 동의를 누르고 완료를 누룹니다.
21. 네트워크 및 호스트를 누룹니다. 이더넷을 켭니다. 그리고 완료를 누룹니다.
22. 설정완료를 누룹니다.
23. 로그인 화면에서 목록이 없습니까? 를 누룹니다.
24. 사용자 이름을 root 를 적습니다.
25. 패스워드는 1234 로 합니다.
■ 게스트 CD 확장 설치
1. root 로 접속한다.
2. 장치 ---> 게스트 확장 cd 삽입을 누룹니다.
3. 바로 실행하겠습니까라고 물어보면 바로 실행을 합니다.
4. 그게 아니라 그냥 바탕화면에 Vbox 의 큰 원형cd 모양이 생성만 되었다면 클릭해서 열고 상단 옆에 프로그램 실행을
눌러서 설치합니다
5. 재부팅 합니다. 재부팅할 때 반드시 리눅스 os 상에서 정상적으로 재부팅합니다.
방법이 터미널창을 열고 reboot 라고 하면 됩니다.
6. 재부팅하고 root 로 접속합니다
※ 설치후
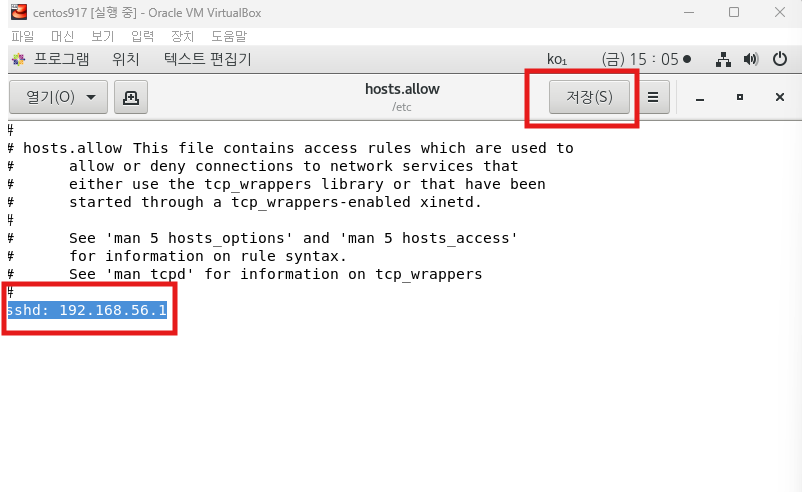
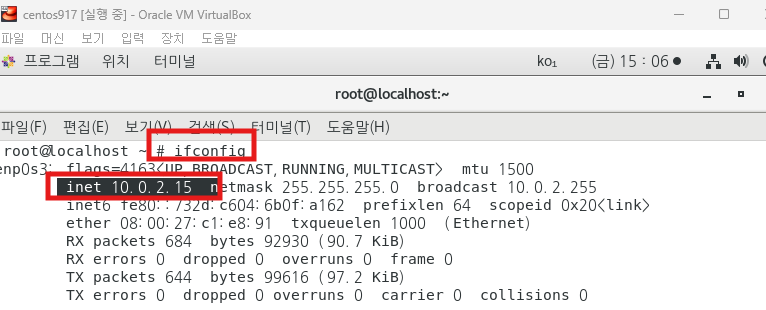
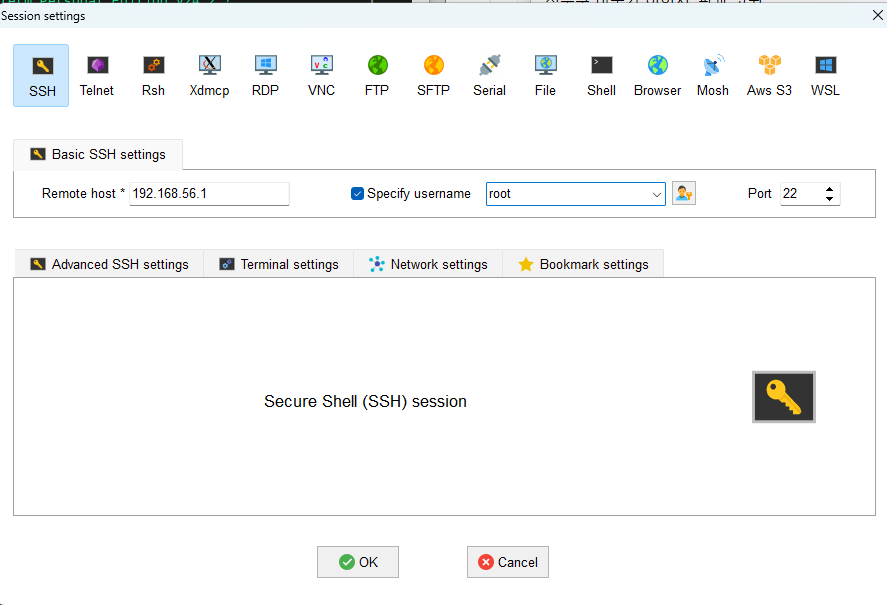
putty
putty 로 리눅스 서버에 접속하는 방법
1. 첫번째로 설정 다음 작업은 모두 root 로 접속해서 작업하세요 파일-- 호스트 네트워크 관리자를 엽니다. 아래의 아이피 주소(192.168.56.1) 를 확인합니다. 2. 두번째로 설정 리눅스에서 터
cafe.daum.net
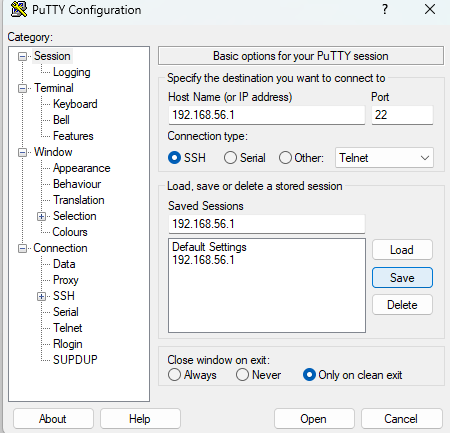
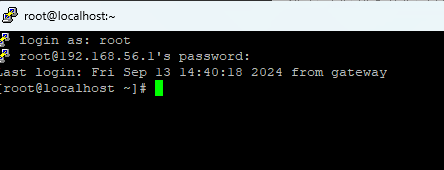
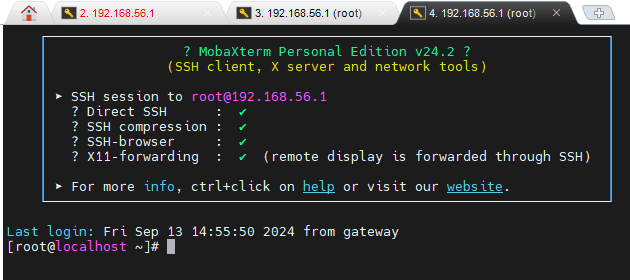
moba x
비밀번호(7자리 생성)
※ 데이터 업로드
-> 파일 업로드
-> 파일 확인
★ 나중에 시간을 내서 따로 해봐야할 작업들?
1. 최신 버젼 centos 를 설치하고 putty 로 접속, 모바텀으로 접속
▣ 리눅스 기본 명령어1. cd 명령어
Change Directory 명령어로 디렉토리를 이동할 때 사용하는 명령어입니다.
예:
# pwd <--- 현재 내가 어디있는지 확인
# ls <--- 현재 디렉토리에 있는 폴더와 파일을 확인하는 명령어
# mkdir test <---- test 라는 폴더를 만드는 명령어
# cd test <--- test 디렉토리로 이동하는 명령어
# pwd
# cd .. <--- 상위 디렉토리를 이동하는 명령어
# pwd
문제1. 현재 디렉토리(/root) 에 test2 라는 폴더를 만들고 test2 로 이동하시오
# ls # cd test2문제2. 지금 현재 있는 test2 디렉토리에서 상위 디렉토리로 이동하시오.
#cd.. #pwd
▣ 리눅스 기본 명령어2. mkdir 명령어
" 디렉토리를 생성하는 명령어"
예:
# mkdir bigdata
# ls
문제. 현재 디렉토리 밑으로 data/data2/data3/data4 디렉토리를 만드시오!
# mkdir -p data/data2/data3/data4 # ls
※ -p 옵션은 디렉토리를 만들때 한번에 하위 디렉토리를 여러개 생성하는 옵션
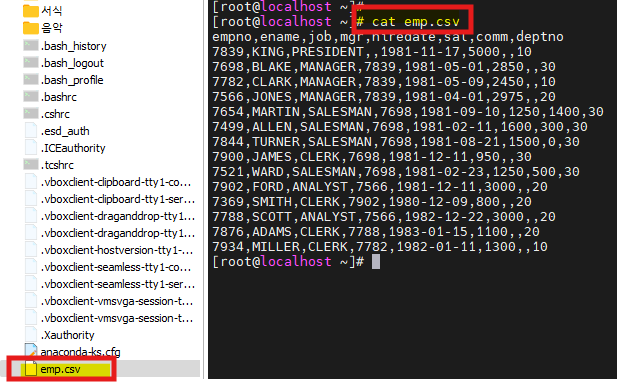
▣ 리눅스 기본 명령어3. cat 명령어
" 파일의 내용을 화면에 출력하는 명령어"
예제.
# ls emp.csv # cat emp.csv

문제1. emp.csv에서 salesman 이라는 단어가 포함된 행을 출력하시오,
# cat emp.csv | grep -i 'SALESMAN'

문제2. emp.csv에서 SCOTT 이라는 단어가 포함된 행을 출력하시오,
# cat emp.csv | grep -i 'SCOTT'

▣ 리눅스 기본 명령어4. grep 명령어
"파일 안에 포함된 특정 단어나 구문을 검색하는 명령어"
예제1. emp.csv 에서 데이터 scott 이라는 단어가 포함된 행을 출력하시오
# grep -i 'scott' emp.csv

예제2. emp.csv 에서 데이터의 scott 이라는 단어가 포함된 행의 2번째 6번째 3번째 컬럼을 출력하시오
# grep -i 'scott' emp.csv | awk -F ',' '{print $2, $6, $3}' 설명: grep 은 행을 선택하는것이고 awk 는 컬럼을 선택하는것입니다.
문제1. 직업이 salesman인 사원들의 이름,월급, 직업을 출력하시오.
# grep -i 'salesman' emp.csv | awk -F ',' '{print $2, $6, $3}'

문제2. 부서번호가 10번인 사원들의 이름과 월급, 부서번호를 출력하시오
# grep -i '10' emp.csv | awk -F ',' '{print $2, $6, $8}'
위의 문제를 grep 으로 풀기 어렵습니다 그래서 필요한게 awk 입니다.# awk -F ',' '$8==10 {print $2,$6,$8}' emp.csv


▣ 리눅스 명령어5. awk 명령어
"특정 조건과 특정 컬럼의 데이터를 파일에서 검색하고자 할 때 사용하는 명령어"
예: awk -F ',' '$8==10 {print $2, $6, $8}' emp.csv
※ 리눅스의 연산자 3가지 ?
1. 산술 연산자 : + - * /
2. 비교 연산자 : >, <, >=, <=, ==, !=
3. 논리 연산자 : &&, ||, !
문제1. 월급이 3000 이상인 사원들의 이름과 월급을 출력하시오 !
# awk -F ',' '$6 >= 3000 {print $2, $6}' emp.csv

문제 2. 직업이 salesman이 아닌 사원들의 이름과 직업을 출력하시오.
# awk -F ',' '$3 != 'SALESMAN' {print $2,$3}' emp.csv

문제 3. 문제 2번의 결과를 csv 파일로 생성하시오.
>> 를 redirection 이라고 함. (어떤 명령어의 결과를 파일로 생성할 때 사용하는 명령어)# awk -F ',' '$3 !='SALESMAN' {print $2,$3}' emp.csv >> notsalesman.csv
문제4. notsalesman.csv 의 공백을 콤마(,) 로 변경하시오 !
# sed 's/ /,/g' notsalesman.csv >> notsalesman2.csv # cat notsalesman2.csv
문제 5. 직업이 salesman 이고 월급이 1200이상인 사원들의 이름,월급,직업을 출력하시오
# awk -F ',' '$3 =='SALESMAN' && $6 >=1200{print $2, $6, $3}' emp.csv
문제 6. 위의 결과를 result1.csv로 저장하시오.
# awk -F ',' '$3 =='SALESMAN' && $6 >=1200{print $2, $6, $3}' emp.csv >> result1.csv # sed 's/ /,/g' result2.csv >> result2.csv # cat result2.csv
문제 7. 직업이 salesman, analyst 인 사원의 이름, 월급, 직업을 출력하시오.
awk -F ',' '$3=="SALESMAN" || $3=="ANALYST" {print $2, $6, $3}' emp.csv

문제 8. 부서번호가 10, 20번인 사원들의 이름과 월급, 직업, 부서번호를 result 2.csv로 생성하시오
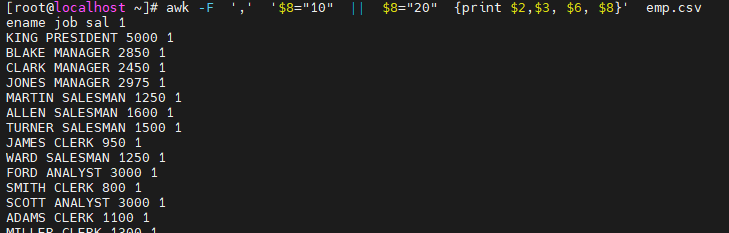
# awk -F ',' '$8=="10" || $8=="20" {print $2,$3, $6, $8}' emp.csv >> result2.csv # sed 's/ /,/g' result2.csv >> result2.csv # cat result2.csv
'빅데이터 분석(with 아이티윌) > 리눅스' 카테고리의 다른 글
| [빅데이터분석] Linux_7.스파크 설치 및 운영 (3) | 2024.09.26 |
|---|---|
| [빅데이터분석] Linux_6. 몽고 디비(mongo db) 설치 및 운영관리 (1) | 2024.09.24 |
| [빅데이터분석] Linux_5. 하둡 설치 (0) | 2024.09.23 |
| [빅데이터분석] Linux_3. 리눅스함수 및 centos에 아나콘다 ,workbench 설치 (0) | 2024.09.23 |
| [빅데이터분석] Linux_2. 리눅스 함수 및 maria db 설치 (0) | 2024.09.23 |



