#크롬 로봇
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
#크롬 설치 자동화
from webdriver_manager.chrome import ChromeDriverManager
# html 에서 데이터 수집을 편하게
from bs4 import BeautifulSoup
import time # 부하주지 않도록 예의를 지키는 모듈
3. 크롬 로봇을 지정합니다.
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
8. song_elements 코드에서 노래 제목들만 리스트에 result라는 list에 담아내시오.
result = []
for i in song_elements:
result.append(i.text)
print(result)
9. 크롬 로봇이 웹브라우져를 닫게 하시오.
driver.quit()
10. 위 코드를 get_song_lists('노래제목들' ) 함수로 생성하시오.
# 질문: 뉴진스 노래 조회수 순위 데이터 수집과 시각화
def get_song_lists(keyword):
#크롬 로봇
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
#크롬 설치 자동화
from webdriver_manager.chrome import ChromeDriverManager
# html 에서 데이터 수집을 편하게
from bs4 import BeautifulSoup
import time # 부하주지 않도록 예의를 지키는 모듈
#3. 크롬 로봇을 지정합니다.
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
#4. 뉴진스 노래 제목들을 출력하는데 웹페이지를 크롬로봇이 열수 있게 합니다.
driver.get(f"https://www.google.com/search?q={keyword}&oq=&gs_lcrp=EgZjaHJvbWUqCQgBEEUYOxjCAzIJCAAQRRg7GMIDMgkIARBFGDsYwgMyCQgCEEUYOxjCAzIJCAMQRRg7GMIDMgkIBBBFGDsYwgMyCQgFEEUYOxjCAzIJCAYQRRg7GMIDMgkIBxBFGDsYwgPSAQkxMzcwajBqMTWoAgiwAgE&sourceid=chrome&ie=UTF-8&clie=1")
#5. 페이지가 로드되는 시간을 줍니다.
time.sleep(3)
#6. 웹페이지의 html 코드를 뷰티플 수프로 파싱합니다.
html = driver.page_source
soup = BeautifulSoup( html, "html.parser" )
#7. html 코드에서 노래제목들이 있는 곳의 테그와 클래스로 접근합니다.
song_elements = soup.select('div.junCMe > div.CYJS5e.title')
#8. song_elements html 코드에서 노래제목들만 출력하시오 !
result = [ ]
for i in song_elements:
result.append( i.text )
#9. 크롬 로봇이 웹브라우져를 닫게 합니다.
driver.quit()
return result
실습2. 유튜브에서 뉴진스의 노래 모음 list 함수 생성하기 1. 필요한 패키지 불러오기
#크롬 로봇
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
#크롬 설치 자동화
from webdriver_manager.chrome import ChromeDriverManager
# html 에서 데이터 수집을 편하게
from bs4 import BeautifulSoup
import time # 부하주지 않도록 예의를 지키는 모듈
import pandas as pd # 데이터 분석용
import matplotlib.pyplot as plt # 데이터 시각화용
2. 노래제목들을 불러오기
songs = get_song_lists('뉴진스 노래 제목들')
print(songs)
3. 크롬 로봇을 지정합니다.
service = Service(ChromeDriverManager().install())
driver =webdriver.Chrome(service=service)
4. 각 노래에 대한 유튜브 링크추출
for i in songs:
search_query =f'뉴진스 {i}'
print(search_query)
● 가수명과 노래 사이에 '+' 기입 print(search_url)
for i in songs:
search_query =f'뉴진스 {i}'
search_url =f'https://www.youtube.com/results?search_query={search_query.replace(' ','+')}' # 가수명과 노래 사이에 '+' 기입
print(search_url)
● 구글에서 먼저 seach 하고 유튜브로 넘기게끔 하시오.
for i in songs:
search_query =f'뉴진스 {i}'
search_url =f'https://www.youtube.com/results?search_query={search_query.replace(' ','+')}' # 가수명과 노래 사이에 '+' 기입
driver.get(search_url)
time.sleep(3)
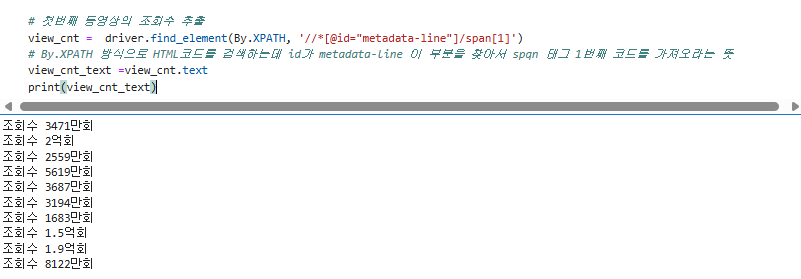
5. 첫번째 동영상의 조회수 추출
# 첫번째 동영상의 조회수 추출
view_cnt = driver.find_element(By.XPATH, '//*[@id="metadata-line"]/span[1]')
# By.XPATH 방식으로 HTML코드를 검색하는데 id가 metadata-line 이 부분을 찾아서 spqn 태그 1번째 코드를 가져오라는 뜻
view_cnt_text =view_cnt.text
print(view_cnt_text)view_cnt = driver.find_element(By.XPATH, '//*[@id="metadata-line"]/span[1]')
-> By.XPATH 방식으로 HTML코드를 검색하는데 id가 metadata-line 이 부분을 찾아서 spqn 태그 1번째 코드를 가져오라는 뜻
● 조회수를 정수형으로 변환
# 조회수를 정수형으로 변환
if '억' in view_cnt_text:
view_count = float(view_cnt_text.replace('조회수','').replace('억','').replace('회','')) * 100000000
elif '만' in view_cnt_text:
view_count = float(view_cnt_text.replace('조회수','').replace('만','').replace('회','')) * 10000
else:
view_count = float(view_cnt_text.replace('조회수','').replace('회','').replace(',',''))
view_count = int(view_count)
print(view_count)
6. 조회수 담는 리스트만들기
view_counts # 3뒤에
view_count = int(view_count) #5 뒤에
view_counts.append(view_count)
df.to_csv("c:\\data\\ns_song.csv", index = False, encoding ="utf-8-sig")
문제1. 위의 코드를 함수로 생성하는데 실행하면 해당 가수의 노래와 조회수가 csv 파일로 저장되게하시오.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import time
import pandas as pd
import matplotlib.pyplot as plt
def get_song_lists(search_query):
# Set up the Chrome driver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# Open the Google search page with the specified query
search_url = f"https://www.google.com/search?q={search_query}"
driver.get(search_url)
# Wait for the page to load
time.sleep(3)
# Parse the page source with BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
# Select elements that contain the song titles
song_elements = soup.select('div.junCMe > div.CYJS5e.title')
# Extract the song titles
result = [i.text for i in song_elements]
# Close the browser
driver.quit()
return result
def song_view_cnt(artist_name):
# 2. 노래 제목들을 불러옵니다.
songs = get_song_lists(f"{artist_name} 노래 제목들")
# 3. 크롬 로봇을 지정합니다.
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 조회수 담는 리스트
view_counts = []
# 4. 각 노래에 대해서 유튜브 조회수 추출
for song in songs:
search_query = f"{artist_name} {song}"
search_url = f"https://www.youtube.com/results?search_query={search_query.replace(' ','+') }"
driver.get(search_url)
time.sleep(2)
try:
# 첫번째 동영상의 조회수 추출
view_cnt = driver.find_element(By.XPATH, '//*[@id="metadata-line"]/span[1]')
view_cnt_text = view_cnt.text
# 조회수를 정수형으로 변환
if '억' in view_cnt_text:
view_count = float(view_cnt_text.replace('조회수', '').replace('억', '').replace('회','')) * 100000000
elif '만' in view_cnt_text:
view_count = float(view_cnt_text.replace('조회수', '').replace('만', '').replace('회','')) * 10000
else:
view_count = float(view_cnt_text.replace('조회수', '').replace('회','').replace(',',''))
view_count = int(view_count)
except Exception as e:
print(f"조회수를 가져오는 중 오류 발생: {e}")
view_count = 0 # 조회수를 가져오지 못한 경우 0으로 처리
view_counts.append(view_count)
# 웹드라이버 종료
driver.quit()
# 데이터 프레임 생성
df = pd.DataFrame({
'노래제목': songs,
'조회수': view_counts
})
# 데이터 프레임을 csv 파일로 저장
df.to_csv(f"c:\\data\\{artist_name}_song_views.csv", index=False, encoding="utf-8-sig")
print(f"{artist_name}의 노래와 조회수가 {artist_name}_song_views.csv 파일로 저장되었습니다.")
★ 위 코드를 사용하여 시각화 하기 1. 뉴진스_song_views.csv 로 판다스 데이터 프레임을 생성하시오 ,
import pandas as pd
ns = pd.read_csv('c:\\data\\뉴진스_song_views.csv')
ns
2. 조회수가 높은 것 부터 노래제목과 조회수를 출력하시오.
from pandasql import sqldf
pysqldf = lambda q : sqldf(q,globals())
q = """ select *
from ns
order by 조회수 desc; """
pysqldf(q)