# 아티스트와 곡 리스트
artist = ['아이유', '마이클잭슨', '비틀즈', '뉴진스']
music = ['좋은날', 'beat it', 'imagine', 'how sweet']
# zip 함수를 사용해 아티스트와 곡을 매칭하는 딕셔너리 생성
c = {a: m for a, m in zip(artist, music)}
print(c)
복습문제 11. 다음의 리스트를 가지고 아래의 결과가 출력되게하시
# 리스트 정의
aritist = ['아이유','마이클 잭슨','비틀즈','뉴진스']
music = ['좋은날','beat it','imagine','how sweet']
# 가수와 노래 리스트 확장
aritist = aritist *2
music = ['좋은날','잔소리','beat it','Billie Jean','imagine','Hey Jude','how sweet','Ditto']
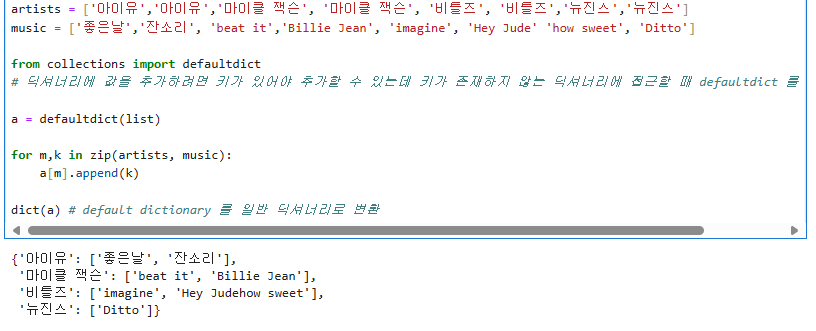
artists = ['아이유','아이유','마이클 잭슨', '마이클 잭슨', '비틀즈', '비틀즈','뉴진스','뉴진스']
music = ['좋은날','잔소리', 'beat it','Billie Jean', 'imagine', 'Hey Jude' 'how sweet', 'Ditto']
from collections import defaultdict
# 딕셔너리에 값을 추가하려면 키가 있어야 추가할 수 있는데 키가 존재하지 않는 딕셔너리에 접근할 때 defaultdict 를 사용하면 됨.
a = defaultdict(list)
for m,k in zip(artists, music):
a[m].append(k)
dict(a) # default dictionary 를 일반 딕셔너리로 변환
# 저자와 도서 리스트
authors = ['조정래', '조정래', '김훈', '김훈', '이문열', '이문열', '신경숙', '신경숙']
books = ['태백산맥', '한강', '칼의 노래', '남한산성', '우리들의 일그러진 영웅', '변경', '엄마를 부탁해', '리진']
from collections import defaultdict
# 딕셔너리에 값을 추가하려면 키가 있어야 추가할 수 있는데 키가 존재하지 않는 딕셔너리에 접근할 때 defaultdict 를 사용하면 됨.
a = defaultdict(list)
for m,k in zip(authors, books):
a[m].append(k)
dict(a) # default dictionary 를 일반 딕셔너리로 변환
복습문제 12. 내장 모듈을 이용해서 입력한 파일이 음악 파일이 맞는지 확인하는 코드를 작성하시오.
#1. 음악 파일이 있는 위치를 지정
file_path = 'C:\\music\\how_sweet.mp3'
#2. 음악 확장자 리스트를 만드시오.
audio_extend =['.mp3','.wav','.flac','.aac','.ogg','.wma','.m4a']
#3. file_path 문자열에서 노래 제목부분만 가져오기
import os
file_path = 'C:\\music\\how_sweet.mp3'
os.path.splitext(file_path) # ('C:\\music\\how_sweet', '.mp3')
result= os.path.splitext(file_path)[1].lower() # .mp3
print(result)
#4. file_path 의 음악의 확장자가 아래의 리스트의 요소중에 속해있는지 확인하시오.
audio_extend = ['.mp3','.wav','.flac','.aac','.ogg','.wma','.m4a']
audio_extend.count(result) # 1
#5. is_audio_file 이라는 함수를 만들고 다음과 같이 수행했을 때 음악 파일이 맞으면 '음악파일이 맞습니다' 가 출력되게 하시오.
def is_audio_file(x):
result = os.path.splitext(file_path)[1].lower()
audio_extend = [ '.mp3', '.wav', '.flac', '.aac', '.ogg', '.wma', '.m4a' ]
cnt = audio_extend.count(result)
if cnt > 0 :
print("음악 파일이 맞습니다")
else:
print("음악 파일이 아닙니다")
is_audio_file(file_path)
복습 문제13. 다음 리스트에서 모든 홀수번째 단어를 대문자로 바꿔서 리스트로 출력하시오 ! a = ['apple', 'banana', 'cherry', 'date', 'fig', 'grape', 'jackfruit']
a = ['apple', 'banana', 'cherry', 'date', 'fig', 'grape', 'jackfruit']
result =[]
for i, w in enumerate(a):
if i % 2 == 0:
result.append(w.upper())
else:
result.append(w)
print(result)
복습 문제14. 다음의 리스트에서 3의 배수인 단어를 대문자로 출력하시오.
a = ['apple', 'banana', 'cherry', 'date', 'fig', 'grape', 'jackfruit']
result=[] # 변환된 결과를 저장할 새로운 리스트
for i, w in enumerate(a):
if (i+1) % 3 == 0 : # 3의 배수인 경우
result.append(w.upper()) # 단어를 대문자로 변환하여 추가
else:
result.append(w) # 원래 단어를 그대로 추가
print(result) # 변환된 결과 리스트를 출력
from collections import Counter
char_list = ['a', 'b', 'c', 'a', 'b', 'd', 'e', 'f', 'e']
result = Counter(char_list)
result2 = dict(result)
result3 = []
for key, value in result2.items():
if value == 2:
result3.append(key)
print(result3)
복습문제 20. 다음 코드의 실행 결과를 예측하고, 그 이유를 설명하세요.
복습문제21. 그럼 다음의 코드의 total 값이 누적되서 출력되게 하려면 어떻게 해야하는가?
total = 0
def add_to_total(value):
global total # 지역 변수 total 선언
total += value
add_to_total(5)
add_to_total(10)
add_to_total(3)
print(total)
복습문제 22. 다음 코드의 실행 결과를 예측하고, 발생 가능한 예외와 그 이유를 설명하세요. 또한, 해당 예외를 처리하는 코드를 추가하여 안전하게 실행되도록 수정하세요.
def divide(x, y):
result = x / y
return result
num1 = 10
num2 = 0 # 0으로 나누는 경우
quotient = divide(num1, num2)
print("몫:", quotient)
답)
def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
return "0으로 나눌 수 없습니다."
return result
num1 = 10
num2 = 0 # 0으로 나누는 경우
quotient = divide(num1, num2)
print("몫:", quotient)
▣ 복습문제23. 다음 코드의 실행 결과를 예측하고, 발생 가능한 예외와 그 이유를 설명하세요. 또한, 해당 예외를 처리하는 코드를 추가하여 안전하게 실행되도록 수정하세요.
def divide(x, y):
result = x / y
return result
num1 = 10
num2 = 0 # 0으로 나누는 경우
quotient = divide(num1, num2)
print("몫:", quotient)
답)
num1 = 10
num2 = 0 # 0으로 나누는 경우
def divide(x, y):
try:
result = x / y
return result
except ZeroDivisionError:
return '0으로 나눌 수 없습니다.'
print (divide(10,0))
▣ 복습문제24. 다음 코드의 실행 결과를 예측하고, 문제점을 설명하세요. 또한, finally 블록을 사용하여 파일을 안전하게 닫도록 코드를 수정하세요.
def read_file(filename):
f = None
try:
# 파일을 열 때 인코딩을 명시적으로 지정
f = open(filename, 'r', encoding='utf-8')
contents = f.read()
print(contents)
except FileNotFoundError:
print('해당 파일이 없습니다.')
finally: # 예외처리가 발생했던 안했던 간에 무조건 실행
if f:
f.close()
filename = 'c:\\data\\jobs.txt'
read_file(filename)
복습문제 24_2. 위의 함수를 수정해서 다음과 같이 함수를 실행하면 file 이름을 물어보게해서 파일을 열 수 있도록 하시오!
base_path = 'c:\\data\\'
filename = input('보고 싶은 파일명을 입력하세요 ~ ')
full_path = base_path + filename
try:
f = open(full_path, 'r', encoding='utf-8')
contents = f.read()
print(contents)
except FileNotFoundError:
print('해당 파일이 없습니다')
finally: # 예외처리가 발생했던 안했던간에 무조건 실행
if 'f' in locals() and f: # f 가 정의되어 있고 열려있는 경우에만 닫기
f.close()
read_file()