
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- %in%
- 데이터분석가
- 그래프 생성 문법
- 히스토그램 그리기
- 그래프시각화
- sqld
- 순위출력
- 빅데이터
- 불순도제거
- Sum
- 단순회귀 분석
- 상관관계
- 여러 데이터 검색
- sql
- if문 작성법
- 빅데이터분석
- Intersect
- 막대그래프
- Dense_Rank
- loop 문
- merge
- 팀스파르타
- 총과 카드만들기
- 데이터분석
- difftime
- 회귀분석
- 회귀분석 알고리즘
- max
- count
- 정보획득량
Archives
- Today
- Total
ch0nny_log
[빅데이터분석] R _ 29. 집합연산(rbind, rbind + unique,intersect,setdiff) 본문
빅데이터 분석(with 아이티윌)/R
[빅데이터분석] R _ 29. 집합연산(rbind, rbind + unique,intersect,setdiff)
chonny 2024. 7. 1. 11:06| ※ 집합연산자 | |||
| SQL | VS | R | |
| union all | rbind | ||
| union | rbind + unique | ※ RBIND 는 두개의 결합집합을 위아래 출력하고 싶을 때 사용하는 함수 ※ CBIND는 두개의 결과 집합을 양 옆으로 출력하고 싶을 때 사용하는 함수 |
|
| intersect | intersect | ||
| minus | setdiff | ※ SETDIFF 의 경우 R에 내장된 SETDIFF를 사용하면 안되고 DPLYR패키지에서의 SETDIFF를 사용해야함 |
|
■ RBIND
문제1. 아래의 SQL을 R로 구현하시오.
1) SQL
2) Rselect ename, sal, deptno from emp where deptno in ( 10 , 20 ) union all select ename, sal, deptno from emp where deptno = 20;
x1 <- emp[emp$deptno %in% c(10,20),c('ename','sal','deptno')] x2 <- emp[emp$deptno ==20 ,c('ename','sal','deptno')] rbind(x1,x2)설명: rbind(x1,x2) 는 x1의 결과와 x2의 결과를 위아래로 출력하겠다는 뜻임

문제2. 아래의 SQL을 R로 구현하시오.
1) SQL
select deptno, sum(sal) from emp group by rollup(deptno);
2) Rx1 <- aggregate(sal~deptno, emp,sum) x2 <- c(' ', sum(emp$sal)) x3 <- rbind(x1,x2) colnames(x3) <- c('부서번호','토탈월급') x3

문제3. 아래의 SQL의 결과를 R 로 구현하시오 !
1) SQL
2) Rselect job, sum(sal) from emp group by cube(job);
x1 <- aggregate(sal~deptno, emp,sum) x2 <- c(' ', sum(emp$sal)) x3 <- rbind(x2,x1) colnames(x3) <- c('부서번호','토탈월급') x3

■ RBIND + UNIQUE (중복제거)
문제 1. 아래의 SQL의 결과를 R 로 구현하시오 !
1) SQL
select ename, sal, deptno from emp where deptno in ( 10, 20 ) union select ename, sal, deptno from emp where deptno = 10;
2) R
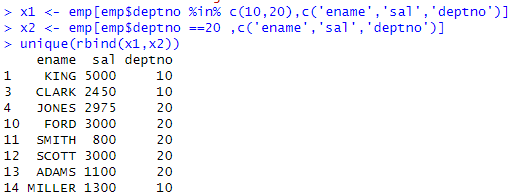
x1 <- emp[emp$deptno %in% c(10,20),c('ename','sal','deptno')] x2 <- emp[emp$deptno ==20 ,c('ename','sal','deptno')] unique(rbind(x1,x2))
■ SETDIFF
문제1. 아래의 SQL의 결과를 R 로 구현하시오 !
1) SQL
select ename, sal, deptno from emp where deptno in ( 10, 20 ) minus select ename, sal, deptno from emp where deptno = 10;
2) R
# dplyr 패키지 설치 install.packages('dplyr') library(dplyr) # 차집합 x1 <- emp[emp$deptno %in% c(10,20),c('ename','sal','deptno')] x2 <- emp[emp$deptno ==20 ,c('ename','sal','deptno')] setdiff(x1,x2)※ setdiff 함수가 이름이 중복되어 있습니다. 내장 함수 setdiff 도 있고 dplyr 패키지의 setdiff 도 있습니다. 그런데 dplyr 의 setdiff 를 쓰기 위해서 library(dplyr) 를 해주면 내장 함수를 불러오지 않고 dplyr 패키지의 setdiff 를 불러옵니다. ※ 코렙에서는 그냥 library(dplyr) 만 하면 됩니다.

문제2. emp2.csv에는 존재하는데 emp.csv에는 존재하지 않는 데이터가 무엇인지 출력하시오.
# emp.csv와 emp2.csv 파일 읽기 emp <- read.csv("emp.csv", header=T) emp2 <- read.csv("emp2.csv", header=T) # emp2에만 존재하는 데이터 찾기 setdiff(emp2, emp) setdiff(emp, emp2)

■ INTERSECT
문제1. 아래의 SQL의 결과를 R 로 구현하시오 !
1) SQL
select ename, sal, deptno from emp where deptno in ( 10, 20 ) intersect select ename, sal, deptno from emp where deptno = 10;2) R
# 패키지 불러오기 library(dplyr) # 교집합 x1 <- emp[emp$deptno %in% c(10,20),c('ename','sal','deptno')] x2 <- emp[emp$deptno ==20 ,c('ename','sal','deptno')] intersect(x1,x2)

문제 2. emp2.csv과 emp.csv 테이블의 교집합은?
intersect(emp2, emp)

문제 3. (빅분기 유형1번) emp.csv 와 emp2.csv 와의 교집합의 갯수를 출력하시오!
## nrow 함수: 데이터 프레임의 건수를 세는 힘수library(dplyr) cnt <- intersect(emp2, emp) print(nrow(cnt))
## ncol 함수: 데이터 프레임의 컬럼수를 세는 함수
-> 컬럼 하나의 갯수를 구할 때는 length를 쓰고 데이터 프레임의 전체 건수를 구할때는 nrow를 씁니다.
length(emp$empno)
'빅데이터 분석(with 아이티윌) > R' 카테고리의 다른 글
| [빅데이터분석] R _ 31. 순위 출력 (rank) (0) | 2024.07.01 |
|---|---|
| [빅데이터분석] R _ 30. 서브쿼리 (0) | 2024.07.01 |
| [빅데이터분석] R _ 28. Google Colab (1) | 2024.07.01 |
| [빅데이터분석] R _ 27. EQUI JOIN/OUTER JOIN/SELF JOIN (0) | 2024.06.28 |
| [빅데이터분석] R _ 26. GROUP BY절 두개의 컬럼 사용 (0) | 2024.06.28 |
'빅데이터 분석(with 아이티윌)/R' Related Articles
more



