# 패키지 설치 및 라이브러리 로드
install.packages("wordcloud2")
install.packages("tm")
install.packages("RColorBrewer")
install.packages("plyr")
install.packages("data.table")
install.packages("patchwork")
install.packages("htmlwidgets")
install.packages("webshot")
install.packages("magick")
install.packages("ggplot2")
install.packages("grid")
library(wordcloud2)
library(tm)
library(RColorBrewer)
library(plyr)
library(data.table)
library(patchwork)
library(htmlwidgets)
library(webshot)
library(magick)
library(ggplot2)
library(grid)
# PhantomJS 설치
webshot::install_phantomjs()
# 텍스트 데이터 로드
setwd('c:\\data')
jobs_file_path <- "jobs.txt"
positive_words_file <- "positive-words.txt"
negative_words_file <- "negative-words.txt"
jobs_txt <- readLines(jobs_file_path, encoding = "UTF-8")
positive_words <- readLines(positive_words_file, encoding = "UTF-8")
negative_words <- readLines(negative_words_file, encoding = "UTF-8")
# 특수문자 제거 및 공백 처리
cleaned_txt <- iconv(jobs_txt, "UTF-8", "UTF-8", sub="")
cleaned_txt <- gsub("[^[:alnum:][:space:]]", " ", cleaned_txt)
cleaned_txt <- gsub("\\s+", " ", cleaned_txt)
# 텍스트를 Corpus로 변환
corpus <- VCorpus(VectorSource(cleaned_txt))
# 데이터 전처리
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removeWords, stopwords("en"))
corpus <- tm_map(corpus, stripWhitespace)
# 단어 행렬 생성
dtm <- TermDocumentMatrix(corpus)
m <- as.matrix(dtm)
word_freqs <- sort(rowSums(m), decreasing = TRUE)
word_freq_df <- data.frame(word = names(word_freqs), freq = word_freqs)
# 긍정 단어 및 부정 단어 필터링
positive_word_freq_df <- word_freq_df[word_freq_df$word %in% positive_words, ]
negative_word_freq_df <- word_freq_df[word_freq_df$word %in% negative_words, ]
# 상위 100개의 단어만 선택
positive_word_freq_df <- head(positive_word_freq_df, 100)
negative_word_freq_df <- head(negative_word_freq_df, 100)
# 워드 클라우드 생성
positive_cloud <- wordcloud2(data = positive_word_freq_df, shape = "circle", color = brewer.pal(8, "Dark2"))
negative_cloud <- wordcloud2(data = negative_word_freq_df, shape = "circle", color = brewer.pal(8, "Reds"))
# htmlwidgets로 각각의 워드 클라우드를 저장
saveWidget(positive_cloud, "positive_cloud.html", selfcontained = TRUE)
saveWidget(negative_cloud, "negative_cloud.html", selfcontained = TRUE)
# 두 개의 htmlwidgets을 한 화면에 표시
webshot("positive_cloud.html", file = "positive_cloud.png", delay = 10)
webshot("negative_cloud.html", file = "negative_cloud.png", delay = 10)
# magick으로 이미지 불러오기
positive_img <- image_read("positive_cloud.png")
negative_img <- image_read("negative_cloud.png")
# ggplot으로 이미지 변환
positive_plot <- ggplot() +
annotation_custom(rasterGrob(positive_img, width=unit(1,"npc"), height=unit(1,"npc"))) +
theme_void()
negative_plot <- ggplot() +
annotation_custom(rasterGrob(negative_img, width=unit(1,"npc"), height=unit(1,"npc"))) +
theme_void()
# patchwork로 두 이미지를 하나의 화면에 표시
combined_plot <- positive_plot + negative_plot
# 플롯 출력
print(combined_plot)
소셜 네트워크 그래프라고도 불리는 사회 연결망 그래프가 필요한 이유
1. 관계 및 연결분석
네트워크에서 중요한 역할을 하는 중심인물이나 허브를 식별할 수 있음
2. 정보 및 영향력 전파
특정 주제나 분야에서 영향력이 큰 사람을 찾아 낼 수 있음
3. 사회적 행동 및 패턴 분석
사람들의 행동 패턴과 상호작용 방식을 분석 할 수 있음
4. 문제 탐지 및 해결 네트워크 내에서 문제 및 갈등이 발생 가능성이 높은 영역을 식별할 수 있음.
문법1. 아이티 회사들의 소송관계를 사회 연결망으로 시각화 해서 확인하시오!
#1. 데이터 로드
node_df <- read.csv("c:\\data\\node2.csv")
link_df <- read.csv("c:\\data\\link2.csv")
node_df
link_df
#2. 시각화
install.packages("networkD3")
install.packages("dplyr")
library(networkD3)
library(dplyr)
network1 <- forceNetwork( Links=link_df, # 소송 관계도 데이터 프레임명
Nodes=node_df, # 회사이름, 회사번호가 있는 데이터 프레임명
Source='source_idx', # 소송하는 회사번호
Target='target_idx', # 소송당하는회사번호
NodeID='node', # 회사명
Group='idx', # 회사번호
opacityNoHover=TRUE, # 정적일때 불투명 정도
zoom=TRUE, # FALSE 로 하면 해당 노드의 동그라미만 보이고 TRUE 로 하면
# 연관된 회사들이 선명하게 보입니다.
bounded=TRUE, # 그래프가 화면 밖으로 빠져나가지 않게 한다.
fontSize=15, # 글씨크기
linkDistance=75, # 연결선의 길이
opacity=0.9 ) # 불투명 정도
network1
# 1. 데이터를 로드
setwd("c:\\data")
node_df <- read.csv("node3.csv", fileEncoding='euc-kr')
link_df <- read.csv("link3.csv",fileEncoding= 'euc-kr')
node_df
link_df
# 2. 시각화
# install.packages("networkD3")
# install.packages("dplyr")
library(networkD3)
library(dplyr)
network <- forceNetwork( Links=link_df,
Nodes=node_df,
Source='source_idx',
Target='target_idx',
NodeID='node',
Group='idx',
opacityNoHover=TRUE, # 정적일때 불투명 정도
zoom=TRUE, # FALSE 로 하면 해당 노드의 동그라미만 보이고 TRUE 로 하면
# 연관된 회사들이 선명하게 보입니다.
bounded=TRUE, # 그래프가 화면 밖으로 빠져나가지 않게 한다.
fontSize=15, # 글씨크기
linkDistance=75, # 연결선의 길이
opacity=0.9 ) # 불투명 정도
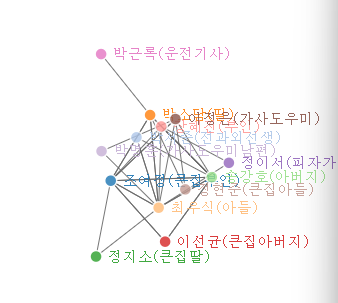
network # 인물들끼리 연결망
문제2.영화 기생충 igraph 로 시각화
library(igraph) # 복잡한 네트워크 분석과 시각화를 위한 기능을 제공하는 패키지
# 데이터 파일 읽기
node_df <- read.csv("c:\\data\\node3.csv", fileEncoding ="euc-kr")
link_df <- read.csv("c:\\data\\link3.csv", fileEncoding ="euc-kr")
# 엣지(간선) 데이터 프레임 생성( 배우들끼리 만난 장면)
a <- link_df[, c("source_idx", "target_idx")]
# 그래프 생성, directed=TRUE 를 써야 그래프가 방향성을 가집니다.
b <- graph.data.frame(a, directed = TRUE)
# 노드 이름 설정, 노드(정점) 객체인 V(b) 에 접근하여 각 노드의 이름을 node_df 데이터
# 프레임의 node 열 값으로 설정합니다.
V(b)$name <- node_df$node
# 레이아웃 설정, 그래프를 시각화해서 보기 좋도록 레이아웃을 설정합니다.
layout <- layout_with_fr(b)
# 그래프 플로팅
plot(b, layout = layout, # 설정한 레이아웃을 사용하여 그래프를 배치
vertex.label = V(b)$name, # V(b)$name 은 각 노드의 이름 레이블을 표시합니다.
vertex.size = 30, # 노드의 크기를 30으로 설정합니다.
vertex.label.cex = 0.8, # 노드 레이블의 크기 설정
edge.arrow.size = 0.5, # 엣지 화살표의 크기를 설정
vertex.color = "orange", # 노드의 색깔
vertex.label.color = "black") # 레이블의 색깔