빅데이터 분석(with 아이티윌)/deep learning
[빅데이터분석] 딥러닝_19. 자연어 처리 신경망 만들어서 챗봇 만들기
chonny
2024. 10. 30. 10:41
04. 자연어 처리를 활용한 심리상담 챗봇 만들기의 사본
Colab notebook
colab.research.google.com
!pip install -q sentence-transformersimport pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similaritySentenceBERT를 이용한 문장 인코딩
https://huggingface.co/jhgan/ko-sroberta-multitask
jhgan/ko-sroberta-multitask · Hugging Face
ko-sroberta-multitask This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. Usage (Sentence-Transformers) Using this model becomes easy wh
huggingface.co
encoder = SentenceTransformer('jhgan/ko-sroberta-multitask')
sentences = ["안녕하세요?", "한국어 문장 임베딩을 위한 버트 모델입니다."]
embeddings = encoder.encode(sentences)
print(embeddings)

데이터셋 로드
df = pd.read_csv('https://github.com/kairess/mental-health-chatbot/raw/master/wellness_dataset_original.csv')
df.head()
데이터 전처리
- 필요없는 칼럼 제거
- 챗봇 내용 없는 행 제거
df = df.drop(columns=['Unnamed: 3'])
df.head()
print(len(df))
df = df.dropna()
print(len(df))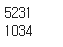
챗봇의 원리
df.loc[0, '유저']
encoder.encode(df.loc[0, '유저'])
모든 데이터셋 인코딩
df['embedding'] = pd.Series([[]] * len(df)) # dummy
df['embedding'] = df['유저'].map(lambda x: list(encoder.encode(x)))
df.head()
예제 문장 입력
text = '요즘 남편이 비트코인도 하고 속을 너무 썩이네'
embedding = encoder.encode(text)
embedding
text = '요즘 남편이 비트코인도 하고 속을 너무 썩이네'
embedding = encoder.encode(text)
embedding
입력된 문장에 대해 유사도 계산
df['similarity'] = df['embedding'].map(lambda x: cosine_similarity([embedding], [x]).squeeze())
df.head()
유사도가 가장 높은 답변을 채택
answer = df.loc[df['similarity'].idxmax()]
print('구분', answer['구분'])
print('유사한 질문', answer['유저'])
print('챗봇 답변', answer['챗봇'])
print('유사도', answer['similarity'])
answer
심리상담 챗봇 앱
!pip install -q gradioimport gradio as gr
def greet(user):
embedding = encoder.encode(user)
df['distance'] = df['embedding'].map(lambda x: cosine_similarity([embedding], [x]).squeeze())
answer = df.loc[df['distance'].idxmax()]
return answer['챗봇']
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch(debug=True, share=True)
import gradio as gr
def greet(user, history=[]):
embedding = encoder.encode(user)
df['distance'] = df['embedding'].map(lambda x: cosine_similarity([embedding], [x]).squeeze())
answer = df.loc[df['distance'].idxmax()]
history.append([user, answer['챗봇']])
return history, history
demo = gr.Interface(fn=greet, inputs=["text", "state"], outputs=["chatbot", "state"])
demo.launch(debug=True, share=True)
import gradio as gr
def greet(user, history=[]):
embedding = encoder.encode(user)
df['distance'] = df['embedding'].map(lambda x: cosine_similarity([embedding], [x]).squeeze())
answer = df.loc[df['distance'].idxmax()]
history.append([user, answer['챗봇']])
return history, history
demo = gr.Interface(fn=greet, inputs=["text", "state"], outputs=["chatbot", "state"])
demo.launch(debug=True, share=True)