from google.colab import drive
drive.mount('/content/drive')
!pip install ultralytics
import cv2
from ultralytics import YOLO
import numpy as np
from google.colab.patches import cv2_imshow #코랩에서 이미지를 보여주기 위해 필요
from collections import deque # file 입력과 출력 관련한 자료구조 (사람 카운트)
# YOLOv8 모델 불러오기
model = YOLO('yolov8n.pt') #욜로 나노 버전인데 80개의 클래스를 자동 인식
# 비디오 캡처 초기화
cap = cv2.VideoCapture("/content/drive/MyDrive/yolonew/newyork.mp4")
# 비디오 저장 설정
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter("/content/drive/MyDrive/yolonew/output2_with_counts.mp4", fourcc, 30.0,
(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))))
# 카운팅 변수 초기화
total_in_count = 0 # 누적 입장 수
total_out_count = 0 # 누적 퇴장 수
detected_ids = {} #객체 id 와 좌표를 저장할 딕셔너리
next_id = 0 #새로운 객체에 부여할 고유 id
exit_buffer = 30 # ID가 삭제되기 전까지 유지되는 프레임 수
id_buffer = deque(maxlen=50) # 최근 ID 기록용
while cap.isOpened(): #비디오가 열려있는 동안 루프를 반복
ret, frame = cap.read() #프레임을 하나씩 읽어오기 ret은 읽기 성공여부
if not ret: #프레임이 없으면 루프를 중단
break
# 객체 탐지 수행
results = model(frame)
current_ids = set() # 현재 프레임에서 감지된 ID를 저장할 집합
for det in results[0].boxes: #감지된 객체 각각에 대해 반복 처리 하기
x1, y1, x2, y2 = map(int, det.xyxy[0]) # 박스 좌표 <- 도둑 잡아내는 모델에서는 굉장히 중요한 파트
conf = det.conf[0].item() # 박스에 있는 물체가 사람일 확률에 대한 신뢰도
cls = int(det.cls[0].item()) # 클래스
if cls == 0 and conf > 0.5: # 클래스 0은 사람, 이걸 조절하면 사람이라고 카운트 하는 것을 늘릴 수 있음
# 중심 좌표 계산
center_x = int((x1 + x2) / 2)
center_y = int((y1 + y2) / 2)
# ID 생성 및 관리
object_id = None #객체 id를 초기화
#같은 사람이 걸어다녀도 같은 사람임을 확인하는 코드
for id, (prev_x, prev_y, frames) in detected_ids.items():
if abs(prev_x - center_x) < 50 and abs(prev_y - center_y) < 50:
object_id = id
detected_ids[id] = (center_x, center_y, exit_buffer) # 프레임 수 초기화
break
if object_id is None: # 다시 새로운 사람이면
object_id = next_id
detected_ids[object_id] = (center_x, center_y, exit_buffer)
next_id += 1 # 기존 객체 번호에 1을 더해서 객체 번호 부여
total_in_count += 1 # 새 ID 감지 시 입장으로 간주
current_ids.add(object_id) # 현재 프레임에 감지된 ID 추가
# 경계 상자와 ID 표시
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(frame, f'ID: {object_id}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
# 이전 프레임에서 존재했지만 현재 프레임에 없는 ID의 프레임 수 감소
# 특정 사람이 다른 물체에 가려졌을 때도 계속 같은 사람임을 나타내기 위한 코드
for id in list(detected_ids.keys()):
if id not in current_ids:
prev_x, prev_y, frames = detected_ids[id]
if frames > 0:
detected_ids[id] = (prev_x, prev_y, frames - 1)
else:
del detected_ids[id]
total_out_count += 1 # ID가 사라진 경우 퇴장으로 간주
# 누적 카운트 표시
cv2.putText(frame, f'Total In: {total_in_count}', (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(frame, f'Total Out: {total_out_count}', (50, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# 비디오에 현재 프레임 저장
out.write(frame)
# Colab 환경에서 현재 프레임 표시
#cv2_imshow(frame)
if cv2.waitKey(1) & 0xFF == ord('q'): #키보드 q 를 누르면 멈추게 하는 코드
break
# 모든 작업 완료 후 자원 해제
cap.release()
out.release()
cv2.destroyAllWindows()
문제1. 앞에서 개인적으로 만들었던 영상 또는 지금 다시 만들 영상을 가지고 인원수를 제대로 카운트하는지 확인하기
from google.colab import drive
drive.mount('/content/drive')
!pip install ultralytics
import cv2
from ultralytics import YOLO
import numpy as np
from google.colab.patches import cv2_imshow #코랩에서 이미지를 보여주기 위해 필요
from collections import deque # file 입력과 출력 관련한 자료구조 (사람 카운트)
# YOLOv8 모델 불러오기
model = YOLO('yolov8n.pt') #욜로 나노 버전인데 80개의 클래스를 자동 인식
# 비디오 캡처 초기화
cap = cv2.VideoCapture("/content/drive/MyDrive/yolonew/videoplayback_exported.mp4")
# 비디오 저장 설정
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter("/content/drive/MyDrive/yolonew/videoplayback_exported_output.mp4", fourcc, 30.0,
(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))))
# 카운팅 변수 초기화
total_in_count = 0 # 누적 입장 수
total_out_count = 0 # 누적 퇴장 수
detected_ids = {} #객체 id 와 좌표를 저장할 딕셔너리
next_id = 0 #새로운 객체에 부여할 고유 id
exit_buffer = 30 # ID가 삭제되기 전까지 유지되는 프레임 수
id_buffer = deque(maxlen=50) # 최근 ID 기록용
while cap.isOpened(): #비디오가 열려있는 동안 루프를 반복
ret, frame = cap.read() #프레임을 하나씩 읽어오기 ret은 읽기 성공여부
if not ret: #프레임이 없으면 루프를 중단
break
# 객체 탐지 수행
results = model(frame)
current_ids = set() # 현재 프레임에서 감지된 ID를 저장할 집합
for det in results[0].boxes: #감지된 객체 각각에 대해 반복 처리 하기
x1, y1, x2, y2 = map(int, det.xyxy[0]) # 박스 좌표 <- 도둑 잡아내는 모델에서는 굉장히 중요한 파트
conf = det.conf[0].item() # 박스에 있는 물체가 사람일 확률에 대한 신뢰도
cls = int(det.cls[0].item()) # 클래스
if cls == 0 and conf > 0.5: # 클래스 0은 사람, 이걸 조절하면 사람이라고 카운트 하는 것을 늘릴 수 있음
# 중심 좌표 계산
center_x = int((x1 + x2) / 2)
center_y = int((y1 + y2) / 2)
# ID 생성 및 관리
object_id = None #객체 id를 초기화
#같은 사람이 걸어다녀도 같은 사람임을 확인하는 코드
for id, (prev_x, prev_y, frames) in detected_ids.items():
if abs(prev_x - center_x) < 50 and abs(prev_y - center_y) < 50:
object_id = id
detected_ids[id] = (center_x, center_y, exit_buffer) # 프레임 수 초기화
break
if object_id is None: # 다시 새로운 사람이면
object_id = next_id
detected_ids[object_id] = (center_x, center_y, exit_buffer)
next_id += 1 # 기존 객체 번호에 1을 더해서 객체 번호 부여
total_in_count += 1 # 새 ID 감지 시 입장으로 간주
current_ids.add(object_id) # 현재 프레임에 감지된 ID 추가
# 경계 상자와 ID 표시
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(frame, f'ID: {object_id}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
# 이전 프레임에서 존재했지만 현재 프레임에 없는 ID의 프레임 수 감소
# 특정 사람이 다른 물체에 가려졌을 때도 계속 같은 사람임을 나타내기 위한 코드
for id in list(detected_ids.keys()):
if id not in current_ids:
prev_x, prev_y, frames = detected_ids[id]
if frames > 0:
detected_ids[id] = (prev_x, prev_y, frames - 1)
else:
del detected_ids[id]
total_out_count += 1 # ID가 사라진 경우 퇴장으로 간주
# 누적 카운트 표시
cv2.putText(frame, f'Total In: {total_in_count}', (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(frame, f'Total Out: {total_out_count}', (50, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# 비디오에 현재 프레임 저장
out.write(frame)
# Colab 환경에서 현재 프레임 표시
#cv2_imshow(frame)
if cv2.waitKey(1) & 0xFF == ord('q'): #키보드 q 를 누르면 멈추게 하는 코드
break
# 모든 작업 완료 후 자원 해제
cap.release()
out.release()
cv2.destroyAllWindows()
문제2. 이력서에 추가할 포트폴리오 깃허브 주소를 만들 깃허브를 생성하기
1. 유동인구 카운트 yolo 영상 2. 폐결절 찾는 신경망 만들기
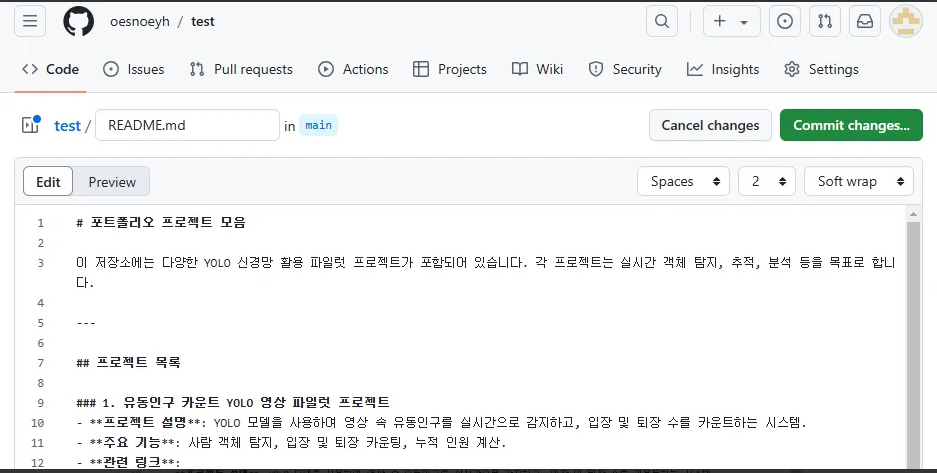
# 포트폴리오 프로젝트 모음
이 저장소에는 다양한 YOLO 신경망 활용 파일럿 프로젝트가 포함되어 있습니다. 각 프로젝트는 실시간 객체 탐지, 추적, 분석 등을 목표로 합니다.
---
## 프로젝트 목록
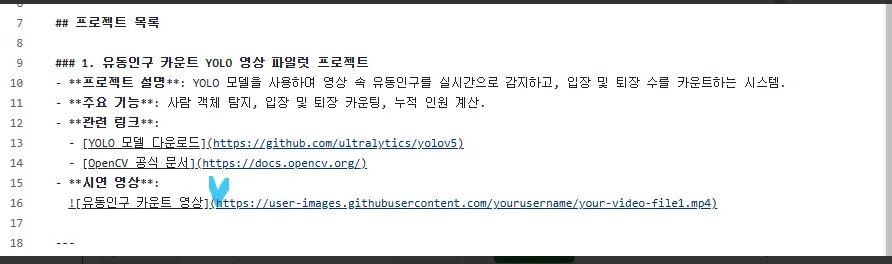
### 1. 유동인구 카운트 YOLO 영상 파일럿 프로젝트
- **프로젝트 설명**: YOLO 모델을 사용하여 영상 속 유동인구를 실시간으로 감지하고, 입장 및 퇴장 수를 카운트하는 시스템.
- **주요 기능**: 사람 객체 탐지, 입장 및 퇴장 카운팅, 누적 인원 계산.
- **관련 링크**:
- [YOLO 모델 다운로드](https://github.com/ultralytics/yolov5)
- [OpenCV 공식 문서](https://docs.opencv.org/)
- **시연 영상**:
[](https://github.com/oracleyu01/pilot/blob/main/sjk_with_counts_vrew_exported.mp4)
---
### 2. 도둑감지 YOLO 신경망 활용 파일럿 프로젝트
- **프로젝트 설명**: 무인 감시 시스템을 위한 도둑 감지 기능. YOLO 모델을 통해 특정 위치에서의 불법 침입자를 실시간으로 탐지.
- **주요 기능**: 실시간 침입자 감지, 위험 알림, 비상 조치 기능.
- **관련 링크**:
- [YOLO 모델 다운로드](https://github.com/ultralytics/yolov5)
- [알림 시스템 API 문서](https://your-api-link.com/)
- **시연 영상**:

---
### 3. 차량 흐름 분석 파일럿 프로젝트
- **프로젝트 설명**: 도로 영상에서 차량 객체를 감지하고, 차량 흐름을 분석하여 교통 밀집도를 예측.
- **주요 기능**: 차량 객체 탐지, 밀집도 분석, 실시간 데이터 시각화.
- **관련 링크**:
- [교통 데이터 API](https://traffic-api.com/)
- **시연 영상**:

---
### 4. 얼굴 인식 출입 시스템 파일럿 프로젝트
- **프로젝트 설명**: YOLO와 얼굴 인식 모델을 이용한 출입 관리 시스템.
- **주요 기능**: 얼굴 인식을 통한 출입 허가, 기록 관리, 출입 로그.
- **관련 링크**:
- [얼굴 인식 모델 다운로드](https://facerecognition-model.com/)
- **시연 영상**:

---
### 5. 안전 헬멧 착용 감지 파일럿 프로젝트
- **프로젝트 설명**: 작업 현장에서 안전 헬멧 착용 여부를 감지하여 안전 규정을 준수하는지 확인.
- **주요 기능**: 헬멧 착용 감지, 안전 경고, 실시간 알림.
- **관련 링크**:
- [헬멧 감지 데이터셋](https://helmet-dataset.com/)
- **시연 영상**:

---
## 설치 및 실행 방법
1. 필요한 라이브러리 설치:
```bash
pip install opencv-python-headless ultralytics numpy
commit 하면 이렇게 나옴
이부분 url을 바꿔주기 파일 업로드하기
영상과 썸네일 둘다 주소 복사하기
썸네일 / 영상 순으로 주사 바꿔주기
결과~
코랩 주소 복사해서 readme 바꿔놓기
언어를 인식하는 신경망 생성 2가지?
직접 수 많은 빅데이터의 텍스트들을 수집해서 언어모델 생성
만들어진 언어 모델을 파인 튜닝 (fine tuning)해서 나만의 언어 모델 생성내가 구현하고 싶은 언어 모델을 위한 좋은 데이터를 생성하는 것이 중요함
리마 같은 LLM 을 파인 튜닝함
내가 던진 질문에 대해서 적절한 답을 할 수 있으려면 신경망이 학습한 질문과 얼마나 유사한지 계산하는 방법을 공부
코사인 유사도
자카드 유사도
언어 챗봇 만들기1. 코싸인 유사도
# 필요한 라이브러리 설치 (Colab이나 Jupyter 환경에서 실행 시 필요)
!pip install -q sentence-transformers
# 라이브러리 임포트
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
# SentenceTransformer 모델 초기화
model = SentenceTransformer('all-MiniLM-L6-v2')
# 단어 'france'와 'french'의 임베딩 생성
embedding_a = model.encode("france").reshape(1, -1)
embedding_b = model.encode("french").reshape(1, -1)
# 코사인 유사도 계산
cosine_sim = cosine_similarity(embedding_a, embedding_b)[0][0]
# 결과 출력
print("Cosine Similarity between 'france' and 'french':", cosine_sim)
실습1. french 와 france 의 유사도를 구하기
# 필요한 라이브러리 설치 (Colab이나 Jupyter 환경에서 실행 시 필요)
#!pip install -q sentence-transformers #문자를 임베딩하는 클래스
# 라이브러리 임포트
import numpy as np #배열을 다루는 수학 라이브러리
from sklearn.metrics.pairwise import cosine_similarity #코사인 유사도
from sentence_transformers import SentenceTransformer #문장을 임배딩
# SentenceTransformer 모델 초기화
model = SentenceTransformer('all-MiniLM-L6-v2') #간결하면서 높은 성능을 보이는 사전에 훈련된 언어 모델
# 단어 'france'와 'french'의 임베딩 생성
#france 를 벡터로 변환하고 reshape로 2차원으로 변환
embedding_a = model.encode("france").reshape(1, -1)
#french 를 벡터로 변환하고 reshape로 2차원으로 변환
embedding_b = model.encode("french").reshape(1, -1)
print( embedding_a)
# 코사인 유사도 계산
cosine_sim = cosine_similarity(embedding_a, embedding_b)[0][0]
# 결과 출력
print("Cosine Similarity between 'france' and 'french':", cosine_sim)
Cosine Similarity between 'france' and 'french': 0.74060774
오늘의 마지막 문제. 다음의 질문을 심리 상담 언어 모델에게 했을 때 적절한 답을 할 수 있도록 a 변수의 문장과 코싸인 유사도가 높은것이 b와 c 중 무엇인지 파이썬 코드로 출력하기
a = '하루 종일 우울해요' b = '남편만 보면 화가 치밀어 오르고 감정 조절이 안돼요' c = '오전에 우울하다 오후가 되면 괜찮아요'
# 필요한 라이브러리 설치 (Colab이나 Jupyter 환경에서 실행 시 필요)
#!pip install -q sentence-transformers #문자를 임베딩하는 클래스
# 라이브러리 임포트
import numpy as np #배열을 다루는 수학 라이브러리
from sklearn.metrics.pairwise import cosine_similarity #코사인 유사도
from sentence_transformers import SentenceTransformer #문장을 임배딩
# SentenceTransformer 모델 초기화
model = SentenceTransformer('all-MiniLM-L6-v2') #간결하면서 높은 성능을 보이는 사전에 훈련된 언어 모델
# 단어 'france'와 'french'의 임베딩 생성
#france 를 벡터로 변환하고 reshape로 2차원으로 변환
embedding_a = model.encode('하루 종일 우울해요').reshape(1, -1)
#french 를 벡터로 변환하고 reshape로 2차원으로 변환
embedding_b = model.encode('남편만 보면 화가 치밀어 오르고 감정 조절이 안돼요').reshape(1, -1)
embedding_c = model.encode('오전에 우울하다 오후가 되면 괜찮아요').reshape(1, -1)
#print( embedding_a)
# 코사인 유사도 계산
cosine_sim = cosine_similarity(embedding_a, embedding_b)[0][0]
cosine_sim2 = cosine_similarity(embedding_a, embedding_c)[0][0]
# 결과 출력
print("a와 b의 유사도", cosine_sim)
print("a와 c의 유사도", cosine_sim2)