import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter # 텍스트 데이터에서 단어를 카운트하는 모듈
# 텍스트 파일 열기 (with 절을 써서 열면 파이썬이 알아서 파일을 닫습니다.)
with open("c:\\data\\joongang.txt", "r", encoding="utf-8") as file:
text = file.read()
# 텍스트를 엔터로 분리합니다.
lines = text.split('\n')
# Couter 모듈을 객체화 합니다.
date_counts = Counter()
current_date = None
# 2024년으로 시작하는 라인만 추출(기사 날짜와 제목을 추출)
for line in lines:
if line.startswith('2024-'):
current_date = line[:10] # 날짜만 추출
if current_date and '인공지능' in line: # 현재 날짜이면서 인공지능을 포함하기
#print( line.count('인공지능'))
date_counts[current_date] += line.count('인공지능')
#print(date_counts) # {'2024-08-13': 19, '2024-08-14': 12, '2024-08-12': 4}
# 판다스 데이터 프레임으로 구성
df = pd.DataFrame(list(date_counts.items()), columns=['date','count'])
# 날짜를 datetime 형식으로 변환
df['date'] = pd.to_datetime(df['date'])
df
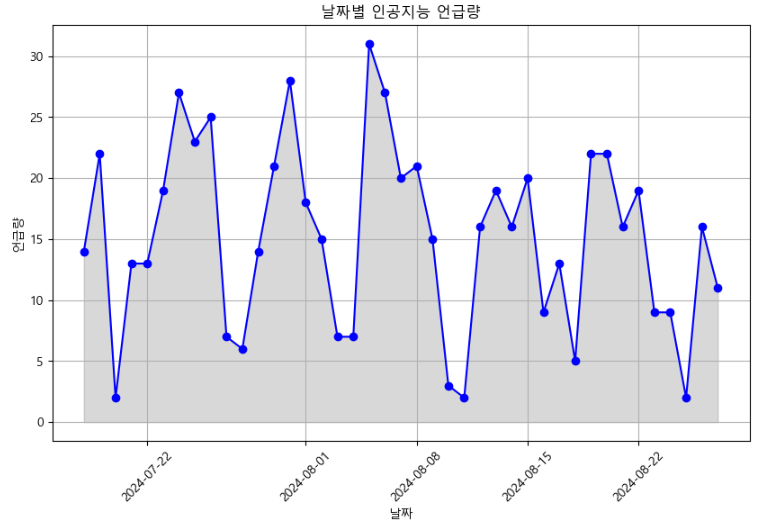
3. 시각화 하기
# 시각화
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc # 한글 폰트 깨지지 않게
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
# 시각화 하기
plt.figure(figsize=(10,6) ) # 가로 10, 세로 6으로 그래프 사이즈 설정
plt.plot( df['date'], df['count'], marker='o', color='b')
plt.fill_between(df['date'], df['count'], color="gray", alpha=0.3)
plt.title('날짜별 인공지능 언급량')
plt.xlabel('날짜')
plt.ylabel('언급량')
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
4. 오늘 기준 중앙일보에서 '인공지능' 웹 스크롤링 후 시각화 하기
chj.ja('인공지능',20)
5. 피크값의 날짜를 가져오게 코드 수정하기
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter # 텍스트 데이터에서 단어를 카운트하는 모듈
# 텍스트 파일 열기 (with 절을 써서 열면 파이썬이 알아서 파일을 닫습니다.)
with open("c:\\data\\joongang.txt", "r", encoding="utf-8") as file:
text = file.read()
# 텍스트를 엔터로 분리합니다.
lines = text.split('\n')
# Couter 모듈을 객체화 합니다.
date_counts = Counter()
current_date = None
# 2024년으로 시작하는 라인만 추출(기사 날짜와 제목을 추출)
for line in lines:
if line.startswith('2024-'):
current_date = line[:10] # 날짜만 추출
if current_date and '인공지능' in line: # 현재 날짜이면서 인공지능을 포함하기
#print( line.count('인공지능'))
date_counts[current_date] += line.count('인공지능')
#print(date_counts) # {'2024-08-13': 19, '2024-08-14': 12, '2024-08-12': 4}
# 판다스 데이터 프레임으로 구성
df = pd.DataFrame(list(date_counts.items()), columns=['date','count'])
# 날짜를 datetime 형식으로 변환
df['date'] = pd.to_datetime(df['date'])
# 시각화
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc # 한글 폰트 깨지지 않게
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
# 시각화 하기
plt.figure(figsize=(10,6) ) # 가로 10, 세로 6으로 그래프 사이즈 설정
plt.plot( df['date'], df['count'], marker='o', color='b')
plt.fill_between(df['date'], df['count'], color="gray", alpha=0.3)
# 피크 값의 날짜를 가져오기
peak_indics = df[df['count'] == df['count'].max()].index
for i in peak_indics:
plt.text(df['date'][i], df['count'][i]+ 0.5, df['date'][i].strftime('%Y-%m-%d'),
color='red', fontsize= 12)
plt.title('날짜별 인공지능 언급량')
plt.xlabel('날짜')
plt.ylabel('언급량')
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
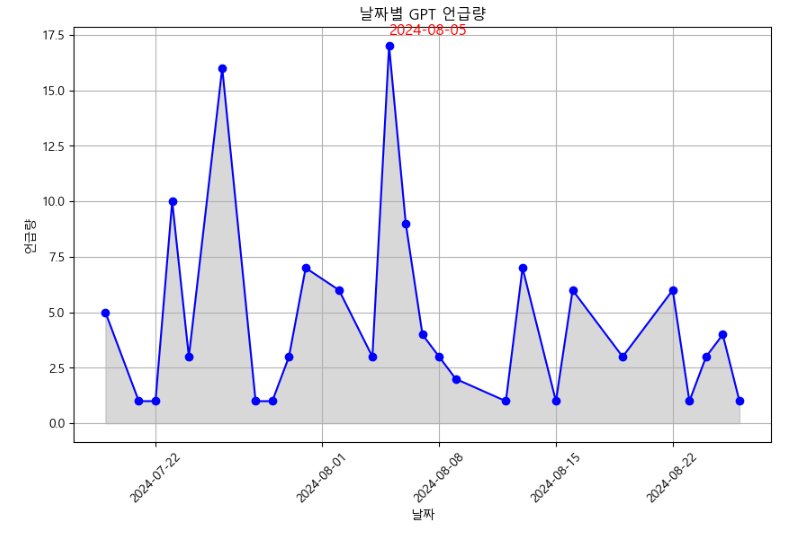
+ 추가문제) GPT 언급량이 많았던 날이 언젠지 확인하기
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter # 텍스트 데이터에서 단어를 카운트하는 모듈
# 텍스트 파일 열기 (with 절을 써서 열면 파이썬이 알아서 파일을 닫습니다.)
with open("c:\\data\\joongang.txt", "r", encoding="utf-8") as file:
text = file.read()
# 텍스트를 엔터로 분리합니다.
lines = text.split('\n')
# Couter 모듈을 객체화 합니다.
date_counts = Counter()
current_date = None
# 2024년으로 시작하는 라인만 추출(기사 날짜와 제목을 추출)
for line in lines:
if line.startswith('2024-'):
current_date = line[:10] # 날짜만 추출
if current_date and 'GPT' in line: # 현재 날짜이면서 GPT을 포함하기
#print( line.count('인공지능'))
date_counts[current_date] += line.count('GPT')
#print(date_counts) # {'2024-08-13': 19, '2024-08-14': 12, '2024-08-12': 4}
# 판다스 데이터 프레임으로 구성
df = pd.DataFrame(list(date_counts.items()), columns=['date','count'])
# 날짜를 datetime 형식으로 변환
df['date'] = pd.to_datetime(df['date'])
# 시각화
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc # 한글 폰트 깨지지 않게
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
# 시각화 하기
plt.figure(figsize=(10,6) ) # 가로 10, 세로 6으로 그래프 사이즈 설정
plt.plot( df['date'], df['count'], marker='o', color='b')
plt.fill_between(df['date'], df['count'], color="gray", alpha=0.3)
# 피크 값의 날짜를 가져오기
peak_indics = df[df['count'] == df['count'].max()].index
for i in peak_indics:
plt.text(df['date'][i], df['count'][i]+ 0.5, df['date'][i].strftime('%Y-%m-%d'),
color='red', fontsize= 12)
plt.title('날짜별 GPT 언급량')
plt.xlabel('날짜')
plt.ylabel('언급량')
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
문제1. 언급량 분석 코드 전체를 함수로 만들어서 다음과 같이 실행되게 하시오.
함수명: relation_word_ja(keyword)
1) "c:\\data\\joongang.txt" 가 있다는 가정
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter # 텍스트 데이터에서 단어를 카운트하는 모듈
def relation_word_ja(keyword):
# 텍스트 파일 열기 (with 절을 써서 열면 파이썬이 알아서 파일을 닫습니다.)
with open("c:\\data\\joongang.txt", "r", encoding="utf-8") as file:
text = file.read()
# 텍스트를 엔터로 분리합니다.
lines = text.split('\n')
# Counter 모듈을 객체화 합니다.
date_counts = Counter()
current_date = None
# 2024년으로 시작하는 라인만 추출(기사 날짜와 제목을 추출)
for line in lines:
if line.startswith('2024-'):
current_date = line[:10] # 날짜만 추출
if current_date and keyword in line: # 현재 날짜이면서 키워드가 포함된 경우
date_counts[current_date] += line.count(keyword)
# 판다스 데이터 프레임으로 구성
df = pd.DataFrame(list(date_counts.items()), columns=['date', 'count'])
# 날짜를 datetime 형식으로 변환
df['date'] = pd.to_datetime(df['date'])
# 시각화
from matplotlib import font_manager, rc # 한글 폰트 깨지지 않게
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
# 시각화 하기
plt.figure(figsize=(10, 6)) # 가로 10, 세로 6으로 그래프 사이즈 설정
plt.plot(df['date'], df['count'], marker='o', color='b')
plt.fill_between(df['date'], df['count'], color="gray", alpha=0.3)
# 피크 값의 날짜를 가져오기
peak_indices = df[df['count'] == df['count'].max()].index
for i in peak_indices:
plt.text(df['date'][i], df['count'][i] + 0.5, df['date'][i].strftime('%Y-%m-%d'),
color='red', fontsize=12)
plt.title(f'날짜별 {keyword} 언급량')
plt.xlabel('날짜')
plt.ylabel('언급량')
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
# 예제 호출
relation_word_ja('사람')