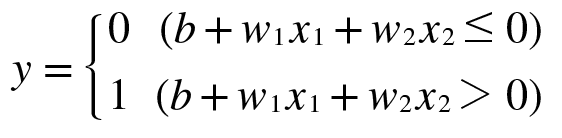[빅데이터분석] 딥러닝_2. Matplotlib를 이용한 시각화 / 퍼셉트론 / 신경망 구현 / 활성화 함수
chonny
2024. 10. 2. 16:46
- 행렬로 변환하는 이유는 고양이사진에서 배경이 되는 검정색 부분은 학습할 필요가 없기 때문에 걸러내기 위함임
■ 사진, 동영상, 음성 -> 신경망 -> 분류
전기차 화재 감지관련 yolo 신경망 구현 -> 영상에서 불길이 봉면 바로 object detection 을 해서 불길이 보인다고 실시간 알람을 보낼 수 있는 기술
■ Matplotlib 으로 그래프 그리기
신경망의 학습 성능을 평가하기 위해 평가 점수를 시각화한 라인 그래프를 작성하려고 합니다.
수백 장의 사진을 신경망에 입력하여 잘 분류되고 있는지 확인하기 위해, 학습이 반복될 때마다 에폭 수가 증가함에 따라 정확도가 점점 올라가는지를 확인하기 위해 라인 그래프를 활용할 예정입니다.
예제 1. 파이썬으로 산포도 그래프 그리기 1. 산포도 그래프 그리기
import numpy as np
import matplotlib.pyplot as plt
x = np.array([0,1,2,3,4,5,6,7,8,9])
y = np.array([9,8,7,9,8,3,2,4,3,4])
plt.scatter(x,y, color = 'red', s=80) # s는 점의 사이즈 점의 사이즈
plt.plot(x,y, color = 'orange')
plt.show()
2. x 축이 epochs 라고 하고 y 축을 accuracy라고 라벨을 붙이시오.
import numpy as np
import matplotlib.pyplot as plt
x = np.array([0,1,2,3,4,5,6,7,8,9])
y = np.array([9,8,7,9,8,3,2,4,3,4])
plt.scatter(x,y, color = 'red', s=80) # 점의
plt.plot(x,y, color = 'orange')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
3. 위의 그래프에 제목을 붙이시오
import numpy as np
import matplotlib.pyplot as plt
x = np.array([0,1,2,3,4,5,6,7,8,9])
y = np.array([9,8,7,9,8,3,2,4,3,4])
plt.scatter(x,y, color = 'red', s=80) # 점의
plt.plot(x,y, color = 'orange')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.title('Accuracy vs Epochs')
plt.show()
지금까지 본것은 신경망의 정확도를 평가하는 시각화 코드였고 그리고 또 하나 더 필요한 시각화 코드가 사진을 팡썬에서 시각화하는 코드임
예제. 이미지 활용하기 1. 시각화 하기 원하는 이미지를 가져옵니다. 2. 사진을 파이썬에서 시각화합니다. (p44)
import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread('c:\\data\\cat.jpg')
plt.imshow(img)
plt.show()
■ 퍼셉트론이란?
- 인간의 뇌세포 하나를 컴퓨터 코드로 흉내낸것 - 1957년에 프랑크 로젠 블라트라는 분이 고안해낸것 - 사람의 뇌의 동작으로 전기 스위치 온/오프를 흉내낼 수 있다는 이론을 증명함
고등학교 생물 시간에 배운 용어 3가지 ?
1. 자극 2. 반응 3. 역치(threshold)
"특정 자극이 있다면 그 자극이 어느 역치 이상이여야 세포가 반응한다"
어떤 사물이 뇌에서 기억이되고 인식이 되려면 어느 역치 이상의 자극이 들어와야합니다.
수지 사진에서 배경에 해당하는 부분은 픽셀값이 0 이 될것이고 수진 얼굴에 해당하는 부분의 픽셀값을 어떤 큰 숫자값일 텐데 이 값들이 가중치와 곱해져서 곱한 그 값이 임계치 이상이면 신호가 가고 임계치보다 작으면 신호가 안가겠금 계산되고 점점 수지 사진을 반복 학습해가면서 수지 사진에서 중요한 부분이 어딘지 가중치가 점점 갱신되는 원리입니다.
신경망이 학습 될때 처음에 가중치는 랜덤으로 정해집니다. 점점 학습이 되면서 가중치가 변경이 됩니다. 사진의 특정 부분이 수지의 특징을 나타내는 중요한 부분이면 신호를 보내고 중요하지 않으면 신호를 안보내겠다는것입니다.
처음에는 중요한지 안중요한지 모르니까 가중치가 랜덤값이었다가 점점 수지사진과 설현사진을 수백장 학습하면서 사진의 중요한 부분이 어딘지 알게되면서 가중치가 스스로 변경이 됩니다.
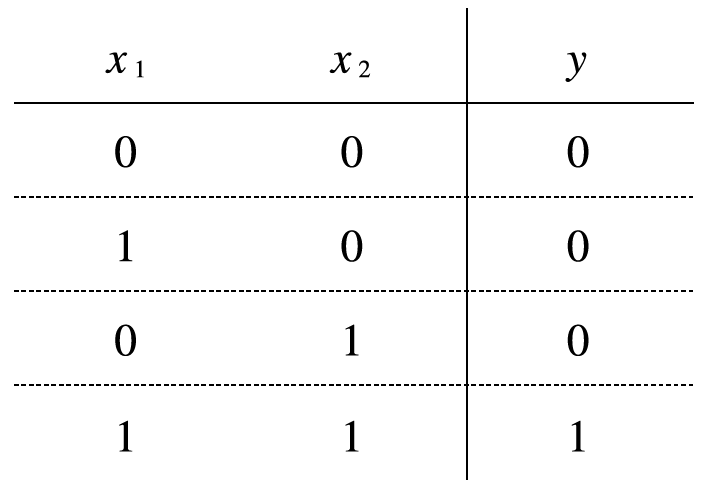
지금 부터 작성할 코드는 AND 게이트 데이터와 정답에 대해서 가중치와 세타(임계치)를 신경망이 직접 알아내게 학습 시키는 코드입니다.
#1. 필요한 모듈을 임폴트 합니다.
import tensorflow as tf
tf.random.set_seed(777) # 시드를 설정합니다.
import numpy as np
from tensorflow.keras.models import Sequential # 신경망 모델 구성
from tensorflow.keras.layers import Dense # 완전 연결계층
from tensorflow.keras.optimizers import SGD # 경사하강법
from tensorflow.keras.losses import mse # 오차함수
#2. 데이터를 준비합니다.
x = np.array( [ [ 0, 0 ], [ 1, 0 ], [ 0, 1 ], [ 1, 1 ] ] )
y = np.array( [ [0], [0], [0], [1] ] )
#3. 모델을 구성합니다. ( 이 모델이 가중치(w) 와 theta 를 스스로 알아낼겁니다.)
model = Sequential()
#4. 단층 퍼셉트론 모델 설계하기 ( 그림2-1을 보면 인공 뉴런 세포가 1개입니다.)
model.add( Dense( 1, input_shape=( 2, ), activation='linear') )
model.compile( optimizer= SGD(), # 경사하강법을 지정(오차를 최소화하는 방법)
loss = mse, # 오차함수
metrics=['acc'] ) # 정확도가 높아지는 쪽으로 학습을 시킴
#5. 모델 훈련하기
model.fit( x, y, epochs=500) # fit(입력 데이터, 정답, 학습 횟수)
#6. 모델 예측값 출력하기
import numpy as np
result = model.predict(x)
print(np.round(result))
#7. 가중치값 출력하기
print(model.get_weights())
관련 문제] 이번에는 or 게이트 데이터를 학습하는 신경망을 텐써 플로우로 구현하고 예측값과 가중치를 출력하시오 !
import tensorflow as tf
import numpy as np
# 시드 설정
tf.random.set_seed(777) # TensorFlow 시드 설정
np.random.seed(777) # NumPy 시드 설정
from tensorflow.keras.models import Sequential # 신경망 모델 구성
from tensorflow.keras.layers import Dense # 완전 연결 계층
from tensorflow.keras.optimizers import SGD # 경사 하강법
from tensorflow.keras.losses import mse # 오차함수
# 데이터 준비
x = np.array([[0, 0], [1, 0], [0, 1], [1, 1]])
y = np.array([[0], [0], [0], [1]])
# 모델을 구성
model = Sequential()
# 단층 퍼셉트론 모델 설계
model.add(Dense(1, input_shape=(2,), activation='linear'))
model.compile(optimizer=SGD(), # 경사 하강법을 지정 (오차를 최소화하는 방법)
loss=mse, # 오차함수
metrics=['acc']) # 정확도가 높아지는 쪽으로 학습을 시킴
# 모델 훈련
model.fit(x, y, epochs=500) # fit(입력 데이터, 정답, 학습 횟수)
# 결과 출력
result = model.predict(x)
print(np.round(result))
# 가중치값 출력
print(model.get_weights())
관련 문제] 이번에는 not and 게이트 데이터를 학습하는 신경망을 텐써 플로우로 구현하고 예측값과 가중치를 출력하시오 !
# 필요한 모듈을 임포트합니다.
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.losses import mse
# 시드를 설정합니다.
tf.random.set_seed(777)
# NAND 게이트 데이터를 준비합니다.
# NAND 진리표: 입력 (A, B) -> 출력 (NAND)
x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[1], [1], [1], [0]]) # NAND의 출력
# 모델을 구성합니다.
model = Sequential()
# 단층 퍼셉트론 모델 설계하기
model.add(Dense(1, input_shape=(2,), activation='sigmoid')) # sigmoid 활성화 함수 사용
# 모델 컴파일
model.compile(optimizer=SGD(), loss=mse, metrics=['acc'])
# 모델 훈련하기
model.fit(x, y, epochs=500)
# 모델 예측값 출력하기
result = model.predict(x)
print(np.round(result))
# 가중치값 출력하기
print(model.get_weights())
* 단순 논리 회로 4가지
1. AND 게이트 (그림 2-2) 2. OR 게이트 (그림 2-4) 3. NAND 게이트 (그림 2-3) ---------------------------------------------------- 4. XOR 게이트 (그림 2-5)
퍼셉트론 역사설명 : 1. 1957년 로젠 블래트 단층 퍼셉트론 2. 1969년 민스키라는 분이 퍼셉트론의 문제점을 발견함 로젠블래트가 제안한 단층 퍼셉트론은 AND, OR, NAND는 분류할 수 있지만 XOR 게이트는 분류를 못한다는 문제점을 지적
▣ XOR 게이트
1957년 ----------------> 1969년 ---------------> 1979년 ----------> 1990년 ↓ ↓ ↓ ↓ 단층 퍼셉트론 XOR 게이트 문제점 제기 다층 퍼셉트론으로 딥러닝 XOR 게이터 문제 해결
XOR 게이트 ? eXclusive OR 게이트 입니다. ↓ 배타적(자기외에는 다 거부한다는 뜻)
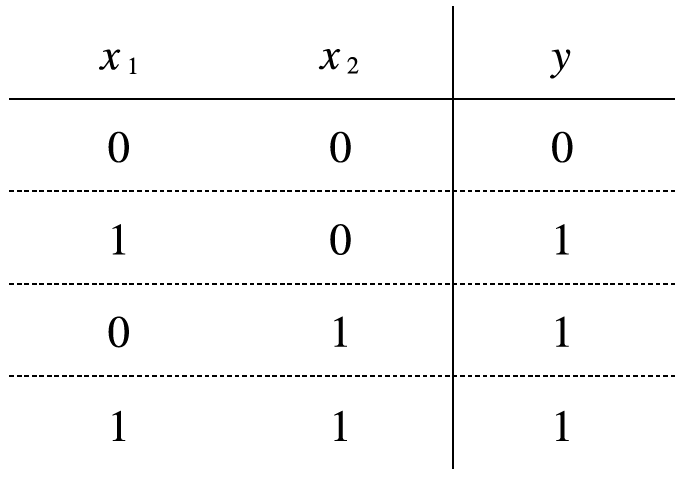
예제1. AND 게이트 데이터 학습 시켰던 텐써 플로우 신경망 코드로 XOR 게이트 데이터를 학습 시키시오 !
# 답:
#1. 필요한 모듈을 임폴트 합니다.
import tensorflow as tf
tf.random.set_seed(777) # 시드를 설정합니다.
import numpy as np
from tensorflow.keras.models import Sequential # 신경망 모델 구성
from tensorflow.keras.layers import Dense # 완전 연결계층
from tensorflow.keras.optimizers import SGD # 경사하강법
from tensorflow.keras.losses import mse # 오차함수
#2. 데이터를 준비합니다.
x = np.array( [ [ 0, 0 ], [ 1, 0 ], [ 0, 1 ], [ 1, 1 ] ] )
y = np.array( [ [0], [1], [1], [0] ] )
#3. 모델을 구성합니다. ( 이 모델이 가중치(w) 와 theta 를 스스로 알아낼겁니다.)
model = Sequential()
#4. 단층 퍼셉트론 모델 설계하기 ( 그림2-1을 보면 인공 뉴런 세포가 1개입니다.)
model.add( Dense( 1, input_shape=( 2, ), activation='linear') )
model.compile( optimizer= SGD(), # 경사하강법을 지정(오차를 최소화하는 방법)
loss = mse, # 오차함수
metrics=['acc'] ) # 정확도가 높아지는 쪽으로 학습을 시킴
#5. 모델 훈련하기
model.fit( x, y, epochs=500) # fit(입력 데이터, 정답, 학습 횟수)
XOR 게이트 데이터는 단층으로는 분류할 수 없고 다층으로만 분류할 수 있습니다. 입력층과 출력층 사이에 은닉층이 중간에 하나 더 있어야 합니다.
예제2. 텐써 플로우로 XOR 게이트 데이터를 분류하는 신경망을 만드시오
#1. 필요한 모듈을 임폴트 합니다.
import tensorflow as tf
tf.random.set_seed(777) # 시드를 설정합니다.
import numpy as np
from tensorflow.keras.models import Sequential # 신경망 모델 구성
from tensorflow.keras.layers import Dense # 완전 연결계층
from tensorflow.keras.optimizers import SGD # 경사하강법
from tensorflow.keras.losses import mse # 오차함수
#2. 데이터를 준비합니다.
x = np.array( [ [ 0, 0 ], [ 1, 0 ], [ 0, 1 ], [ 1, 1 ] ] )
y = np.array( [ [0], [1], [1], [0] ] )
#3. 모델을 구성합니다. ( 이 모델이 가중치(w) 와 theta 를 스스로 알아낼겁니다.)
model = Sequential()
#4. 단층 퍼셉트론 모델 설계하기 ( 그림2-1을 보면 인공 뉴런 세포가 1개입니다.)
model.add( Dense( 2, input_shape=( 2, ), activation='sigmoid') ) # 은닉층(1층)
model.add( Dense( 1, activation='sigmoid') ) # 출력층(2층)
# 설명: 다층으로 구현하게 되면 활성화 함수를 계단 함수를 쓰면 안되고 # sigmoid 함수나 relu 함수를 사용해야합니다. # 계단함수는 0 아니면 1로 출력하는 함수 # 시그모이드 함수는 0~1사이의 숫자값을 출력하는 함수 # 내일날씨를 예측하는 방송에서도 비올 확률이 70%다라고 하지 절대로 비온다 안온다 # 로 방송하지 않습니다.
model.compile( optimizer= SGD(), # 경사하강법을 지정(오차를 최소화하는 방법)
loss = mse, # 오차함수
metrics=['acc'] ) # 정확도가 높아지는 쪽으로 학습을 시킴
#5. 모델 훈련하기
model.fit( x, y, epochs=500) # fit(입력 데이터, 정답, 학습 횟수)
아직 0.75로 정확도가 나오고 있어서 뉴런수와 층수와 에폭수를 다음과 같이 늘립니다.
#1. 필요한 모듈을 임폴트 합니다.
import tensorflow as tf
tf.random.set_seed(777) # 시드를 설정합니다.
import numpy as np
from tensorflow.keras.models import Sequential # 신경망 모델 구성
from tensorflow.keras.layers import Dense # 완전 연결계층
from tensorflow.keras.optimizers import SGD, Adam # 경사하강법
from tensorflow.keras.losses import mse # 오차함수
#2. 데이터를 준비합니다.
x = np.array( [ [ 0, 0 ], [ 1, 0 ], [ 0, 1 ], [ 1, 1 ] ] )
y = np.array( [ [0], [1], [1], [0] ] )
#3. 모델을 구성합니다. ( 이 모델이 가중치(w) 와 theta 를 스스로 알아낼겁니다.)
model = Sequential()
#4. 다층 퍼셉트론 모델 설계하기 ( 그림2-1을 보면 인공 뉴런 세포가 1개입니다.)
model.add( Dense( 4, input_shape=( 2, ), activation='relu') ) # 은닉층(1층)
model.add( Dense( 4, activation='relu') ) # 은닉층(2층)
model.add( Dense( 1, activation='sigmoid') ) # 출력층(3층)
# 설명: 다층으로 구현하게 되면 활성화 함수를 계단 함수를 쓰면 안되고
# sigmoid 함수나 relu 함수를 사용해야합니다.
# 계단함수는 0 아니면 1로 출력하는 함수
# 시그모이드 함수는 0~1사이의 숫자값을 출력하는 함수
# 내일날씨를 예측하는 방송에서도 비올 확률이 70%다라고 하지 절대로 비온다 안온다
# 로 방송하지 않습니다.
model.compile( optimizer= Adam(), # 경사하강법을 지정(오차를 최소화하는 방법)
loss = mse, # 오차함수
metrics=['acc'] ) # 정확도가 높아지는 쪽으로 학습을 시킴
#5. 모델 훈련하기
model.fit( x, y, epochs=1000) # fit(입력 데이터, 정답, 학습 횟수)
▣ 3층 신경망 구현하기 (저자가 만들어온 가중치로)
"6만개의 필기체 데이터를 가지고 신경망을 생성" ↓ 얀루쿤 교수님 팀이 만든 데이터 입니다. 손으로 일일히 쓴 필기체 데이터 입니다.
구글에서 "mnist 필기체 데이터" 라고 검색해보세요.
이 데이터로 3장에서 신경망을 생성합니다. 생성하고 나서 여러분들이 직접 손으로 쓴 필기체를 여러분들이 만든 신경망이 잘 맞추는지 확인해 보겠습니다.
1. mnist 의 숫자8
설명: 가로 28 x 세로 28 = 768 개의 픽셀로 이루어져 있고 하나의 픽셀은 0~255 사이의 숫자로 구성되어 있는데 0에 가까울수록 하얀색이고 255에 가까울 수록 검정색으로 보입니다.
2. mnist 숫자 8을 어떻게 신경망이 인식하는지
설명: 3층 신경망에 필기체 숫자가 입력이 되는데 그림에서는 숫자 8일 입력되고 있습니다. 이 숫자 8은 28x28개의 768개의 픽셀로 이루져 있습니다. 이 768개의 픽셀이 입력층에 들어갑니다. 그리고 은닉층으로 숫자값이 들어갈때는 입력값과 가중치의 곱의 합이 계산되서 은닉층으로 들어갑니다. 은닉층에는 시그모이드나 렐루가 같은 활성화 함수가 있어서 입력값과 가중치의 곱의 합을 받아서 0~1사이의 숫자를 출력해줍니다. 그리고 이 숫자가 다시 출력층으로 입력되는데 이때도 가중치와 곱해지고 출력층으로 들어갑니다. 그리고 출력층에서는 입력된 필기체가 숫자 8인지 7인지를 결론을 내줍니다.
왜? 딥러닝 신경망에서는 행렬계산이 일어나기 때문에 행렬계산을 하기 쉽도록 반드시 numpy 로 코딩해야 합니다.
그래서 다음과 같이 코딩해야합니다.
import numpy as np
def step_funcion(x):
y = x > 0 # 입력값 x 가 0 보다 크면 y 에 true 가 들어가고 아니면 false
return y.astype(np.int32) # true 를 np.int32 로 변환하면 숫자 1이 출력되고
# false 를 np.int32 로 변환하면 숫자 0 이 출력됩니다.
x_data = np.array([ -23, 0, 72 ] )
print ( step_function(x_data) )
신경망에 들어가는 함수를 생성할 때는 무조건 넘파이 배열을 처리할 수 있도록 생성을 해줘야합니다. 계단함수는 단층 신경망에서만 쓸 수 있고 다층 신경망에서는 쓸 수 없습니다. 다층 신경망에서는 다른 활성화 함수를 써야합니다. 책(원리를 이해하는 단단한 뼈대) <--- 신기술(살)
이 그림에서 하늘 사진의 픽셀의 경우는 "개와 고양이를 분류하는 신경망" 에서 별로 중요하지 않는 부분입니다. 그래서 처음에는 잘 모르기 때문에 신호를 보낼 수도있고 안보낼 수 도 있는데 나중에 이 픽셀이 개와 고양이를 분류하는데 있어서 별로 중요하지 않은 부분이라는것을 알게 되고 신호를 보내지 않게 됩니다. 그래서 계단함수는 신호를 보낼거냐 아니면 안보낼거냐를 결정하는 극단적인 함수 입니다.
▣ 활성화 함수 시그모이드 함수
" 입력값을 받아서 0 에서 1 사이의 실수를 출력하는 함수 "
신경망에서는 입력값과 가중치의 곱의 합(예: x1*w1+x2*w2) 를 받아서 0 에서 1사이의 실수를 출력하는 역활을 합니다. 계단함수는 신호를 보내거나 보내지 않거나인데 시그모이드 함수는 신호를 강하게 보내거나 약하게 보내거나 입니다.
수지와 은우 사진을 학습하는 신경망이라고 하면 0 에 가까운면 수지이고 1에 가까우면 은우라고 은닉층의 활성화 함수들이 출력을 하는 구조입니다. 이 그림에서 은닉층의 첫번째 뉴런의 시그모이드 함수는 0.1 을 출력하고 있기 때문에 수지로 판단하고 있는것이고 두번째 뉴런과 세번째 뉴런은 은우로 판단하고 있는것입니다.
예제2. 위의 시그모이드 함수를 그림 3-7 처럼 시각화 하시오 !
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / ( 1 + np.exp(-x))
x = np.arange( -6, 6, 0.1 ) # -6에서 6까지 0.1 간격으로 실수를 출력
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()